案例研究:CEPH 文件系统
Ceph 是一种存储系统,可以部署在连接了磁盘的服务器组成的大型群集上。 以下视频介绍了 Ceph 背后的基本概念。
Ceph 的设计目标2 包括以下这些:
- 可灵活地支持各种应用程序的常规用途存储群集。
- 可以无缝扩展到成千上万个节点和 PB 级存储的体系结构。
- 任何单一故障点的高度可靠的系统,可自我管理且强大。
- 系统必须在可随时使用的商用硬件上运行。 Ceph 设计为可通过 3 个不同的抽象进行访问,如下图所示。
Ceph 存储群集是分布式对象存储。 面向客户端的不同存储服务在存储群集上进行分层。 Ceph 对象网关服务使客户端可以使用基于 REST 的 HTTP 接口(当前与 Amazon 的 S3 和 Openstack 的 Swift 协议兼容)访问 Ceph 存储群集。 Ceph 块设备服务使客户端可以将存储群集作为块设备进行访问,这些设备可以使用本地文件系统进行格式化并装载到操作系统中,也可以用作虚拟磁盘以在 Xen、KVM、VMWare 或 QEMU 中操作虚拟机。 最后,Ceph 文件系统 (Ceph FS) 将整个存储群集上的文件和目录抽象作为 POSIX 兼容文件系统进行提供。
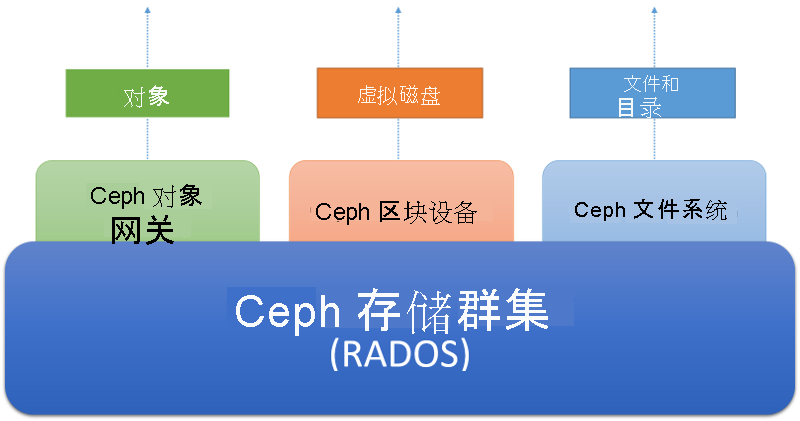
图 6:Ceph 生态系统
深入了解一下,Ceph 的体系结构如下所示:

图 7:Ceph 体系结构
Ceph 的核心是一种名为 RADOS 的分布式对象存储系统。 客户端可以使用一种名为 librados 的低级 API(基于套接字,支持多种编程语言)直接与 RADOS 进行交互。 或者,客户端可以与 3 个更高级别 API 进行交互,它们将 3 个单独的抽象提供给 RADOS。
RADOS 网关(或 radosgw)使客户端可以在 HTTP 上通过基于 REST 的网关访问 RADOS。 这会模拟 Amazon S3 对象服务,并且与使用 Amazon S3 API 或 Openstack SWIFT API 的应用程序兼容。
RADOS 块设备(或 RBD)将 RADOS 对象存储作为常规用途分布式块设备进行公开,这与 SAN 非常类似。 RBD 使块设备可以从 RADOS 中划分出来,并使用内核驱动程序在 Linux 系统上装载。 RBD 还可以用作热门虚拟化系统(如 Xen、VMWare、KVM 和 QEMU)的虚拟磁盘映像。
Ceph FS 是在 RADOS 上分层的 POSIX 兼容分布式文件系统,可以直接在 Linux 客户端的文件系统中装载。 稍后将在此页面上详细讨论 Ceph FS。
Ceph 存储群集体系结构 (RADOS)
Ceph 的核心是可靠的自治分布式对象存储 (RADOS)。 在 RADOS 中,数据存储为在计算机群集上分布的对象。 客户端通过存储和检索对象与 RADOS 群集进行交互。 对象由对象名称(用于标识对象的键)和对象的二进制内容(与特定对象键关联的值)组成。 RADOS 的角色是以可缩放、可靠且容错的方式,在群集中分布式存储对象。
RADOS 群集中有两种类型的节点:对象存储守护程序 (OSD) 和监视节点(图 8)。 OSD 会存储对象并响应针对对象的请求。 OSD 使用每个节点上的本地文件系统将这些对象存储在节点上,并保留缓冲区缓存以提高性能。 监视节点会监视群集的状态,以跟踪进入和离开群集的 OSD。
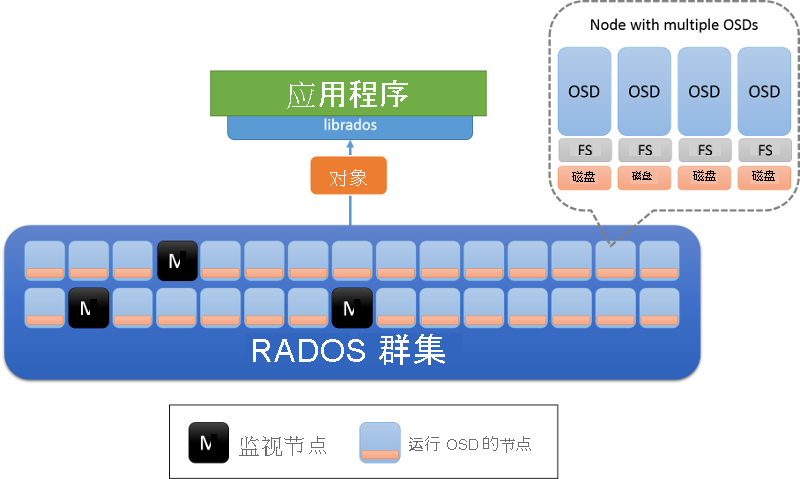
图 8:RADOS 体系结构。 OSD 负责节点上的数据(通常每个物理磁盘上部署一个 OSD)。 标记为 M 的节点是监视节点。
RADOS 中的群集状态和监视器
RADOS 群集的状态封装到称为“群集映射”的对象中,该对象由群集中的所有节点共享。 群集映射包含有关群集在任何给定时间的状态的信息,包括当前存在的 OSD 数、有关 OSD 间的数据分布方式(将在下一个部分中详细讨论)的精简表示形式,以及表示构建此群集映射的时间的逻辑时间戳。 对群集映射的更新由监视节点按对等的增量方式进行。 这意味着,群集映射中只有从一个时间戳到另一个时间戳的更改才会在群集中的节点之间进行通信,以便使节点之间传输的数据量较小。
RADOS 中的监视器通过存储群集映射的主副本并在 OSD 状态发生更改时发出定期更新,来共同负责存储系统的管理。 监视器基于 paxos 算法进行组织,需要大部分监视器读取或更新群集映射。 监视器可确保映射更新进行序列化且一致。 RADOS 群集设计为具有少量监视器 (>3),通常是奇数,以确保在各个监视器必须达成共识时不会中断联系。
RADOS 中的数据放置
若要使分布式对象存储可正常工作,客户端必须能够联系正确的 OSD 以便与对象进行交互。 首先,客户端会联系监视器以检索给定存储群集的群集映射。 群集映射中包含的信息可用于确定对群集中的特定对象负责的确切 OSD。
第一步是确定特定对象的放置组(图 9)。 可以将放置组视为对象所在的 Bucket。 这使用哈希函数来进行(始终从群集映射获取要使用的最新哈希函数)。 确定了给定对象的放置组后,客户端需要查找负责该放置组的 OSD。
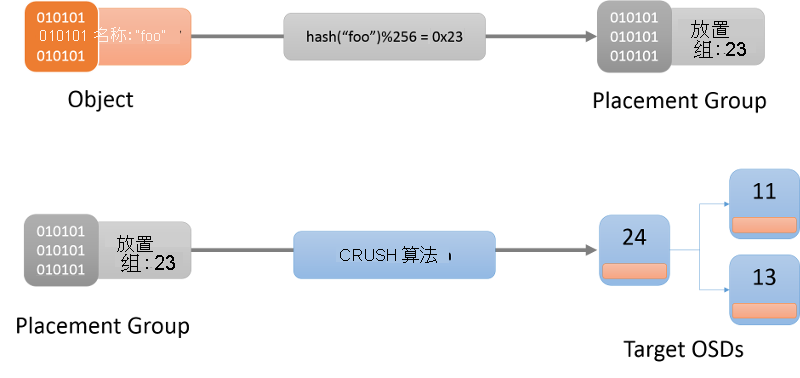
图 9:使用 CRUSH 算法将对象定位到位置组,最后定位到 OSD。
用于向 OSD 分配放置组的算法称为可缩放哈希下的受控复制 (CRUSH)1 算法(图 9)。 CRUSH 以伪随机但确定性的方式在群集中分配放置组。 CRUSH 比哈希函数更稳定,因为在 OSD 进入或离开群集时,CRUSH 可确保大多数放置组保留在原处,而只移动少量数据以保持均衡的分布。 另一方面,简单哈希函数会要求在添加或删除 Bucket 时重新分布大多数键。 CRUSH 算法的完整介绍不在此讨论范围之内。 感兴趣的读者应参阅 CRUSH:复制数据的受控且可缩放的分散放置。
将对象名称哈希处理到放置组时,CRUSH 会生成一个列表,其中恰好包含 r 个负责该放置组的 OSD。 此处,r 是给定对象的副本数。 根据群集映射中的信息,会标识此映射中的活动 OSD,然后可以联系 OSD 以便与指定对象进行交互(如创建、读取、更新、删除等操作)。
RADOS 中的复制
在 RADOS 中,一个对象在与该对象的放置组关联的多个 OSD 间进行复制。 这可确保存在特定对象的多个副本,以防某个 OSD 出现故障。 RADOS 具有多个用于实际执行复制的可用方案;它们是主副本、链和伸展复制方案(图 10)。
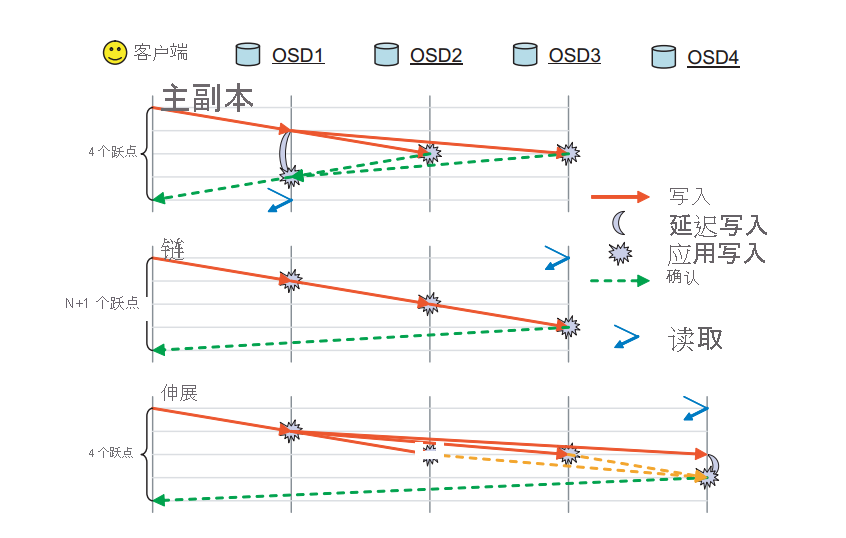
图 10:RADOS 中支持的复制模式。 (来源2)
主副本复制:在主副本复制方案中,客户端与第一个可用 OSD(主副本 OSD)进行交互,以便与对象进行交互。 主副本 OSD 会处理请求并响应客户端。 进行写入时,主副本 OSD 会将写入请求转发到 r-1 个副本,这些副本随后会更新对象的本地副本并响应主副本。 对主副本进行的写入操作会延迟,直到该对象的其他 OSD 提交了所有写入。 主副本随后会向客户端确认写入。 直到所有副本都已响应了主副本 OSD,写入才会完成。 相同的过程适用于读取,仅在已联系上了所有副本并且所有副本间的对象值都相同之后,主副本才会响应读取。
链复制:针对对象的请求会沿着链向下转发,直到找到第 r 个(最终)副本。 如果操作是写入操作,则会提交给到最后一个副本途中的每个副本。 包含最终副本的最终 OSD 最后会向客户端确认写入。 任何读取操作都会直接定向到末尾,以便减少从群集读取数据所需的跃点数。
伸展复制:伸展复制将主副本复制和链复制的元素相结合。 读取请求会定向到副本链中的最后一个 OSD,而写入会首先发送给第一个 OSD。 与链不同,对中间 OSD 的更新会并行完成,这与主副本复制方案类似。
除了这些复制方案之外,还可以使用两个单独的确认消息来处理 RADOS 中的持久性(图 11)。 每个 OSD 都具有一个包含它处理的数据的缓冲区缓存。 更新会写入缓冲区缓存并通过 ack 消息立即确认。 此缓冲区缓存会定期刷新到磁盘中,当最后一个副本将数据提交到磁盘时,commit 消息会发送到客户端,指示数据已持久化。
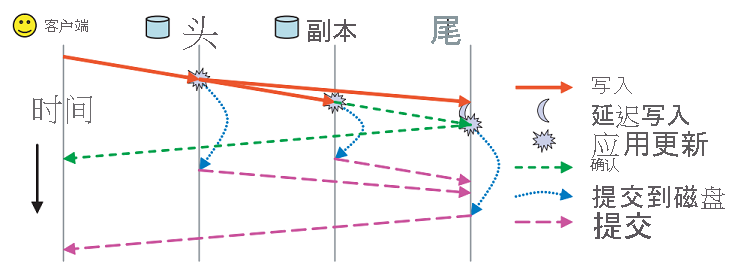
图 11:RADOS 中的 ack 与 commit 消息(来源 2)
RADOS 中的一致性模型
RADOS 中的每个消息(来自客户端以及节点间的对等消息)都使用时间戳进行标记,以确保按一致的方式对消息进行排序和应用。 如果 OSD 检测到由于消息请求者的群集映射过时而导致的错误消息,则它会发送增量映射更新以使消息请求者处于最新状态。
在某些极端情况下,必须谨慎处理 RADOS 提供的严格一致性保证。 如果特定 OSD 的放置组映射发生更改(群集映射中发生更改时),则系统必须确保应在旧 OSD 与新 OSD 之间无缝且一致地进行放置组的切换。 在放置组更改过程中,需要新 OSD 联系旧 OSD 以进行状态切换,在此期间,旧 OSD 将了解更改并停止响应对这些特定位置组的查询。
可能难以实现严格一致性保证的另一种情况是在出现导致网络分区的网络故障时。 在这种情况下,具有旧群集映射的某些客户端可能会继续对该 OSD 执行读取操作,而更新的映射可能会更改负责该放置组的 OSD。 回忆一下,这是之前在我们讨论 CAP 定理时已强调过的一种失败情况。 在这种情况下,此不一致性窗口将始终存在。 RADOS 试图通过要求所有 OSD 以默认的 2 秒间隔对其他副本发送检测信号来减轻这种情况的影响。 如果特定 OSD 无法在某个阈值内访问其他副本组,则会阻止其读取。 此外,分配给特定放置组成为新的主副本的 OSD 应从旧放置组主副本收到切换确认,或等待检测信号间隔,以确保旧放置组主副本关闭。 这样,便可减少存在网络分区时 RADOS 群集中的潜在不一致性窗口。
RADOS 中的故障检测和容错
在分配给某个位置组的 OSD 之间或 OSD 与监视节点之间的通信发生故障期间,会检测到 RADOS 中的节点故障。 如果节点在有限次数的重新连接尝试中未能响应,则将它声明为不活动状态。 作为放置组的一部分的 OSD 会交换检测信号消息,以确保检测到故障。 这会导致监视节点率先更新群集映射,并通过增量映射更新消息通知所有节点。 更新群集映射后,OSD 会在它们自己之间交换对象,以确保为每个放置组维护所需数量的副本。 如果某个 OSD 通过消息发现它已被声明为不活动状态,则只是将其缓冲区同步到磁盘并终止自己,以确保行为一致。
Ceph 文件系统
如上图所示,Ceph FS 是 RADOS 存储系统上的抽象层。 除了对象名称外,RADOS 没有任何对象元数据概念。 Ceph 文件系统允许在 RADOS 中存储的单个文件对象上对文件元数据进行分层。 以下视频说明了 CephFS 的概念。
除了 OSD 和监视器的群集节点角色外,Ceph FS 还引入了元数据 (MDS) 服务器(图 12)。 这些服务器存储文件系统元数据(目录树,以及每个文件的访问控制列表和权限、模式、所有权信息和时间戳)。
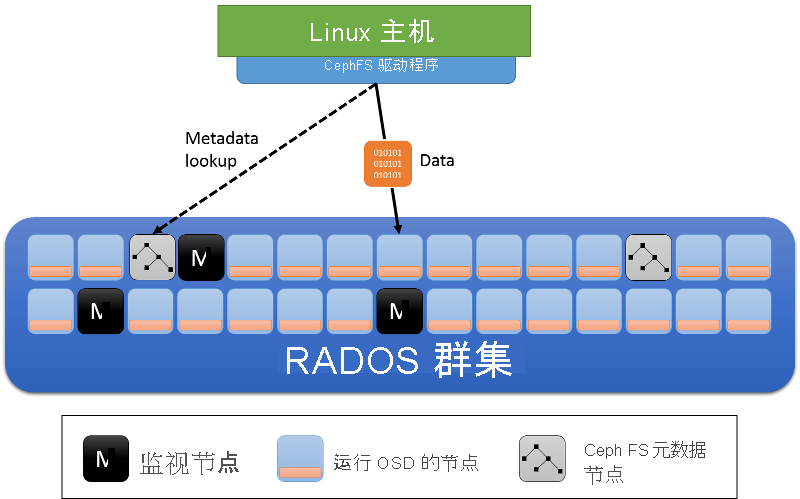
图 12:Ceph 文件系统中的元数据服务器
Ceph FS 使用的元数据在许多方面与本地文件系统使用的元数据不同。 回忆一下,在本地文件系统中,文件由 inode 行描述,而 inode 含指向文件数据块的指针的列表。 本地文件系统中的目录只是特殊文件,它们具有指向可能是其他目录或文件的其他 inode 的链接。 在 Ceph FS 中,元数据服务器中的目录对象包含嵌入在其中的所有 inode。
动态子树分区
最初,单台元数据服务器将负责群集的整个元数据。 随着将元数据服务器添加到群集,会对文件系统的目录树进行分区并分配给生成的元数据服务器组(图 13)。 每个 MDS 使用计数器来度量其目录层次结构中的元数据普及程度。 加权方案3 用于不仅更新目录中特定叶节点的计数器,还用于该目录元素的上级(直到根)。 因而每个 MDS 都能够保留元数据中的作用点列表,它们可以在新 MDS 添加到群集时移动到它。
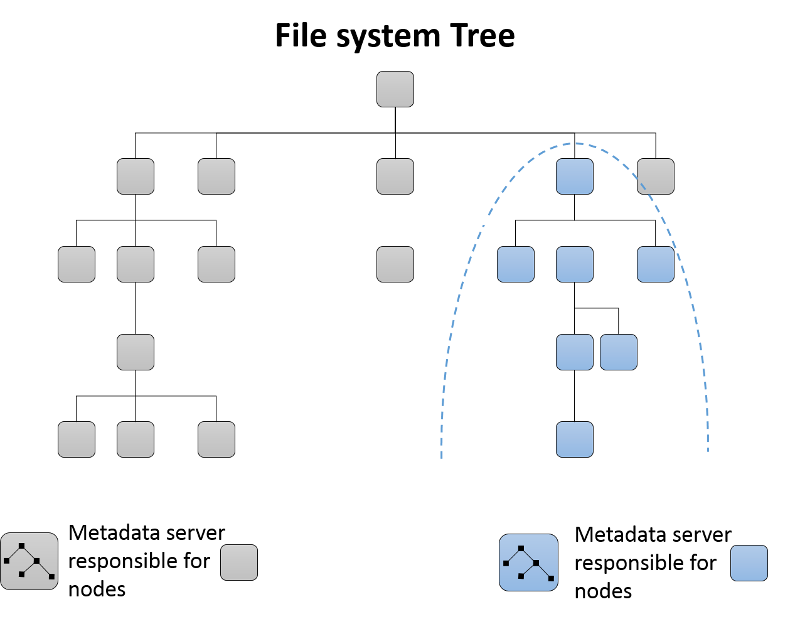
图 13:Ceph 文件系统中的动态子树分区
元数据服务器中的缓存和容错
Ceph FS 中的元数据服务器通常会将元数据信息缓存在内存中,并在内存外处理大多数请求。 此外,MDS 服务器使用某种形式的日记,其中更新作为日记对象向下游发送到 RADOS,并按元数据服务器写出。 如果元数据服务器发生故障,则可以重播日记以在新 MDS 或现有 MDS 上重新生成树的故障 MDS 服务器部分。
参考
- Weil, S. A.、Brandt, S. A.、Miller, E. L. 和 Maltzahn, C.(2006). CRUSH: Controlled, scalable, decentralized placement of replicated data In Proceedings of the 2006 ACM/IEEE conference on Supercomputing 122
- Weil, S. A.、Brandt, S. A.、Miller, E. L. 和 Maltzahn, C.(2006). Ceph: A scalable, high-performance distributed file system Proceedings of the 7th symposium on Operating systems design and implementation (OSDI) 307-320
- Weil, S. A.、Pollack, K. T.、Brandt, S. A. 和 Miller, E. L.(2004). Dynamic metadata management for petabyte-scale file systems In Proceedings of the 2004 ACM/IEEE conference on Supercomputing 4