在 SQL Server 大数据群集 上创建和导出 Spark 机器学习模型并对其评分
重要
Microsoft SQL Server 2019 大数据群集附加产品将停用。 对 SQL Server 2019 大数据群集的支持将于 2025 年 2 月 28 日结束。 具有软件保障的 SQL Server 2019 的所有现有用户都将在平台上获得完全支持,在此之前,该软件将继续通过 SQL Server 累积更新进行维护。 有关详细信息,请参阅公告博客文章和 Microsoft SQL Server 平台上的大数据选项。
以下示例演示如何使用 Spark ML 生成模型,将模型导出到 MLeap,以及在 SQL Server 中使用其 Java 语言扩展对模型进行评分。 这是在 SQL Server 大数据群集的上下文中完成的。
下图说明了此示例中执行的工作:
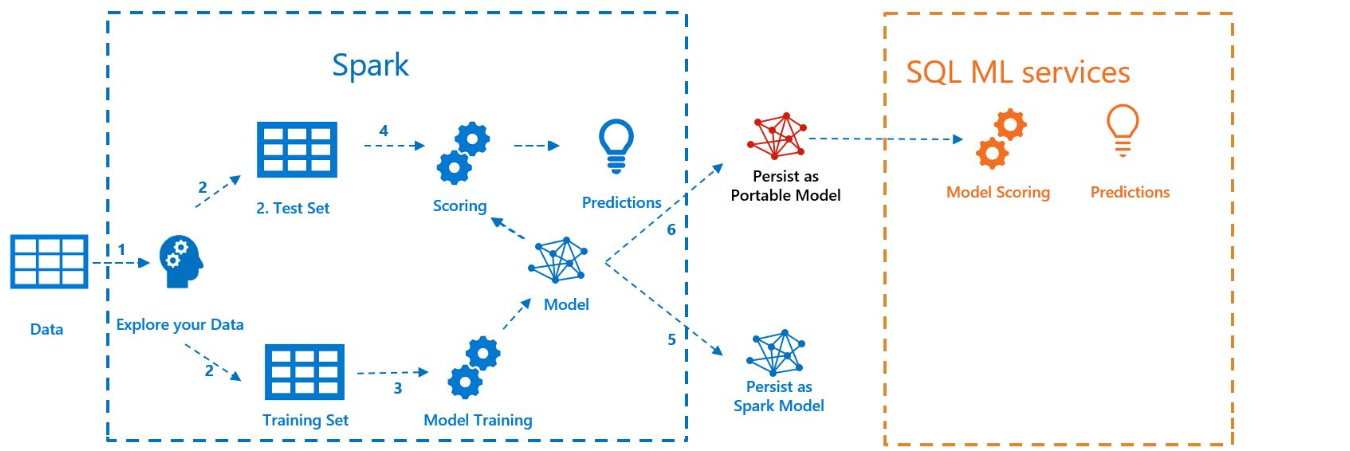
先决条件
此示例的所有文件均位于 https://github.com/microsoft/sql-server-samples/tree/master/samples/features/sql-big-data-cluster/spark/sparkml 中。
若要运行该示例,还必须具有以下系统必备组件:
-
- kubectl
- curl
- Azure Data Studio
使用 Spark ML 进行模型训练
在此示例中,人口普查数据 (AdultCensusIncome.csv) 用于生成 Spark ML 管道模型。
使用 mleap_sql_test/setup.sh 文件从 Internet 下载数据集,并将其放在 SQL Server 大数据群集的 HDFS 上。 这可让 Spark 访问它。
然后下载示例笔记本 train_score_export_ml_models_with_spark.ipynb。 从 PowerShell 或 bash 命令行运行以下命令,以下载该笔记本:
curl -o mssql_spark_connector.ipynb "https://raw.githubusercontent.com/microsoft/sql-server-samples/master/samples/features/sql-big-data-cluster/spark/sparkml/train_score_export_ml_models_with_spark.ipynb"此笔记本包含具有此示例部分所需命令的单元格。
在 Azure Data Studio 中打开笔记本,然后运行每个代码块。 有关使用笔记本的详细信息,请参阅如何在 SQL Server 中使用笔记本。
数据会先读入 Spark 并拆分成训练和测试数据集。 然后,代码使用训练数据训练管道模型。 最后,它将模型导出为 MLeap 捆绑包。
提示
还可以在 mleap_sql_test/mleap_pyspark.py 文件中的笔记本外部查看或运行与这些步骤关联的 Python 代码。
使用 SQL Server 进行模型评分
由于 Spark ML 管道模型采用常见的序列化 MLeap 捆绑包格式,因此可以在没有 Spark 的情况下,在 Java 中对模型进行评分。
此示例使用 SQL Server 中的 Java 语言扩展。 若要在 SQL Server 中对模型进行评分,首先需要生成一个可以将模型加载到 Java 中并对其进行评分的 Java 应用程序。 可以在 mssql-mleap-app 文件夹中找到此 Java 应用程序的示例代码。
生成示例后,可以使用 Transact-SQL 调用 Java 应用程序,并使用数据库表对模型进行评分。 这可以在 mleap_sql_test/mleap_sql_tests.py 源文件中看到。
后续步骤
有关大数据群集的详细信息,请参阅如何在 Kubernetes 部署 SQL Server 大数据群集