解释 Spark 结构化流
Spark 结构化流是一种用于内存中处理的常用平台。 它具有用于批处理和流式处理的统一范例。 任何批处理的知识和用法都可以用于流式处理,所以从批处理数据发展为流式处理数据很轻松。 Spark Streaming 只是在 Apache Spark 上运行的引擎。

结构化流创建长时间运行的查询,在此期间,可对输入数据应用操作,例如选择、投影、聚合、开窗,以及将流数据帧与引用数据帧相联接。 接下来,可以使用自定义代码(例如 SQL 数据库或 Power BI)将结果输出到文件存储(Azure 存储 Blob 或 Data Lake Storage)或任何数据存储。 结构化流可向控制台提供输出以用于本地调试,还可以向内存中表提供输出,以便可以在 HDInsight 中查看用于调试的生成数据。
流即表
Spark 结构化流以表的形式表示数据流,该表的深度受限,即,随着新数据的抵达,该表会不断增大。 此输入表由一个长时间运行的查询持续处理,结果将发送到输出表:

在结构化流中,数据抵达系统后立即被引入输入表中。 可以编写针对此输入表执行操作的查询(使用数据帧和数据集 API)。 查询输出生成另一个表,即结果表。 结果表包含查询的结果,从中可以抽取外部数据存储(例如关系数据库)的数据。 处理输入表中数据的时间由触发器间隔控制。 默认情况下,触发器间隔为零,因此,结构化流会在数据抵达时尽快处理数据。 在实践中,这意味着结构化流在处理完前一查询的运行之后,会立即针对所有新收到的数据启动另一个处理运行。 可将触发器配置为根据某个间隔运行,以便在基于时间的批中处理流数据。
结果表中的数据可以只包含自上次处理查询以来生成的新数据(追加模式),或者,每当生成新数据时,可以刷新结果表中的数据,使表中包含自开始执行流查询以来生成的所有输出数据(完整模式)。
追加模式
在追加模式下,只有自上次运行查询以来添加到结果表的行才出现在结果表中,并写入外部存储。 例如,最简单的查询只是将输入表中的所有数据按原样复制到结果表。 在触发器间隔过去之后,将会处理新数据,代表这些新数据的行会显示在结果表中。
请考虑这样一个场景:你正在处理股票价格数据。 假设第一个触发器在 00:01 为价值 95 美元的 MSFT 股票处理了一个事件。 在查询的第一个触发器中,只有包含时间 00:01 的行会出现在结果表中。 当另一个事件在时间 00:02 抵达时,唯一的新行是包含时间 00:02 的行,因此,结果表只包含该行。
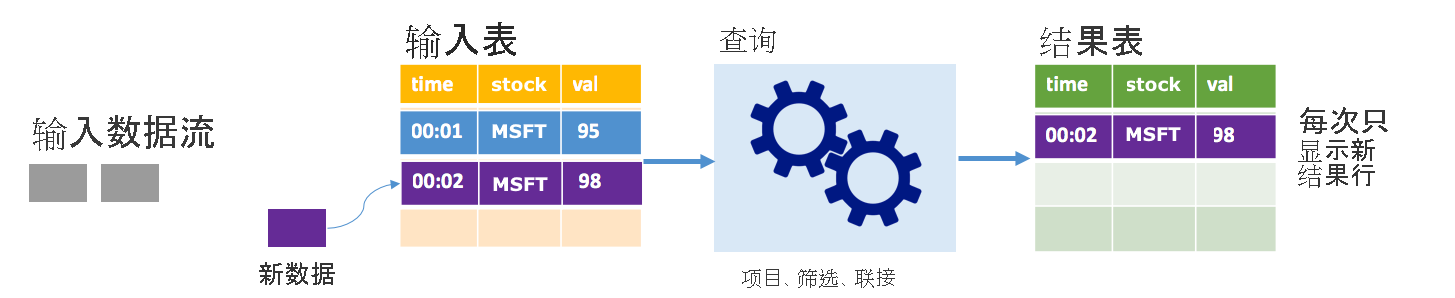
使用追加模式时,查询将应用投影(选择它关注的列)、筛选(只选择与特定条件匹配的行)或联接(使用静态查找表中的数据来扩充数据)。 使用追加模式可以轻松做到只将相关的新数据点推送到外部存储。
完整模式
沿用上述情景,但这一次使用的是完整模式。 在完整模式下,整个输出表根据触发器间隔刷新,因此,该表不仅包含来自最新触发器运行的数据,而且还包含来自所有运行的数据。 可以使用完整模式将输入表中的数据按原样复制到结果表。 在每个触发的运行中,新结果行会连同前面的所有行一起显示。 输出结果表最后将存储所有自查询开始以来收集的数据,而你最终会耗尽内存。 完整模式适合用于以某种方式汇总传入数据的聚合查询,因此,在每个触发器间隔,将使用新的摘要更新结果表。
假设到目前为止处理了 5 秒的数据,是时候处理第 6 秒的数据了。 输入表包含时间 00:01 和时间 00:03 的事件。 此示例查询的目的是给出股票每五秒的平均价格。 此查询的实现将应用一个聚合,以便提取处于每个 5 秒的窗口内的所有值,计算股票价格平均值,然后生成一行来显示该间隔内的平均股票价格。 在第一个 5 秒时间范围结束时,会生成两个元组:(00:01, 1, 95) 和 (00:03, 1, 98)。 因此对于 00:00-00:05 这个窗口,聚合生成平均股票价格为 $96.50 的元组。 在下一个 5 秒的窗口中,时间为 00:06 时仅有一个数据点,所以得到的股票价格为 $98。 在时间 00:10 处使用完整模式时,结果表包含时间范围 00:00-00:05 和 00:05-00:10 的行,因为查询会输出所有聚合行,而不仅仅是新行。 因此,随着新窗口的添加,结果表会不断增大。
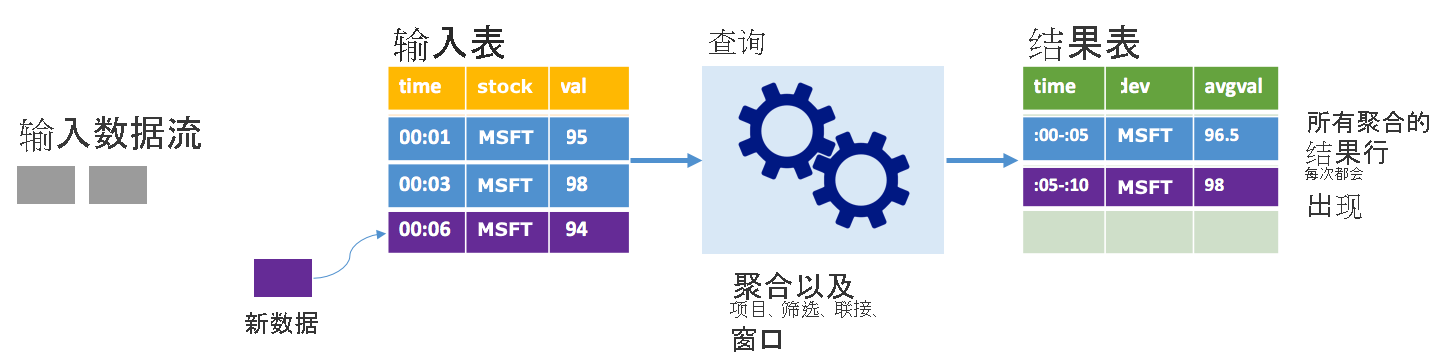
并非所有使用完整模式的查询都会导致表无限增大。 回想上一个示例,它并不是按窗口计算平均股价,而是按股票计算平均股价。 结果表包含固定数量的行(每只股票一行),这些行包含根据设备发送的所有数据点计算得出的平均股票价格。 结果表在收到新的股票价格后更新,使表中始终显示最新的平均价格。
Spark 结构化流的优点是什么?
在金融业中,交易时机尤为重要。 例如,在股票交易中,股市中股票交易的时间、收到交易的时间或读取数据的时间这三者之间的差异都很重要。 金融机构非常依赖这些关键数据及其相关的时机。
事件时间、最新数据和水印
Spark 结构化流知道事件时间和系统处理事件的时间之间的差异。 每个事件都是表中的一行,事件时间是行中的列值。 这样,基于窗口的聚合(例如每分钟的事件数)只是事件时间列上的分组和聚合,每个时间窗口为一组,每行可属于多个窗口/组。 因此,可以在静态数据集和数据流上一致地定义这种基于事件时间窗口的聚合查询,从而使数据工程师的工作更轻松。
此外,此模型根据事件时间自然处理到达的时间比预期晚的数据。 Spark 对以下两项任务拥有完全控制:在有较新数据时更新旧聚合,以及清理旧聚合以限制中间状态数据的大小。 此外,Spark 自 2.1 版开始支持水印,使你能够指定较新数据的阈值,使引擎能相应地清理旧状态。
拥有上传最新数据或所有数据的灵活性
如上一个单元中所述,你可以选择在运用 Spark 结构化流时使用追加模式或完整模式,以便结果表只包含最新数据或所有数据。
支持从微批处理移动到连续处理
更改 Spark 查询的触发类型,就可以从微批处理移动到连续处理,而无需对框架进行其他更改。 以下是 Spark 支持的不同类型的触发。
- 未指定触发(这是默认的类型)。 如果没有明确设置触发,则以微批处理方式执行并连续处理查询。
- 固定间隔微批处理触发。 查询按用户设置的间隔定期执行。 如果未收到新数据,则不运行微批处理。
- 一次性微批处理触发。 查询运行一次微批处理,然后停止。 如果你想处理自上一次微批处理以来的所有数据,这种触发很有帮助,并且它可以为不需要连续运行的作业节省成本。
- 以固定的检查点间隔连续触发。 查询以新的低延迟、连续处理模式运行,该模式实现具有至少一次容错保证的端到端低延迟(约 1 毫秒)。 这种类型与默认类型相似,可以实现仅一次的保证,但延迟最低只能达到约 100 毫秒。
将批处理和流式处理作业结合
除了简化从批处理作业移动到流式处理作业的过程,你还可以将批处理作业和流式处理作业结合起来。 希望在处理实时信息的同时使用长期历史数据预测未来趋势时,这尤其有用。 以股票为例,你可能需要查看过去 5 年的股票价格以及当前价格,从而围绕年度或季度收入公告预测变化。
事件时间窗口
你可能需要捕获窗口中的数据(例如一天或一分钟的窗口内的高股价和低股价),无论你决定使用什么间隔,Spark 结构化流都支持。 还支持重叠窗口。
故障恢复的检查点操作
如果出现故障或故意关闭,你可以恢复上一个查询先前的进度和状态,并从中断的地方继续操作。 这是使用检查点操作和预写日志完成的。 你可以为查询配置一个检查点位置,查询将保存所有进度信息(即每个触发器中处理的偏移量范围)和该检查点位置正在运行的聚合。 此检查点位置必须是 HDFS 兼容文件系统中的路径,可以设置为启动查询时 DataStreamWriter 中的选项。