定义重复数据删除的体系结构、组件和功能
大多数组织和企业(包括 Contoso)都必须处理并存储不断增长大量数据。 尽管有解决方案可以将数据卸载并存档到云,但在许多情况下,需要在本地数据中心对其进行维护。 对此类数据的存储进行有效管理,需要合适的工具。 使用 Windows Server 时,可以选择使用重复数据删除实现此目的。
什么是重复数据删除?
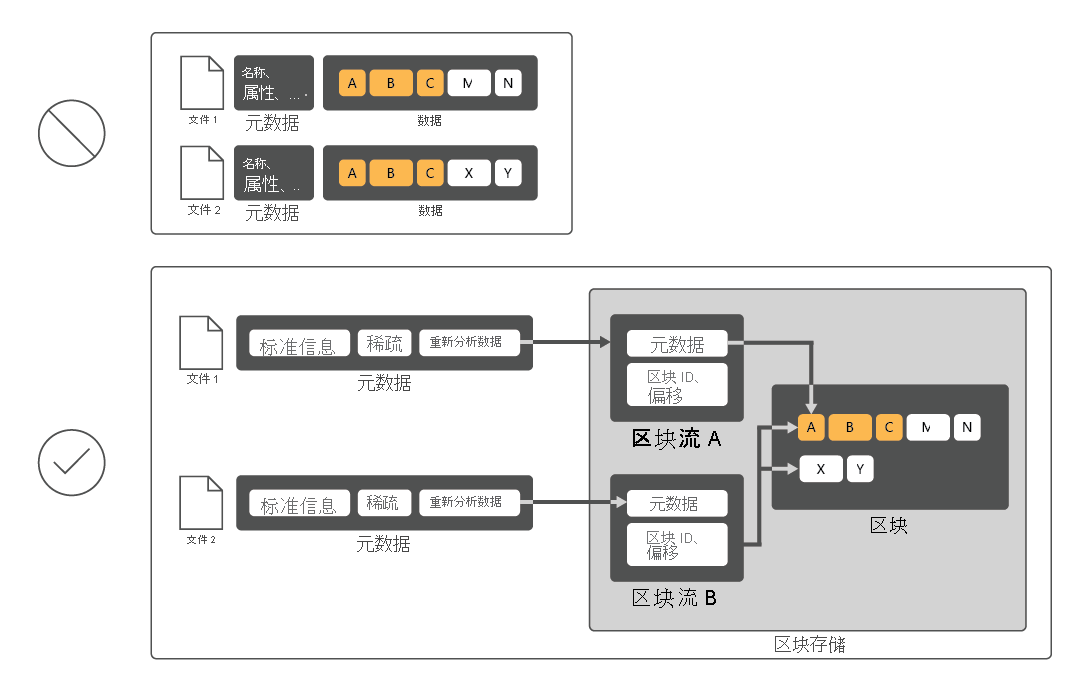
重复数据删除是 Windows Server 的角色服务,在不影响数据完整性的情况下标识并删除重复数据。 这就实现了在使用更少物理磁盘空间的情况下存储更多数据的目标。
为了降低磁盘利用率,重复数据删除会扫描文件,然后将这些文件分成多个区块,并且每个区块仅保留一个副本。 删除重复后,不再将文件存储为独立的数据流。 重复数据删除反而会将文件替换为指向存储在通用区块存储中的数据块的存根。 访问已删除重复的数据的过程对用户和应用是完全透明的。
在许多情况下,数据重复会提高总体磁盘性能,因为多个文件可以共享缓存在内存中的一个区块。 这样就可以通过执行更少的读取操作来检索这些文件中的数据,从而在读取已删除重复数据的文件时弥补对性能产生的较小影响。 重复数据删除对磁盘写入的性能没有影响,因为它仅适用于磁盘上已有的数据。
重复数据删除的组件有哪些?
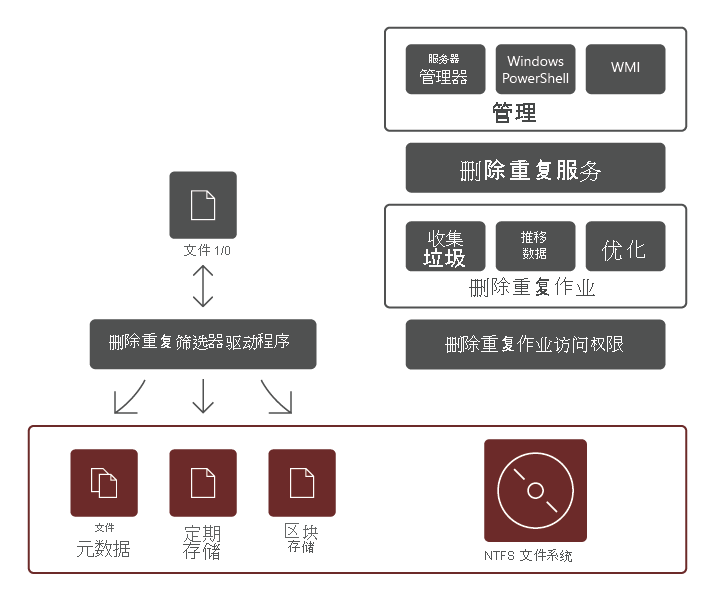
重复数据删除角色服务包含以下组件:
- 筛选器驱动程序。 此组件将读取请求重定向到所请求的文件中的区块。 每个卷都有一个筛选器驱动程序。
- 删除重复服务。 此组件管理以下作业:
- 删除重复和压缩。 这些作业根据卷的重复数据删除策略处理文件。 首次优化文件后,如果文件发生修改并满足优化的重复数据删除策略阈值,则将再次优化文件。
- 垃圾回收。 此作业处理卷上已删除或已修改的数据,以便清除不再引用的所有数据块,从而生成可用磁盘空间。 垃圾回收默认每周运行一次,但是也可以考虑在删除许多文件后对其进行调用。
- 清理。 此作业依赖于校验和验证和元数据一致性检查等复原功能,识别并尽可能自动解决数据完整性问题。
注意
由于其他验证功能,删除重复可以检测并报告早期数据损坏迹象。
- 取消优化。 此作业对卷上所有优化文件反向删除重复。 使用此类作业的一些常见场景包括:解决已删除重复的数据的问题,或将数据迁移到不支持重复数据删除的其他系统。
注意
启动此作业前,应使用 Disable-DedupVolume Windows PowerShell cmdlet 禁用一个或多个卷上的更多重复数据删除活动。
注意
禁用重复数据删除后,卷保持删除重复的状态,并且仍可访问现有已删除重复的数据;但是服务器停止运行该卷的优化作业,并且不会删除重复的新数据。 然后可以使用取消优化作业撤销卷上的现有已删除重复的数据。 取消优化作业成功结束后,将删除卷中所有重复数据删除的元数据。
重要
使用取消优化作业时,请确保托管此数据的卷具有足够的可用空间,因为所有已删除重复数据的文件都将还原到其原始大小。
重复数据删除的范围
重复数据删除处理所选卷上的所有数据,但有以下例外:
- 不符合配置的重复数据删除策略的文件。
- 从删除重复的范围中显式排除的文件夹中的文件。
- 系统状态文件。
- 备用数据流。
- 加密文件。
- 具有扩展属性的文件。
- 小于 32 KB 的文件。
注意
从 Windows Server 2019 开始,复原文件系统 (ReFS) 支持对最大为 64 TB 的卷和最大为 4 TB 的文件执行重复数据删除。 它还依赖于大小可变的区块存储,该区块存储包含在多线程后处理体系结构保持最小性能影响时,可以最大程度节省磁盘空间的可选压缩功能。