将数据存储与 IoT 管道集成
现在你成功实现了 Cosmos DB 之后,需要确定如何将它与 Azure IoT 服务集成。 你计划了解其热路径和冷路径选项的用法。 通过此探索,可以更方便地考虑作为云原生应用程序设计一部分的智能设备库存和设备遥测方案。 你还希望确定能够在设计中使用的其他数据存储。
特定于 Azure Cosmos DB 的设计注意事项有哪些?
设计 Azure Cosmos DB 和容器层次结构时,正确选择分区键对于确保最佳性能和效率至关重要。 这一选择与通常涉及大量流式处理数据的 IoT 方案相关。
选择最适合的分区键时,应考虑使用模式和针对单个逻辑分区大小的 20-GB 限制。 通常,最佳做法是创建具有数百或数千个不同值的分区键。 这种方法会促使在与这些分区键值关联的项之间均衡使用存储和计算资源。 同时,共享同一分区键值的项的组合大小不得超过 20 GB。
例如,收集 IoT 数据时,可以选择将 /date 属性用于遥测流式处理,并将 /deviceId 用于设备库存(如果这些属性表示最常见数据查询的目标)。 或者,可以构造合成分区键,如 /deviceId 和 /date 的值的串联。 另一种方法是在分区键值末尾追加指定范围内的随机数字。 这种方法可帮助确保跨多个分区均衡分配工作负荷。 这样,在将项加载到目标集合中时,可以跨多个分区执行并行写入。
IoT 方案中的数据管道是什么?
IoT 方案中的一种常见情况是实现多个并发数据路径,具体方法是对引入数据流进行分区,或将数据记录转发到多个管道。 对应体系结构模式称为 Lambda 体系结构,由两种不同类型的管道组成。
快速(热)处理管道:
- 执行实时处理。
- 分析数据。
- 显示数据内容。
- 生成对时间敏感的短期信息。
- 触发相应的操作,如警报。
- 将数据存储在存档中。
慢速(冷)处理管道:
- 执行更复杂的分析,可能会合并较长时间内来自多个源的数据。
- 生成报表或机器学习模型等项目。
Azure 服务在实现 IoT 管道时的作用是什么?
IoT 系统会引入由各种设备生成的遥测、处理和分析流式处理数据以获得准实时见解,以及将数据存档到冷存储以进行批量分析。 数据路径从 IoT 设备生成的遥测开始,这类遥测会发送到 Azure IoT 中心或 Azure IoT Central 以进行初始处理。 Azure IoT 中心和 Azure IoT Central 会存储在可配置的时间内收集的数据。
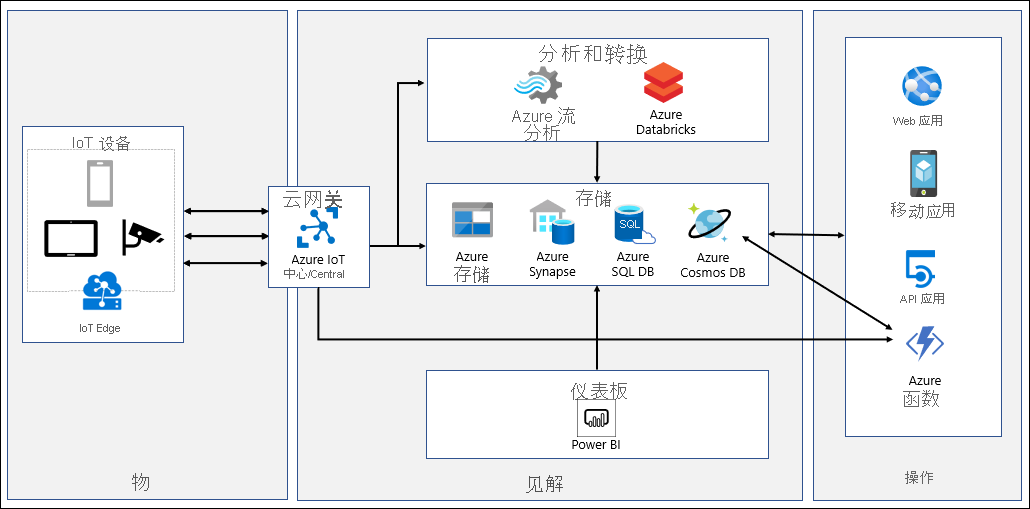
Azure IoT 中心支持分区和消息路由,这使你可以为 Azure 逻辑应用和 Azure Functions 进行的处理、警报和修正任务指定特定消息。 Azure IoT Central 中提供了等效功能,该功能基于通过 Webhook 触发操作的自定义配置规则。 Webhook 可以指向 Azure Functions、Azure 逻辑应用、Microsoft Flow 或你自己的自定义应用。 通过 Azure IoT 中心路由还可以将遥测转发到 Azure 函数进行初始处理,然后将其转发到 Azure Cosmos DB。 此类处理的示例包括格式转换或构造合成分区键。 Azure IoT 中心路由的另一种潜在用途涉及将传入数据复制到 Azure Blob 存储或 Azure Data Lake。 这种方法可提供一种低成本的存档选项,可以方便地访问以进行批处理,包括 Azure 机器学习数据科学任务。
Azure IoT Central 可将数据持续导出到 Azure 事件中心、Azure 服务总线和自定义 Webhook。 还可配置基于间隔的数据导出来导出到 Azure Blob 存储。 Azure Functions 支持 Azure 事件中心和 Azure 服务总线的绑定,可以利用这种绑定将它们与 Azure Cosmos DB 集成。
借助 Azure IoT Central,可以通过其内置分析功能提供准实时见解。 对于更高级的分析需求或是在使用 Azure IoT 中心时,可以将数据传送到 Azure 流分析。 Azure 流分析支持 Azure Cosmos DB SQL API 作为其输出,将流处理结果作为 JSON 格式的项写入 Azure Cosmos DB 容器中。 这会实现数据存档,并允许对非结构化 JSON 数据进行低延迟的即席查询。 更改源功能会自动检测新数据和现有数据的更改。 可以通过将 Azure Cosmos DB 连接到 Azure Synapse Analytics 来处理此数据。 处理完成后,可以将它重新加载到 Azure Cosmos DB,以便进行更深入的报告。 还可以将 Azure Databricks 与 Apache Spark 流式处理结合使用,以便:
- 从 Azure IoT 中心加载数据。
- 进行处理以提供实时分析。
- 进行存档以便长期保留并向 Azure 服务(如 Azure Cosmos DB、Azure Blob 存储或 Azure Data Lake)提供更多报告。