内存优化表中的表和行大小
适用于:![]() SQL Server
SQL Server![]() Azure SQL 数据库
Azure SQL 数据库![]() Azure SQL 托管实例
Azure SQL 托管实例
在 SQL Server 2016 (13.x) 之前,内存优化表的行内数据大小不得长于 8,060 字节。 但是,从 SQL Server 2016 (13.x) 开始,在 Azure SQL 数据库中,可以创建具有多个大型列(例如,多个 varbinary(8000) 列)和 LOB 列(即 varbinary(max)、varchar(max) 和 nvarchar(max)))的内存优化表,并使用本机编译的 Transact-SQL (T-SQL) 模块和表类型对其进行操作。
不满足 8,060 字节行大小限制的列将被放在单独的内部表的行外。 每个行外列均具有相应的内部表,而后者拥有单个非聚集索引。 有关用于行外列的内部表的详细信息,请参阅 sys.memory_optimized_tables_internal_attributes。
在某些情况下,计算行和表的大小十分有用:
表使用的内存量。
表使用的内存量无法精确计算。 有很多因素影响使用的内存量。 例如基于页的内存分配、位置、缓存和填充等因素。 还有具有活动事务关联或等待垃圾收集的多个行版本。
表中数据和索引所需的最小大小由本文后面讨论的
<table size>计算给定。计算内存使用量最好也不过是个近似值,建议你将容量规划包含在部署计划中。
行的数据大小是多少,是否满足 8,060 字节行大小限制? 要回答这些问题,请使用本文后面讨论的
<row body size>的计算。
内存优化表由行和索引的集合组成,其中包含行的指针。 下图是一个包含索引和行的表,因而也就有行标题和正文:
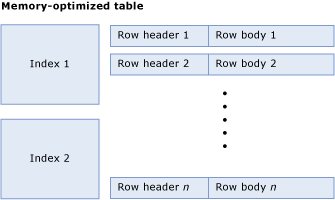
计算表的大小
内存中的表大小(以字节为单位)计算如下:
<table size> = <size of index 1> + ... + <size of index n> + (<row size> * <row count>)
哈希索引的大小是在表创建时固定下来的,取决于实际 Bucket 计数。 用索引定义指定的 bucket_count 舍入为最近的 2 的幂以获取实际 Bucket 计数。 例如,如果指定的 bucket_count 为 100000,则索引的实际桶计数为 131072。
<hash index size> = 8 * <actual bucket count>
非聚集索引的大小按照 <row count> * <index key size>顺序排列。
行大小是通过添加标题和正文计算的:
<row size> = <row header size> + <actual row body size>
<row header size> = 24 + 8 * <number of indexes>
计算行正文的大小
内存优化表中的行包含以下组成部分:
行标题,包含实现行版本控制所必需的时间戳。 此外,行标题还包含索引指针,以实现哈希 Bucket 中的行链(如前面所述)。
行正文,包含实际的列数据,其中包括一些辅助信息,如用于可为 Null 的列的 Null 数组,用于变长数据类型的偏移数组等。
下图展示拥有两个索引的表的行结构:

开始和结束时间戳指示特定行版本的有效时长。 在该时间间隔启动的事务可看到该行版本。 有关详细信息,请参阅具有内存优化表的事务。
索引指针,指向链中属于该哈希 Bucket 的下行。 下图展示一个表结构,其拥有两列(姓名,城市)、两个索引(一个针对姓名列、一个针对城市列)。
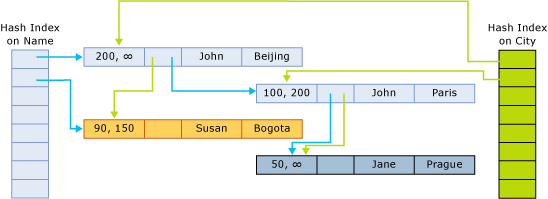
在该图中,姓名 John 和 Jane 经哈希处理放入第一个桶。 Susan 经哈希处理放入第二个桶。 城市 Beijing 和 Bogota 经哈希处理放入第一个桶。 Paris 和 Prague 经哈希处理放入第二个桶。
因此,针对姓名的哈希索引的链如下所示:
- 第一个桶:
(John, Beijing)、(John, Paris)、(Jane, Prague) - 第二个桶:
(Susan, Bogota)
针对城市的索引的链如下所示:
- 第一个桶:
(John, Beijing)、(Susan, Bogota) - 第二个桶:
(John, Paris)、(Jane, Prague)
结束时间戳 ∞(无限制)指示此为当前有效的行版本。 该行自该行版本写入以来未更新或删除。
对于大于 200 的时间,该表包含以下行:
| 名称 | City |
|---|---|
| John | 北京 |
| Jane | Prague |
但是,开始时间为 100 的任意活动事务都将看到该表的以下版本:
| 名称 | City |
|---|---|
| John | 巴黎 |
| Jane | Prague |
| Susan | 波哥大 |
<row body size> 的计算在下表中讨论。
对于行正文大小,有两种不同的计算:计算大小和实际大小。
计算大小表示为 计算行正文大小,用于确定是否超出了 8,060 字节的行大小限制。
实际大小表示为 实际行正文大小,是行正文在内存和检查点文件中的实际存储大小。
计算行正文大小 和 实际行正文大小 的计算方式相似。 唯一的区别是 (n)varchar(i) 和 varbinary(i) 列大小的计算,如下表底部所示。 计算行正文大小使用声明的大小 i 作为列大小,而实际行正文大小使用实际数据大小。
下表描述了行正文大小的计算,以 <actual row body size> = SUM(<size of shallow types>) + 2 + 2 * <number of deep type columns> 表示。
| 部分 | 规模 | 评论 |
|---|---|---|
| 浅表类型列 | SUM(<size of shallow types>)。 各类型的大小(字节数)如下:bit: 1tinyint: 1smallint: 2int: 4real: 4smalldatetime: 4smallmoney: 4bigint: 8datetime: 8datetime2: 8float: 8money: 8numeric(精度 <= 18): 8time: 8numeric(精度 > 18): 16uniqueidentifier: 16 |
|
| 浅表列填充 | 可能的值为: 如果存在深表类型列并且浅表列的总数据大小是奇数,则为 1。否则为 0 |
深表类型为类型 (var)binary 和 (n)(var)char。 |
| 深表类型列的偏移数组 | 可能的值为: 如果没有深表类型列,则为 0否则为 2 + 2 * <number of deep type columns> |
深表类型为类型 (var)binary 和 (n)(var)char。 |
| Null 数组 | <number of nullable columns> / 8 舍入为完整字节。 |
数组每个可以为 Null 的列有 1 位。 这舍入为完整字节。 |
| Null 数组填充 | 可能的值为: 如果存在深表类型列并且 1 数组的大小为奇数字节,则为 NULL。否则为 0 |
深表类型为类型 (var)binary 和 (n)(var)char。 |
| 填充 | 如果没有深表类型列:0如果有深表类型列,则根据浅表列需要的最大对齐添加 0-7 个填充字节。 每个浅表列都需要与前面记录的大小相等的对齐,而 GUID 列需要 1(而不是 16)字节的对齐,数值列始终需要 8(而不是 16)字节的对齐。 所有浅表列间使用最大的对齐要求。 添加了 0-7 个字节,现在总大小(不带深表类型列)是所需对齐的数倍。 |
深表类型为类型 (var)binary 和 (n)(var)char。 |
| 固定长度的深表类型列 | SUM(<size of fixed length deep type columns>)各列大小如下: 对于 char(i) 和 binary(i),为 i。对于 nchar(i),为 2 * i |
固定长度深表类型列是类型为 char(i)、nchar(i) 或 binary(i) 的列。 |
| 可变长度深表类型列计算大小 | SUM(<computed size of variable length deep type columns>)各列的计算大小如下: 对于 varchar(i) 和 varbinary(i),为 i对于 nvarchar(i),为 2 * i |
此行仅适用于 计算行正文大小。 可变长度的深表类型列是类型为 varchar(i)、nvarchar(i) 或 varbinary(i) 的列。 计算大小由列的最大长度 ( i) 决定。 |
| 可变长度深表类型列实际大小 | SUM(<actual size of variable length deep type columns>)各列的实际大小如下: 对于 varchar(i) 为 n,其中 n 是列中存储的字符数。对于 nvarchar(i) 为 2 * n,其中 n 是列中存储的字符数。对于 varbinary(i) 为 n,其中 n 是列中存储的字节数。 |
此行仅适用于 实际行正文大小。 实际大小由相应行中各列存储的数据决定。 |
示例:表和行大小计算
对于哈希索引,实际 Bucket 计数舍入为最近的 2 次幂。 例如,如果指定的 bucket_count 为 100000,则索引的实际 bucket 计数为 131072。
考虑具有以下定义的 Orders 表:
CREATE TABLE dbo.Orders (
OrderID INT NOT NULL PRIMARY KEY NONCLUSTERED,
CustomerID INT NOT NULL INDEX IX_CustomerID HASH WITH (BUCKET_COUNT = 10000),
OrderDate DATETIME NOT NULL,
OrderDescription NVARCHAR(1000)
)
WITH (MEMORY_OPTIMIZED = ON);
GO
此表有一个哈希索引和一个非聚集索引(主键)。 它还有三个固定长度列和一个可变长度列,其中一列可以为 NULL (OrderDescription)。 我们假定 Orders 表有 8,379 行,OrderDescription 列值的平均长度为 78 个字符。
要确定表大小,首先需要确定索引大小。 两个索引的 bucket_count 都指定为 10000。 这舍入为最近的 2 次幂:16384。 因此,Orders 表的索引的总大小为:
8 * 16384 = 131072 bytes
其余为表数据大小,即:
<row size> * <row count> = <row size> * 8379
(示例表有 8,379 行。)现在,我们具有:
<row size> = <row header size> + <actual row body size>
<row header size> = 24 + 8 * <number of indices> = 24 + 8 * 1 = 32 bytes
接下来,我们来计算 <actual row body size>:
浅表类型列:
SUM(<size of shallow types>) = 4 <int> + 4 <int> + 8 <datetime> = 16因为总浅表列大小为偶数,所以浅表列填充为 0。
深表类型列的偏移数组:
2 + 2 * <number of deep type columns> = 2 + 2 * 1 = 4NULL数组 = 1NULL数组填充 = 1,因为NULL数组大小为奇数并且有深表类型列。填充
- 8 是最大对齐要求
- 目前大小为 16 + 0 + 4 + 1 + 1 = 22
- 最接近的 8 的倍数为 24
- 总填充为 24 – 22 = 2 字节
没有固定长度深表类型列(固定长度深表类型列:0)。
深表类型列的实际大小为 2 * 78 = 156。 单一深表类型列
OrderDescription具有类型nvarchar。
<actual row body size> = 24 + 156 = 180 bytes
完成计算:
<row size> = 32 + 180 = 212 bytes
<table size> = 8 * 16384 + 212 * 8379 = 131072 + 1776348 = 1907420
内存中的总表大小约为 2 MB。 这不包括内存分配引起的可能开销以及访问此表的事务所需的任何行版本控制。
实际分配的内存和此表及其索引使用的内存可以通过以下查询获得:
SELECT * FROM sys.dm_db_xtp_table_memory_stats
WHERE object_id = object_id('dbo.Orders');
行外列限制
在内存优化表中使用行外列的某些限制和注意事项按如下所示列出:
- 如果存储关于内存优化表的列存储索引,则所有列均必须适应行内。
- 所有索引键列均必须存储在行内。 如果索引键列不适应行内,则添加索引将失败。
- 更改具有行外列的内存优化表的注意事项。
- 对于 LOB,大小限制可反映基于磁盘的表格的 LOB(2 GB 的 LOB 值限制)。
- 为了获得最佳性能,建议应将大多数列调整在 8,060 字节内。
- 行外数据可能会导致内存和/或磁盘使用量过大。
相关内容
反馈
即将发布:在整个 2024 年,我们将逐步淘汰作为内容反馈机制的“GitHub 问题”,并将其取代为新的反馈系统。 有关详细信息,请参阅:https://aka.ms/ContentUserFeedback。
提交和查看相关反馈