练习 - 构建和训练神经网络
在本单元中,你将使用 Keras 构建和训练分析文本情绪的神经网络。 若要训练神经网络,你需要数据来对其进行训练。 你将使用 Keras 随附的 IMDB 电影评论情绪分类数据集,无需下载外部数据集。 IMDB 数据集包含 50,000 条电影评论,并且已分别对这些评论进行正面 (1) 或负面 (0) 的评分。 该数据集中的 25,000 条评论用于训练,另外 25,000 条评论用于测试。 这些评论中表达的情绪是神经网络分析呈现给它的文本并对这些文本的情绪进行评分的基础。
IMDB 数据集是 Keras 随附的多个有用数据集之一。 有关内置数据集的完整列表,请参阅 https://keras.io/datasets/.
将以下代码键入或粘贴到笔记本的第一个单元格中,然后单击“运行”按钮(或按 Shift+Enter)执行它,并在其下方添加新的单元格:
from keras.datasets import imdb top_words = 10000 (x_train, y_train), (x_test, y_test) = imdb.load_data(num_words=top_words)此代码加载 Keras 随附的 IMDB 数据集并创建字典,该字典将全部 50,000 条评论中的字词映射到整数,这些整数指示字词的相对出现频率。 每个字词都分配到一个唯一的整数。 最常见的字词分配到数字 1,第二常见的字词分配到数字 2,依此类推。
load_data还返回包含电影评论的一对元组(在本示例中为x_train和x_test),以及将这些评论分类为正面和负面的 1 和 0(y_train和y_test)。确认看到消息“正在使用 TensorFlow 后端”,此消息指示 Keras 正在使用 TensorFlow 作为其后端。
加载 IMDB 数据集
如果想让 Keras 使用 Microsoft Cognitive Toolkit(也称为 CNTK)作为其后端,可通过在笔记本开头添加几行代码来实现。 有关示例,请参阅 Azure Notebooks 中的 CNTK 和 Keras。
那么
load_data函数加载的具体内容是什么呢? 名为x_train的变量是一个包含 25,000 个列表的列表,每个列表代表一条电影评论。 (x_test也是一个包含代表 25,000 条评论的 25,000 个列表的列表。x_train将用于训练,而x_test将用于测试。)但是,内部列表(代表电影评论的列表)不包含字词;它们包含整数。 以下是 Keras 文档中的相关介绍: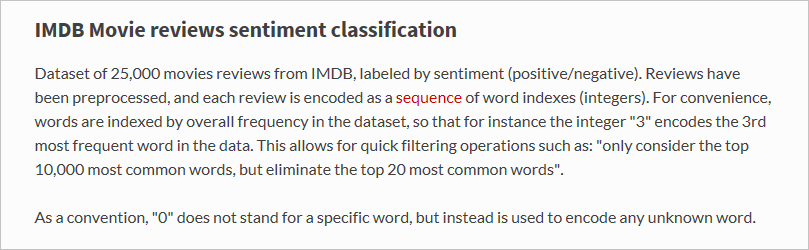
内部列表包含数字而不包含文本的原因在于,你不会使用文本训练神经网络;而是会使用数字训练它。 具体而言,你会使用张量对其进行训练。 在本示例中,每条评论都是一个一维张量(想象一下一维数组),其中包含标识评论中所含字词的整数。 若要演示,请将以下 Python 语句键入空单元格并执行它,以查看表示训练集中的第一条评论的整数:
x_train[0]
构成 IMDB 训练集中第一条评论的整数
列表中的第一个数字 (1) 不代表一个字词。 它标志着评论的开始,并且对于数据集中的每条评论都是如此。 数字 0 和 2 也被保留,并且你需要从其他数字中减去 3 以将评论中的整数映射到字典中的相应整数。 第二个数字 (14) 引用与字典中的数字 11 对应的字词,第三个数字表示在字典中分配到数字 19 的字词,依此类推。
想要看看字典是什么样子的? 在新的笔记本单元格中执行以下语句:
imdb.get_word_index()仅会显示字典条目的子集,但总体而言,字典包含超过 88,000 个字词以及与它们对应的整数。 你看到的输出可能与屏幕截图中的输出不匹配,因为每次调用
load_data都会重新生成字典。
映射字词到整数的字典
如你所见,数据集中的每条评论都编码为整数的集合,而不是字词的集合。 是否可能对评论进行反向编码,以便你可以查看构成评论的原始文本? 在新单元格中输入以下语句并执行它们,从而以文本格式显示
x_train中的第一条评论:word_dict = imdb.get_word_index() word_dict = { key:(value + 3) for key, value in word_dict.items() } word_dict[''] = 0 # Padding word_dict['>'] = 1 # Start word_dict['?'] = 2 # Unknown word reverse_word_dict = { value:key for key, value in word_dict.items() } print(' '.join(reverse_word_dict[id] for id in x_train[0]))在输出中,“>”标志着评论的开始,而“?”标记不属于数据集中最常见的 10,000 个字词的字词。 这些“未知”字词在表示评论的整数列表中由 2 表示。 还记得传递到
load_data的num_words参数吗? 这就是它发挥作用的地方。 它不会缩减字典的大小,但会限制用于编码评论的整数的范围。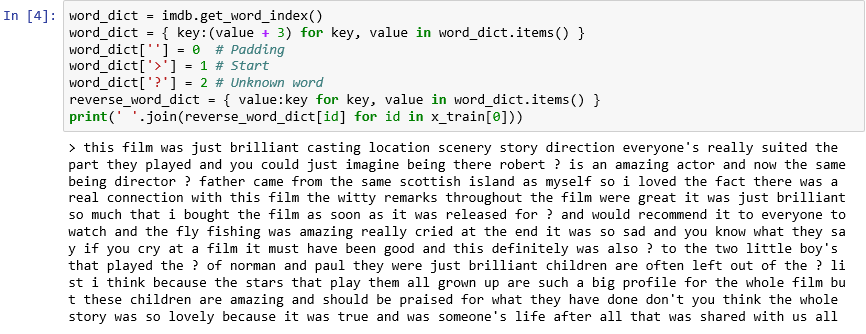
以文本格式显示的第一条评论
评论是“干净的”,因为字母已转换为小写字母并删除了标点字符。 但是,它们还没有为训练神经网络来分析文本的情绪做好准备。 使用张量集合训练神经网络时,每个张量需要具有相同的长度。 目前,表示
x_train和x_test中的评论的列表具有不同的长度。幸运的是,Keras 包含一个函数,可使用列表的列表作为输入,并能通过在必要时进行截断或使用 0 进行填充来将内部列表转换为指定的长度。 在笔记本中输入以下代码并运行它,以强制
x_train和x_test中表示电影评论的所有列表的长度变为 500 个整数:from keras.preprocessing import sequence max_review_length = 500 x_train = sequence.pad_sequences(x_train, maxlen=max_review_length) x_test = sequence.pad_sequences(x_test, maxlen=max_review_length)现在已准备好训练和测试数据,接下来可以开始构建模型! 在笔记本中运行以下代码,以创建执行情绪分析的神经网络:
from keras.models import Sequential from keras.layers import Dense from keras.layers.embeddings import Embedding from keras.layers import Flatten embedding_vector_length = 32 model = Sequential() model.add(Embedding(top_words, embedding_vector_length, input_length=max_review_length)) model.add(Flatten()) model.add(Dense(16, activation='relu')) model.add(Dense(16, activation='relu')) model.add(Dense(1, activation='sigmoid')) model.compile(loss='binary_crossentropy',optimizer='adam', metrics=['accuracy']) print(model.summary())确认输出如下所示:
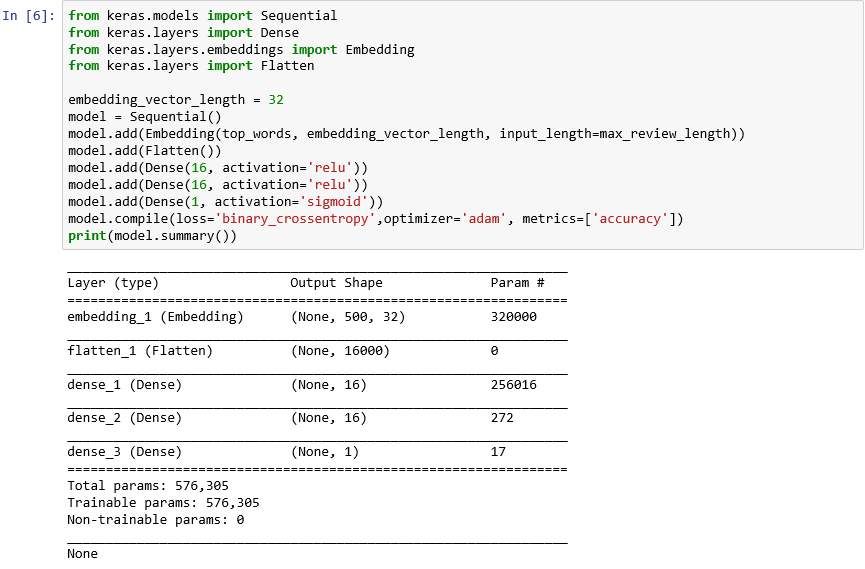
使用 Keras 创建神经网络
此代码对于使用 Keras 构造神经网络至关重要。 它首先实例化表示“顺序”模型的
Sequential对象,该对象由层的端到端堆栈组成,其中一个层的输出为下一个层提供输入。接下来的几个语句将层添加到模型中。 第一层是 Embedding 层,它对于处理字词的神经网络十分重要。 Embedding 层实质上将包含整数字词索引的多维数组映射到包含较少维度的浮点数组。 它还允许以同样的方式处理具有相似含义的字词。 对字词嵌入的完整处理超出本实验室的范围,但可通过阅读 Why You Need to Start Using Embedding Layers(为什么需要开始使用 Embedding 层)来了解详细信息。 如果喜欢偏学术性的解释,请参阅 Efficient Estimation of Word Representations in Vector Space(矢量空间中字词表示形式的高效估计)。 添加 Embedding 层后对 Flatten 进行调用会调整用于输入到下一层中的输出。
添加到模型中的接下来的三层是 Dense 层,也称为全连接层。 这些层是神经网络中常见的传统层。 每一层都包含 n 个节点或神经元,每个神经元接收来自上一层中每个神经元的输入,因此使用“全连接”这一术语。正是这些层让神经网络能够从输入数据中“学习”,方法是迭代猜测输出、检查结果并微调连接来生成更好的结果。 此网络中的前两个 Dense 层各包含 16 个神经元。 此数字任意选择;你可能能够通过尝试使用不同的大小来提高模型的准确率。 最后一个 Dense 层只包含一个神经元,因为网络的最终目标是预测一个输出,即从 0.0 到 1.0 的情绪得分。
结果是下图所示的神经网络。 该网络包含一个输入层、一个输出层和两个隐藏层(各包含 16 个神经元的 Dense 层)。 相比之下,当今一些较为复杂的神经网络拥有超过 100 个层。 一个示例是来自 Microsoft Research 的 ResNet-152,其在识别照片中物体方面的准确率有时会超过人类。 你可以使用 Keras 构建 ResNet-152,但需要一组配备了 GPU 的计算机来从头开始训练它。
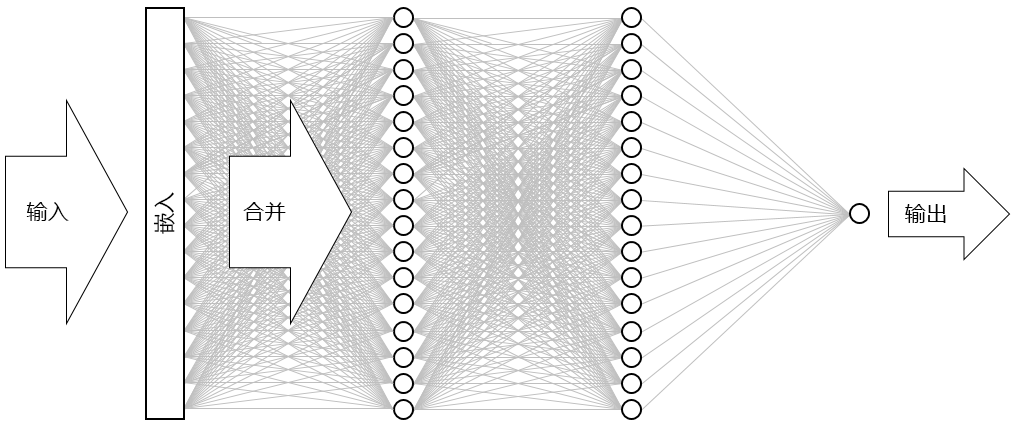
可视化神经网络
对 compile 函数的调用通过指定重要参数来“编译”模型,例如指定要使用的优化器以及要在每个训练步骤用于判断模型准确率的指标。 在调用模型的
fit函数前,训练不会开始,因此compile调用通常会快速执行。现在,调用 fit 函数来训练神经网络:
hist = model.fit(x_train, y_train, validation_data=(x_test, y_test), epochs=5, batch_size=128)训练大约需要 6 分钟,或每个时期需要 1 分钟以上。
epochs=5告诉 Keras 通过模型执行 5 次向前和向后传递。 凭借每次传递,模型将从训练数据中学习并使用测试数据度量(“验证”)它的学习情况。 然后,它会进行调整并返回执行下一次传递或下一个时期。 这在fit函数的输出中有所反映,输出显示每个时期的训练准确率 (acc) 和验证准确率 (val_acc)。batch_size=128告诉 Keras 一次使用 128 个训练样本来训练网络。 较大的批量大小可以加快训练时间(每个时期用完所有训练数据所需的传递次数更少),但较小的批量大小有时会提高准确率。 完成本实验室后,可能需要返回并使用 32 个训练样本的批量大小来对模型重新定型,以查看它对模型准确率的影响(如有)。 这大约需要两倍的训练时间。
模型定型
此模型的不同寻常之处在于它只需要几个时期就能很好地完成学习。 训练准确率可快速上升到接近 100%,同时,验证准确率会在一个或两个时期内上升,然后趋于平稳。你通常不希望在模型定型上花费的时间超出这些准确率于稳定所需的时间。 风险在于过度拟合,这会导致模型在测试数据中表现良好,但在真实数据中表现不佳。 模型过度拟合的一个迹象是训练准确率和验证准确率之间的差异越来越大。 有关过度拟合的全面介绍,请参阅 Overfitting in Machine Learning:What It Is and How to Prevent It(机器学习中的过度拟合:它是什么以及如何预防)。
若要将训练准确率和验证准确率的变化可视化为训练进度,请在新的笔记本单元格中执行以下语句:
import seaborn as sns import matplotlib.pyplot as plt %matplotlib inline sns.set() acc = hist.history['acc'] val = hist.history['val_acc'] epochs = range(1, len(acc) + 1) plt.plot(epochs, acc, '-', label='Training accuracy') plt.plot(epochs, val, ':', label='Validation accuracy') plt.title('Training and Validation Accuracy') plt.xlabel('Epoch') plt.ylabel('Accuracy') plt.legend(loc='upper left') plt.plot()准确率数据来自模型的
fit函数返回的history对象。 根据看到的图表,你是会建议增加训练时期的数量、减少训练时期的数量还是保持训练时期的数量不变?检查过度拟合的另一个方法是在训练进行时比较训练损失和验证损失。 此类优化问题寻求最小化损失函数。 可在此处了解详细信息。 对于给定时期,远远大于验证损失的训练损失可作为过度拟合的证据。 在上一步中,你使用
history对象的history属性的acc和val_acc属性来绘制训练准确率和验证准确率。 同一属性还包含名为loss和val_loss的值,这两个值分别代表训练损失和验证损失。 如果想要绘制这些值来生成如下所示的图表,你会如何修改上述代码来执行此操作?
训练损失和验证损失
考虑到训练损失和验证损失之间的差距在第三个时期中开始变大,如果有人建议将时期数量增加到 10 个或 20 个,你认为怎么样?
通过调用模型的
evaluate方法来确定模型根据x_test(评论)和y_test(0 和 1 [也称为“标签”],指示哪些评论是正面的,哪些评论是负面的)中的测试数据量化文本中表达的情绪的准确率,完成本练习:scores = model.evaluate(x_test, y_test, verbose=0) print("Accuracy: %.2f%%" % (scores[1] * 100))你的模型的计算准确率如何?
你实现的准确率可能在 85% 到 90% 的范围内。 考虑到你从头开始构建模型(而不是使用预先训练的神经网络),而且训练时间在没有 GPU 的情况下也很短,这是可以接受的。 可使用替代神经网络体系结构实现 95% 或更高的准确率,特别是使用长短期记忆 (LSTM) 层的递归神经网络 (RNN)。 借助 Keras,可轻松地构建此类网络,但训练时间可能呈指数级增长。 你构建的模型在准确率和训练时间之间达到了合理平衡。 但是,如果你想了解有关使用 Keras 构建 RNN 的详细信息,请参阅 Understanding LSTM and its Quick Implementation in Keras for Sentiment Analysis(了解 LSTM 及其在 Keras 中用于情绪分析的快速实现)。