适用于:![]() SQL Server 2017 (14.x) 及更高版本
SQL Server 2017 (14.x) 及更高版本
本文介绍用于运行外部 Python 脚本(使用 SQL Server 机器学习服务)的 Python 扩展。 该扩展插件添加了:
- Python 执行环境
- 包含 Python 3.5 运行时和解释器的 Anaconda 分发
- 标准库和工具
- Microsoft Python 包:
- 用于大规模分析的 revoscalepy。
- 用于机器学习算法的 microsoftml。
安装 Python 3.5 运行时和解释器可确保与标准 Python 解决方案近乎完全兼容。 Python 与 SQL Server 在不同的进程中运行,以保证数据库操作不受到影响。
Python 组件
SQL Server 包含开源包和专有包。 安装程序安装的 Python 运行时为带 Python 3.5 的 Anaconda 4.2。 Python 运行时的安装独立于 SQL 工具,并在扩展性框架中于核心引擎进程之外执行。 在使用 Python 安装机器学习服务的过程中,必须同意 GNU 公共许可证的条款。
SQL Server 不会修改基本 Python 可执行文件,但必须使用安装程序安装的 Python 版本,因为该版本是用于生成和测试专有包的版本。 有关 Anaconda 发行版支持的包的列表,请参阅 Continuum 分析网站:Anaconda 包列表。
与特定数据库引擎实例关联的 Anaconda 发行版可在与实例关联的文件夹中找到。 例如,如果在默认实例上安装了带机器学习服务和 Python 的 SQL Server 2017 数据库引擎,请查看 C:\Program Files\Microsoft SQL Server\MSSQL14.MSSQLSERVER\PYTHON_SERVICES。
Microsoft 为并行和分布式工作负荷添加的 Python 包包含以下库。
| 程序库 | 说明 |
|---|---|
| revoscalepy | 支持数据源对象以及数据浏览、操作、转换和可视化。 它支持创建远程计算上下文以及各种可缩放的机器学习模型,例如 rxLinMod。 有关详细信息,请参阅 适用于 SQL Server 的 revoscalepy 模块。 |
| microsoftml | 包含针对速度和准确性进行了优化的机器学习算法,以及用于处理文本和图像的内联转换。 有关详细信息,请参阅《SQL Server 的 microsoftml 模块》。 |
Microsoftml 和 revoscalepy 紧密耦合;microsoftml 中使用的数据源定义为 revoscalepy 对象。 Revoscalepy 中的计算上下文限制传递到 microsoftml。 即,所有功能都可用于本地操作,但切换到远程计算上下文需要 RxInSqlServer。
在 SQL Server 中使用 Python
将 revoscalepy 模块导入 Python 代码中,然后从该模块调用函数,就像调用任何其他 Python 函数一样。
支持的数据源包括 ODBC 数据库、SQL Server 和用于与其他源或通过 R 解决方案交换数据的 XDF 文件格式。 Python 的输入数据必须为表格格式。 所有 Python 结果都必须以 pandas 数据帧的形式返回。
支持的计算上下文包括本地或远程 SQL Server 计算上下文。 远程计算环境指的是代码执行在一台计算机(例如工作站)上开始,但随后将脚本执行切换到远程计算机。 切换计算上下文要求两个系统安装相同版本的revoscalepy库。
正如用户所预期的一样,本地计算上下文包括在与数据库引擎实例相同的服务器上执行 Python 代码,以及 T-SQL 内部或嵌入存储过程的代码。 还可以通过定义远程计算上下文,从本地 Python IDE 运行代码并使脚本在 SQL Server 计算机上执行。
执行体系结构
以下关系图说明 SQL Server 组件与 Python 运行时在每种支持的方案中的交互:在数据库内运行脚本,以及使用 SQL Server 计算上下文从 Python 终端远程执行。
在数据库内执行 Python 脚本
在 SQL Server“内部”运行 Python 时,必须将 Python 脚本封装到特殊的存储过程 sp_execute_external_script 中。
在将脚本嵌入存储过程后,可以进行存储过程调用的任何应用程序都可以启动 Python 代码的执行。 然后,SQL Server 按下图中概括的方式管理代码执行。
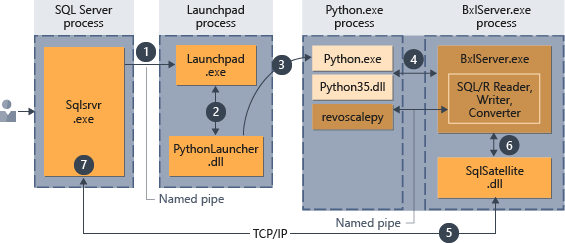
- 对 Python 运行时发出的请求由传递给存储过程的参数
@language='Python'指示。 SQL Server 将此请求发送到 Launchpad 服务。 在 Linux 中,SQL 使用 Launchpad 服务与每个用户的独立 Launchpad 进程进行通信。 有关详细信息,请参阅扩展性体系结构关系图。 - Launchpad 服务启动相应的启动器(在本例中为 PythonLauncher)。
- PythonLauncher 启动外部 Python35 进程。
- BxlServer 与 Python 运行时协同工作,管理数据交换并存储工作结果。
- SQL Satellite 管理相关任务和进程与 SQL Server 之间的通信。
- BxlServer 使用 SQL Satellite 向 SQL Server 传递状态和结果。
- SQL Server 获取结果并关闭相关任务和进程。
从远程客户端执行 Python 脚本
如果满足以下条件,则可以从远程计算机(例如笔记本电脑)运行 Python 脚本,并使它们在 SQL Server 计算机的上下文中执行:
- 应适当设计脚本
- 远程计算机已安装了机器学习服务使用的扩展性库。 使用远程计算上下文需要 revoscalepy 包。
以下关系图概括了从远程计算机发送脚本时的总体工作流。
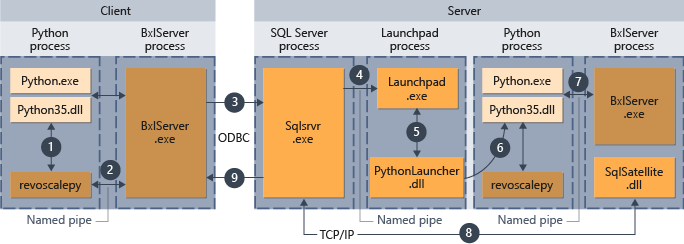
- 对于 revoscalepy 支持的函数,Python 运行时调用链接函数,后者接着调用 BxlServer。
- BxlServer 包含在机器学习服务(数据库内)中,与 Python 运行时在不同的进程中运行。
- BxlServer 确定连接目标并使用 ODBC 发起连接,传递 Python 脚本的连接字符串中提供的凭据。
- BxlServer 打开与 SQL Server 实例的连接。
- 如果调用外部脚本运行时,将调用 Launchpad 服务,这将启动相应的启动器:在本例中为 PythonLauncher.dll。 此后,处理 Python 代码的工作流与在 T-SQL 中从存储过程调用 Python 代码时工作流类似。
- PythonLauncher 调用 SQL Server 计算机上安装的 Python 实例。
- 将结果返回到 BxlServer。
- SQL Satellite 管理与 SQL Server 之间的通信并清理相关作业对象。
- SQL Server 将结果传回客户端。