了解 Azure 数据生态系统
新式分析需要可从多个源存储和转换数据的工具。 在本单元中,你将了解 Azure 数据存储解决方案、数据引入和数据处理。
在向 Relecloud 的 CEO 展示分析解决方案之前,数据团队需要清楚地了解数据来自何处、数据将采用什么形式,以及传入数据的预期规模和频率。 执行结构化需求收集之前,请与团队一起了解关键数据概念。
Azure 数据存储解决方案
Azure 存储帐户是 Azure 中的基本存储类型。 Azure 存储为数据对象和云中的文件系统服务提供了一个可缩放的对象存储。
在分析解决方案中,合并来自不同源的数据并准备好使用。 数据可以作为文件存储在 Data Lake Store 或数据库中。 了解 Azure 中的基本存储类型对于数据工程师很重要,而数据分析人员需要熟悉分析数据存储,该数据存储提供采用可使用分析工具进行查询的格式的已处理数据。
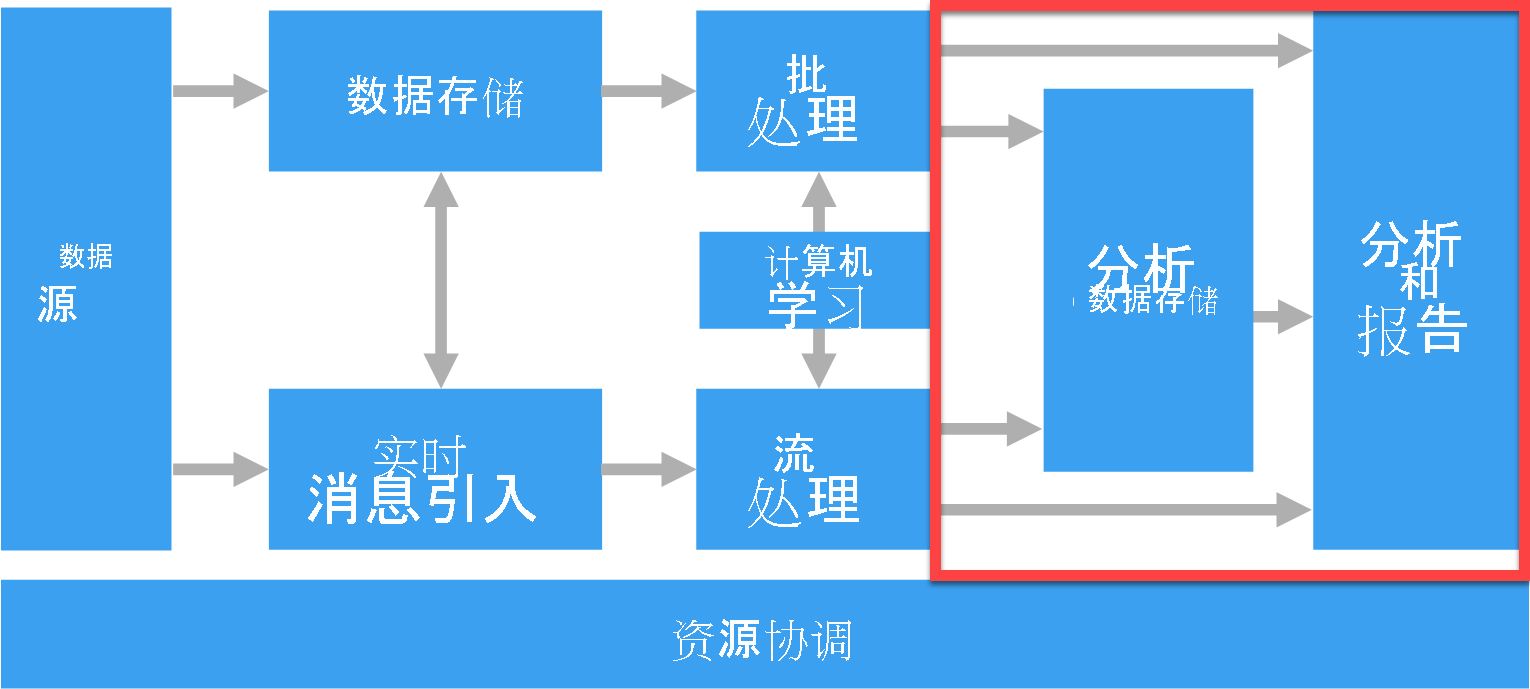
上图中以红色概述的区域突出显示了数据分析人员用于理解数据的分析解决方案各部分。
注意
详细了解 Azure 中的数据存储和分析数据存储的技术选择。
数据引入和处理
数据引入是在分析数据存储中获取和导入数据以便立即使用或存储的过程。
数据处理就是通过某个过程将原始数据转换为有意义的信息。 根据数据引入系统的方式,可能需要在每个数据项到达时进行处理,也可能需要先缓冲原始数据,然后按组进行处理。 在数据到达时进行处理被称为流式处理。 对组中的数据进行缓冲,然后处理,称为批处理。
在批处理中,新到达的数据元素将被收集到一个组中。 然后,在将来的某个时间对整个组进行批处理。 处理每个组的确切时间可以通过多种方式来确定。 例如,可以根据计划的时间间隔(例如,每小时)处理数据,也可以在到达特定数量的数据时触发数据处理。 Relecloud 的每月计费流程是批处理的不错示例,因为帐户事务按月处理和计费。
注意
批处理是最常见的数据处理类型,最适合大型数据集或来自旧数据系统的数据。 批处理不适合快速分析和决策制定。
在流式处理中,每个新数据在到达时就会得到处理。 例如,数据引入本质上是一种流式处理进程。
流式处理过程是实时处理数据。 与批处理不同,不存在等待下一批要处理的数据的情况,而是将数据作为独立单位进行处理,不视为一次处理一个的批次。 在大多数连续生成新动态数据的情况下,流式数据处理非常有用。
欺诈部门将使用流式处理来处理实时欺诈和异常情况检测。
注意
流式处理非常适合需要实时分析的项目,但不太适合需要复杂分析的项目。
虽然数据处理通常发生在分析数据存储的上游,但分析人员必须了解引入数据的方式和频率,以生成适当的分析解决方案。