适用于:![]() SQL Server
SQL Server
Always On 可用性组的性能方面对维护任务关键型数据库的服务级别协议 (SLA) 至关重要。 了解可用性组如何将日志传送到次要副本有助于估计可用性实现的恢复时间目标 (RTO) 和恢复点目标 (RPO),并识别执行效果不佳的可用性组或副本中的瓶颈。 本文介绍同步过程,演示如何计算一些关键指标,并提供一些常见性能故障排除方案的链接。
数据同步过程
若要估计完全同步的时间并识别瓶颈,需要了解同步过程。 性能瓶颈可能出现在过程中的任何位置,查找瓶颈有助于更深入发掘潜在的问题。 下图和下表说明了数据同步过程:

| 序列 | 步骤说明 | 注释 | 有用的指标 |
|---|---|---|---|
| 1 | 日志生成 | 日志数据已刷新到磁盘。 必须将此日志复制到次要副本。 日志记录会进入发送队列。 | SQL Server:数据库 > 日志字节每秒清空 |
| 2 | 捕获 | 捕获每个数据库的日志并将其发送到对应的配对队列(每个数据库-副本对对应一个)。 只要可用性副本已连接、数据移动没有因任何原因暂停,且数据库副本对显示为正在同步或已同步,此捕获进程就会持续运行。 如果捕获进程无法足够快地扫描并排队消息,日志发送队列会积压。 |
SQL Server:可用性副本 > 每秒发送到副本的字节数,是为该可用性副本排队的所有数据库消息的总计。 主要副本上的 log_send_queue_size (KB) 和 log_bytes_send_rate(KB/秒)。 |
| 3 | Send | 每个数据库副本队列中的消息都会出列,并通过线路发送到相应的次要副本。 | SQL Server:可用性副本> 每秒发送至传输的字节数 |
| 4 | 接收和缓存 | 每个辅助副本都会接收并缓存消息。 | 性能计数器 SQL Server:Availability Replica > Log Bytes Received/sec |
| 5 | 强化 | 在次要副本上刷新日志以进行强化。 日志刷新后,系统会将确认消息发送回主要副本。 强化日志后,即可避免数据丢失。 |
性能计数器 SQL Server:Database > Log Bytes Flushed/sec 等待类型 HADR_LOGCAPTURE_SYNC |
| 6 | 重做 | 重做次要副本上的刷新页面。 页面在等待重做时会保留在重做队列中。 |
SQL Server:Database Replica > Redone Bytes/sec redo_queue_size (KB) 和 redo_rate。 等待类型 REDO_SYNC |
流控制门
可用性组在主要副本上设计有流控制门,可避免所有可用性副本上的资源(例如网络和内存资源)过度消耗。 这些流控制门不会影响可用性副本的同步运行状况状态,但它们可能会影响可用性数据库(包括 RPO)的整体性能。
在主要副本上捕获日志后,它们会受制于两个级别的流控制。 达到任一门的消息阈值后,则不再向特定副本或为特定数据库发送消息日志。 接收到已发送消息的确认消息,以使发送的消息数量低于阈值后,便可以发送消息了。
除了流控制门外,还有另一个因素可以阻止发送日志消息。 副本同步可确保按日志序列号 (LSN) 的顺序来发送和应用消息。 在发送日志消息之前,其 LSN 还会根据已确认的最低 LSN 编号进行检查,以确保它小于阈值之一(具体取决于消息类型)。 如果两个 LSN 数字之间的差距大于阈值,则不会发送消息。 差距再次低于阈值后,则会发送消息。
SQL Server 2022(16.x)增加了每个门允许的消息数的限制。 从以下版本开始,在 启动时 使用跟踪标志 12310 来增加限制:SQL Server 2019 (15.x) CU9、SQL Server 2017 (14.x) CU18 和 SQL Server 2016 (13.x) SP1 CU16。 此跟踪标志不能与DBCC TRACEON一起使用。
下表比较了消息限制:
对于启用跟踪标志 12310 的 SQL Server 版本(即 SQL Server 2022 (16.x)、SQL Server 2019 (15.x) CU9、SQL Server 2017 (14.x) CU18、SQL Server 2016 (13.x) SP1 CU16 及更高版本,请参阅以下限制:
| 级别 | 门数 | 消息数量 | 有用的指标 |
|---|---|---|---|
| 传输 | 每个可用性副本 1 个 | 16384 | 扩展事件 database_transport_flow_control_action |
| 数据库 | 每个可用性数据库 1 个 | 7168 |
DBMIRROR_SEND 扩展事件 hadron_database_flow_control_action |
两个有用的性能计数器,即 SQL Server:Availability Replica > Flow control/sec 和 SQL Server:Availability Replica > Flow Control Time (ms/sec),会在最后一秒钟内显示激活流控制的次数以及等待流控制所花费的时间。 流控制的等待时间越长,转换的 RPO 越高。 有关可能导致流量控制等待时间过长的问题类型的详细信息,请参阅 故障排除:使用异步提交的可用性组副本时的潜在数据丢失。
估计故障转移时间(RTO)
SLA 中的 RTO 取决于 Always On 实现在任何给定时间的故障转移时间,可使用以下公式表示:

重要
如果可用性组包含多个可用性数据库,则具有最高 Tfailover 的可用性数据库会成为 RTO 符合性的限制值。
故障检测时间(即 Tdetection)是系统检测到故障所用的时间。 此时间取决于群集级别设置,而不是各个可用性副本。 根据配置的自动故障转移条件,可触发故障转移,作为对关键 SQL Server 内部错误(如孤立的自旋锁)的即时反应。 在这种情况下,检测速度可以和 将sp_server_diagnostics 错误报告发送到 Windows Server 故障转移群集(WSFC)一样快。 默认间隔为运行状况检查超时的 1/3。故障转移也可能因为超时而触发,例如群集运行状况检查超时已过期(默认为 30 秒),或者资源 DLL 与 SQL Server 实例之间的租约已过期(默认为 20 秒)。 在这种情况下,检测时间与超时间隔一样长。 有关详细信息,请参阅针对可用性组的自动故障转移的灵活的故障转移策略 (SQL Server)。
如果准备进行故障转移,次要副本唯一需要做的是让重做赶上日志的末尾。 重做时间(即 Tredo)使用以下公式进行计算:
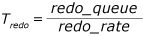
其中,redo_queue 是 redo_queue_size 中的值,redo_rate 是 redo_rate 中的值 。
故障转移系统开销时间(即 Toverhead)包括对 WSFC 群集进行故障转移和将数据库联机所用的时间。 此时间通常较短且比较固定。
估计潜在的数据丢失(RPO)
SLA 中的 RPO 取决于 Always On 实现在任何给定时间可能的数据丢失。 此可能的数据丢失可以使用以下公式进行表示:
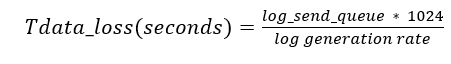
其中,log_send_queue 是 log_send_queue_size 的值,日志生成速率是 SQL Server:Database Log Bytes Flushed/sec 的值。
警告
如果可用性组包含多个可用性数据库,则具有最高 Tdata_loss 的可用性数据库会成为 RPO 符合性的限制值。
日志发送队列表示可能因灾难性故障而丢失的所有数据。 首先,使用日志生成速率而不是日志发送速率(请参阅 log_send_rate),这很奇怪。 但是,请记住,使用日志发送速率只能提供同步所需的时间,而 RPO 是根据数据生成的速度来度量数据丢失,而不是根据同步的速度来衡量。
估计 Tdata_loss 更为简单的方法是使用 last_commit_time。 主要副本上的 DMV 会为所有副本报告此值。 可以计算主要副本的值与次要副本的值之间的差值,从而估计次要副本上的日志追赶主要副本的速度。 如前所述,此计算不会根据日志的生成速度告诉你潜在的数据丢失,但它应该是接近的近似值。
使用 SSMS 仪表板估算 RTO 和 RPO
在始终在线可用性组中,计算 RTO 和 RPO,并为辅助副本上托管的数据库显示这些值。 在 SQL Server 管理工具(SSMS)仪表板中,主副本上的 RTO 和 RPO 被次要副本分组。
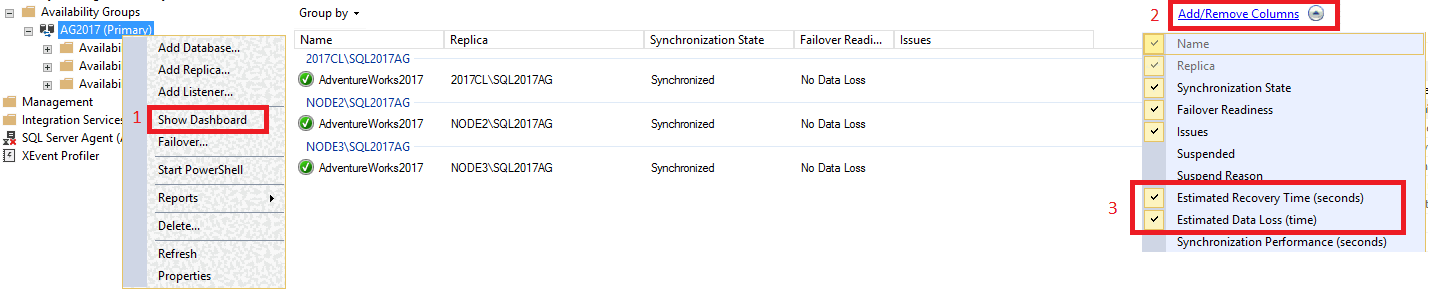
若要查看仪表板中的 RTO 和 RPO,请执行以下步骤:
在 SQL Server Management Studio 中,展开 “Always On 高可用性”节点,右键单击可用性组的名称,然后选择“显示仪表板” 。
从“分组依据”选项卡下,选择“添加/删除列” 。选中“估计恢复时间(秒)”[RTO] 和“估计的数据丢失(时间)”[RPO] 。

辅助数据库 RTO 计算
恢复时间计算用于确定在发生故障转移后恢复辅助数据库所需的时间 。 故障转移时间通常较短且比较固定。 检测时间取决于群集级别设置,而不是各个可用性副本。
对于辅助数据库(DB_sec),其 RTO 的计算和显示基于其 redo_queue_size 和 redo_rate:
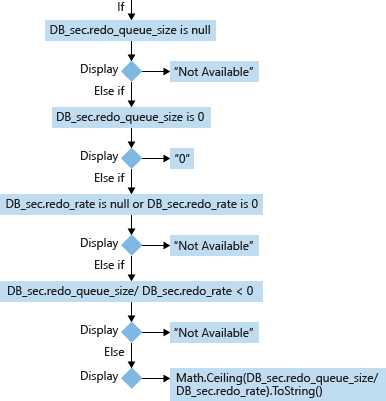
除极端情况外,辅助数据库 RTO 的计算公式是:

辅助数据库 RPO 计算
对于辅助数据库(DB_sec),其 RPO 的计算和显示基于其is_failover_readylast_commit_time及其相关主数据库(DB_pri)last_commit_time的值。 当 DB_sec.is_failover_ready 的值为 1 时,主数据库与辅助数据库之间的数据会同步,故障转移时不会发生数据丢失。 但是,如果此值为0,则主数据库中的last_commit_time与辅助数据库中的last_commit_time之间存在差距。
对于主数据库,last_commit_time 是最近一次事务提交的时间。 **
对于辅助数据库,last_commit_time 是来自主数据库的事务在辅助数据库中也已成功持久化后的最新提交时间。 对于主数据库和辅助数据库,此数字相同。 这两个值之间的间隔是挂起事务尚未在辅助数据库上被巩固的时间段,在发生故障切换时可能会丢失。

RTO/RPO 公式中使用的性能指标
redo_queue_size(KB):RTO 中使用的重做队列大小是其last_received_lsn与last_redone_lsnRTO 之间的事务日志大小。 该值last_received_lsn是日志块标识符,用于标识所有日志块已被用于承载数据库的辅助副本接收到的点。last_redone_lsn值为辅助数据库上重做的最后一条日志记录的日志序列号。 根据这两个值,可以找到起始日志块(last_received_lsn)和结束日志块(last_redone_lsn)的 ID。 然后,这两个日志块之间的空间可以表示尚未重做多少个事务日志块。 以千字节 (KB) 为单位。redo_rate(KB/秒):用于 RTO 计算,这是一个累积值,显示每秒在次级数据库上重做或重播的事务日志(KB)的数量。last_commit_time(datetime):在 RPO 中使用,此值在主数据库和辅助数据库之间具有不同的含义。 对于主数据库,last_commit_time是提交最新事务的时间。 对于辅助数据库,last_commit_time是主数据库的事务中最新提交的,也是已经在辅助数据库上成功强化的。 由于辅助设备上的此值应与主设备上的相同值同步,因此这两个值之间的任何差异都是数据丢失 (RPO) 的估计值。
使用 DMV 估计 RTO 和 RPO
可以查询 DMV sys.dm_hadr_database_replica_states 和 sys.dm_hadr_database_replica_cluster_states 来估计数据库的 RPO 和 RTO。 以下查询创建完成这两项任务的存储过程。
注意
确保创建并运行存储过程以首先估计 RTO,因为运行存储过程来估计 RPO 需要前者生成的值。
创建存储过程以估计 RTO
在目标次要副本上,创建存储过程
proc_calculate_RTO。 如果此存储过程已存在,请先将其删除,然后重新创建它。IF object_id(N'proc_calculate_RTO', 'p') IS NOT NULL DROP PROCEDURE proc_calculate_RTO; GO RAISERROR ('creating procedure proc_calculate_RTO', 0, 1) WITH NOWAIT; GO -- name: proc_calculate_RTO -- -- description: Calculate RTO of a secondary database. -- -- parameters: @secondary_database_name nvarchar(max): name of the secondary database. -- -- security: this is a public interface object. -- CREATE PROCEDURE proc_calculate_RTO @secondary_database_name NVARCHAR (MAX) AS BEGIN DECLARE @db AS sysname; DECLARE @is_primary_replica AS BIT; DECLARE @is_failover_ready AS BIT; DECLARE @redo_queue_size AS BIGINT; DECLARE @redo_rate AS BIGINT; DECLARE @replica_id AS UNIQUEIDENTIFIER; DECLARE @group_database_id AS UNIQUEIDENTIFIER; DECLARE @group_id AS UNIQUEIDENTIFIER; DECLARE @RTO AS FLOAT; SELECT @is_primary_replica = dbr.is_primary_replica, @is_failover_ready = dbcs.is_failover_ready, @redo_queue_size = dbr.redo_queue_size, @redo_rate = dbr.redo_rate, @replica_id = dbr.replica_id, @group_database_id = dbr.group_database_id, @group_id = dbr.group_id FROM sys.dm_hadr_database_replica_states AS dbr INNER JOIN sys.dm_hadr_database_replica_cluster_states AS dbcs ON dbr.replica_id = dbcs.replica_id AND dbr.group_database_id = dbcs.group_database_id WHERE dbcs.database_name = @secondary_database_name; IF @is_primary_replica IS NULL OR @is_failover_ready IS NULL OR @redo_queue_size IS NULL OR @replica_id IS NULL OR @group_database_id IS NULL OR @group_id IS NULL BEGIN PRINT 'RTO of Database ' + @secondary_database_name + ' is not available'; RETURN; END ELSE IF @is_primary_replica = 1 BEGIN PRINT 'You are visiting wrong replica'; RETURN; END IF @redo_queue_size = 0 SET @RTO = 0; ELSE IF @redo_rate IS NULL OR @redo_rate = 0 BEGIN PRINT 'RTO of Database ' + @secondary_database_name + ' is not available'; RETURN; END ELSE SET @RTO = CAST (@redo_queue_size AS FLOAT) / @redo_rate; PRINT 'RTO of Database ' + @secondary_database_name + ' is ' + CONVERT (VARCHAR, ceiling(@RTO)); PRINT 'group_id of Database ' + @secondary_database_name + ' is ' + CONVERT (NVARCHAR (50), @group_id); PRINT 'replica_id of Database ' + @secondary_database_name + ' is ' + CONVERT (NVARCHAR (50), @replica_id); PRINT 'group_database_id of Database ' + @secondary_database_name + ' is ' + CONVERT (NVARCHAR (50), @group_database_id); END运行带有目标辅助数据库名称的
proc_calculate_RTO:EXECUTE proc_calculate_RTO @secondary_database_name = N'DB_sec';输出显示目标次要副本数据库的 RTO 值。 保存 group_id、replica_id 和 group_database_id,用于与 RPO 估计存储过程配合使用 。
示例输出:
RTO of Database DB_sec' is 0 group_id of Database DB4 is F176DD65-C3EE-4240-BA23-EA615F965C9B replica_id of Database DB4 is 405554F6-3FDC-4593-A650-2067F5FABFFD group_database_id of Database DB4 is 39F7942F-7B5E-42C5-977D-02E7FFA6C392
创建存储过程以估计 RPO
在主副本上,创建存储过程
proc_calculate_RPO。 如果已存在,请先将其删除,然后重新创建它。IF object_id(N'proc_calculate_RPO', 'p') IS NOT NULL DROP PROCEDURE proc_calculate_RPO; GO RAISERROR ('creating procedure proc_calculate_RPO', 0, 1) WITH NOWAIT; GO -- name: proc_calculate_RPO -- -- description: Calculate RPO of a secondary database. -- -- parameters: @group_id uniqueidentifier: group_id of the secondary database. -- @replica_id uniqueidentifier: replica_id of the secondary database. -- @group_database_id uniqueidentifier: group_database_id of the secondary database. -- -- security: this is a public interface object. -- CREATE PROCEDURE proc_calculate_RPO @group_id UNIQUEIDENTIFIER, @replica_id UNIQUEIDENTIFIER, @group_database_id UNIQUEIDENTIFIER AS BEGIN DECLARE @db_name AS sysname; DECLARE @is_primary_replica AS BIT; DECLARE @is_failover_ready AS BIT; DECLARE @is_local AS BIT; DECLARE @last_commit_time_sec AS DATETIME; DECLARE @last_commit_time_pri AS DATETIME; DECLARE @RPO AS NVARCHAR (MAX); SELECT @db_name = dbcs.database_name, @is_failover_ready = dbcs.is_failover_ready, @last_commit_time_sec = dbr.last_commit_time FROM sys.dm_hadr_database_replica_states AS dbr INNER JOIN sys.dm_hadr_database_replica_cluster_states AS dbcs ON dbr.replica_id = dbcs.replica_id AND dbr.group_database_id = dbcs.group_database_id WHERE dbr.group_id = @group_id AND dbr.replica_id = @replica_id AND dbr.group_database_id = @group_database_id; SELECT @last_commit_time_pri = dbr.last_commit_time, @is_local = dbr.is_local FROM sys.dm_hadr_database_replica_states AS dbr INNER JOIN sys.dm_hadr_database_replica_cluster_states AS dbcs ON dbr.replica_id = dbcs.replica_id AND dbr.group_database_id = dbcs.group_database_id WHERE dbr.group_id = @group_id AND dbr.is_primary_replica = 1 AND dbr.group_database_id = @group_database_id; IF @is_local IS NULL OR @is_failover_ready IS NULL BEGIN PRINT 'RPO of database ' + @db_name + ' is not available'; RETURN; END IF @is_local = 0 BEGIN PRINT 'You are visiting wrong replica'; RETURN; END IF @is_failover_ready = 1 SET @RPO = '00:00:00'; ELSE IF @last_commit_time_sec IS NULL OR @last_commit_time_pri IS NULL BEGIN PRINT 'RPO of database ' + @db_name + ' is not available'; RETURN; END ELSE BEGIN IF DATEDIFF(ss, @last_commit_time_sec, @last_commit_time_pri) < 0 BEGIN PRINT 'RPO of database ' + @db_name + ' is not available'; RETURN; END ELSE SET @RPO = CONVERT (VARCHAR, DATEADD(ms, datediff(ss, @last_commit_time_sec, @last_commit_time_pri) * 1000, 0), 114); END PRINT 'RPO of database ' + @db_name + ' is ' + @RPO; END -- secondary database's last_commit_time -- correlated primary database's last_commit_time使用目标辅助数据库的
proc_calculate_RPO、replica_id和group_database_id执行。EXECUTE proc_calculate_RPO @group_id = 'F176DD65-C3EE-4240-BA23-EA615F965C9B', @replica_id = '405554F6-3FDC-4593-A650-2067F5FABFFD', @group_database_id = '39F7942F-7B5E-42C5-977D-02E7FFA6C392';输出显示目标次要副本数据库的 RPO 值。
监视 RTO 和 RPO
本部分演示如何监视可用性组的 RTO 和 RPO 指标。 此演示类似于 The Always On health model, part 2:Extending the health model(Always On 运行状况模型,第 2 部分:扩展运行状况模型)。
在 估计故障转移时间(RTO) 和 估计潜在数据丢失(RPO) 中,故障转移时间和潜在数据丢失计算的元素作为策略管理方面 数据库副本状态中的性能指标提供方便。 有关详细信息,请参阅 在 SQL Server 对象上查看基于策略的管理方面。 可以按计划监视这两个指标,并在指标分别超过 RTO 和 RPO 时发出警报。
演示的脚本创建了两个系统策略,它们按各自计划运行,并具有以下特征:
估计的故障转移时间超过 10 分钟时,RTO 策略会失败,每 5 分钟评估一次
估计的数据丢失超过 1 小时时,RPO 策略会失败,每 30 分钟评估一次
两个策略在所有可用性副本上的配置相同
所有服务器上都将评估策略,但仅在本地可用性副本是主要副本的可用性组上进行评估。 如果本地可用性复制体不是主要复制体,则不会评估策略。
在主要副本上查看时,Always On 仪表板中可以很方便地显示策略失败情况。
若要创建策略,请在参与可用性组的所有服务器实例上按照以下说明作:
启动 SQL Server 代理服务(如果尚未启动)。
在 SQL Server Management Studio 的 “工具” 菜单中,选择“ 选项”。
在 “SQL Server Always On ”选项卡中,选择“ 启用用户定义的 Always On 策略 ”,然后选择“ 确定”。
通过此设置,可在 Always On 仪表板中显示正确配置的自定义策略。
使用以下规范创建基于策略的管理条件:
-
名称:
RTO - Facet:数据库副本状态
-
字段:
Add(@EstimatedRecoveryTime, 60) - 运算符:
-
值:
600
如果潜在的故障转移时间超过 10 分钟,包括故障检测和故障转移的 60 秒额外时间,则此条件将失败。
-
名称:
使用以下规范创建第二个基于策略的管理条件:
-
名称:
RPO - Facet:数据库副本状态
-
字段:
@EstimatedDataLoss - 运算符:
-
值:
3600
如果可能的数据丢失超过 1 小时,则此条件会失败。
-
名称:
使用以下规范创建第三个基于策略的管理条件:
-
名称:
IsPrimaryReplica - Facet:可用性组
-
字段:
@LocalReplicaRole - 运算符:=
-
值:
Primary
此条件会检查给定的可用性组的本地可用性副本是否为主要副本。
-
名称:
使用以下规范创建基于策略的管理策略:
“常规”页 :
名称:
CustomSecondaryDatabaseRTO检查条件:
RTO针对目标:IsPrimaryReplica AvailabilityGroup 中的每个 DatabaseReplicaState
此设置确保仅在本地可用性副本是其主要副本的可用性组上对策略进行评估。
评估模式:按计划
计划:CollectorSchedule_Every_5min
已启用:已选中
“说明”页 :
类别:可用性数据库警告
通过此设置,策略评估结果可显示在 Always On 仪表板中。
说明:当前副本的 RTO 超过 10 分钟,假定发现和故障转移的开销为 1 分钟。 应立即调查相应服务器实例上的性能问题。
要显示的文本:超过了 RTO!
使用以下规范创建第二个基于策略的管理策略:
“常规”页 :
-
名称:
CustomAvailabilityDatabaseRPO -
检查条件:
RPO - 针对目标:IsPrimaryReplica AvailabilityGroup 中的每个 DatabaseReplicaState
- 评估模式:按计划
- 计划:CollectorSchedule_Every_30min
- 已启用:已选中
-
名称:
“说明”页 :
类别:可用性数据库警告
说明:可用性数据库已超过时间为 1 小时的 RPO。 应立即调查可用性副本上的性能问题。
要显示的文本:超过了 RPO!
完成后,会创建两个新的 SQL Server 代理作业,为每个策略评估计划各创建一个。 这些作业应具有以 syspolicy_check_schedule开头的名称。
可以查看作业历史记录,以检查评估结果。 评估失败情况还记录在事件为 ID 34052 的 Windows 应用程序日志中(事件查看器中)。 还可以配置 SQL Server 代理以发送有关策略失败的警报。 有关详细信息,请参阅 配置警报以通知策略管理员策略失败。
性能故障排除方案
下表列出了常见的与性能相关的故障排除方案。
| 场景 | 说明 |
|---|---|
| 故障排除:可用性组超过了 RTO | 进行自动故障转移或计划的手动故障转移(无数据丢失)后,故障转移时间超过 RTO。 或者,在估计同步提交次要副本(如自动故障转移伙伴)的故障转移时间时,发现该时间超过 RTO。 |
| 故障排除:可用性组超过了 RPO | 执行强制手动故障转移后,数据丢失超过 RPO。 或者,在计算异步提交次要副本可能丢失的数据时,发现它超过了 RPO。 |
| 故障排除:主要副本的更改未反映在次要副本上 | 客户端应用程序成功完成对主副本的更新,但查询次要副本会显示更改未反映。 |
有用的扩展事件
在对“正在同步”状态下的副本进行故障排除时,以下扩展事件很有用 。
| 事件名称 | 类别 | Channel | 可用性副本 |
|---|---|---|---|
redo_caught_up |
事务 | 调试 | 辅助副本 |
redo_worker_entry |
事务 | 调试 | 辅助副本 |
hadr_transport_dump_message |
alwayson |
调试 | 主 |
hadr_worker_pool_task |
alwayson |
调试 | 主 |
hadr_dump_primary_progress |
alwayson |
调试 | 主 |
hadr_dump_log_progress |
alwayson |
调试 | 主 |
hadr_undo_of_redo_log_scan |
alwayson |
分析 | 辅助副本 |