测试和训练数据集
用于训练模型的数据通常称为“训练数据集”。 我们已经实际了解这一点。 令人沮丧的是,当我们在现实世界中使用模型时,在训练模型后,我们并不确定它的表现如何。 这种不确定性是因为我们的训练数据集可能不同于现实世界中的数据。
什么是过度拟合?
如果模型在训练数据方面的表现优于其他数据,则模型过度拟合。 这个说法指的是,模型拟合良好,以至于它能记住训练集的详细信息,而不是寻找适用于其他数据的广泛规则。 过度拟合很常见,但不可取。 在一天结束时,我们只关心模型在实际数据上的工作情况。
那么如何才能避免过度拟合?
我们可以通过多种方法避免过度拟合。 最简单的方法就是使用更简单的模型,或者使用数据集来更好地表示现实世界中所见的内容。 若要了解这些方法,来看一个场景,其中实际数据如下所示:
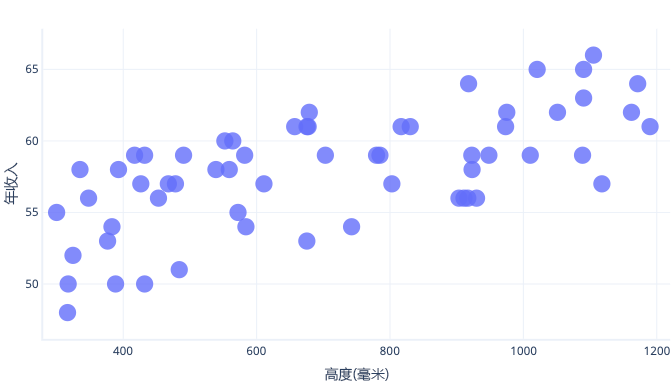
假设我们只收集了五只狗的信息,并将其用作训练数据集来拟合一条复杂的线。 如果能够这样做,就可以很好地拟合:
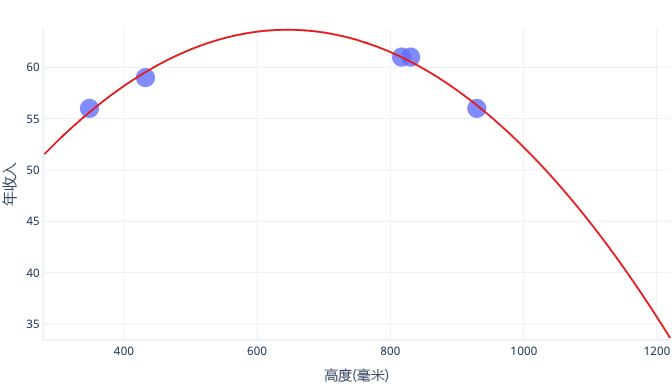
但是,当实际使用此图表时,我们发现它给出的预测是错误的:
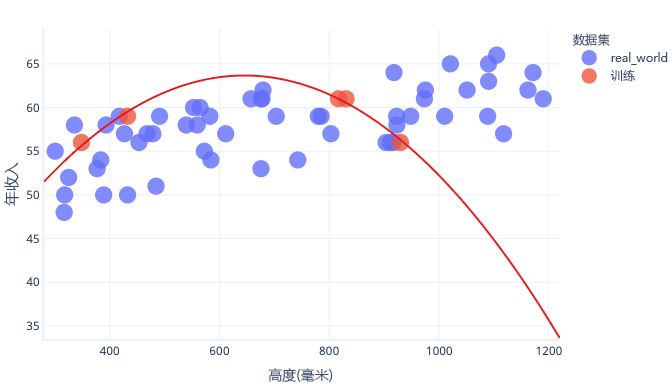
如果我们有一个更具代表性的数据集和更简单的模型,则拟合的线可以改善预测(尽管并不完美)预测:
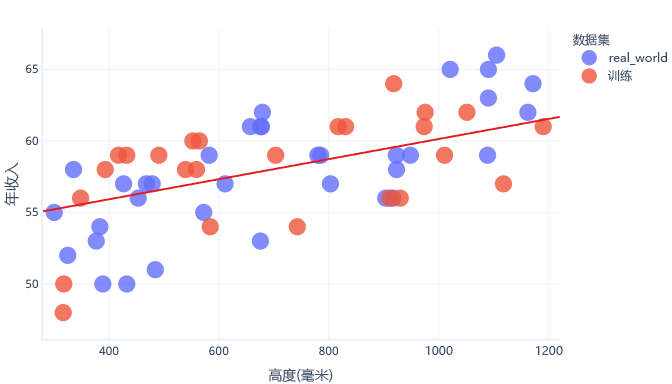
避免过度拟合的一种免费方法是在模型学习了常规规则之后,但在模型过度拟合之前,停止训练。 但是,这需要检测何时开始过度拟合模型。 为此,可以使用“测试数据集”。
什么是测试数据集?
测试数据集(也称为“验证数据集”)是一组类似于训练数据集的数据。 事实上,测试数据集通常是通过采用大型数据集并拆分它而创建的。 一部分称为“训练数据集”,另一部分称为“测试数据集”。
训练数据集的工作是训练模型;我们已经看到了训练。 测试数据集的工作是检查模型的工作情况;它不直接参与训练。
好吧,但意义是什么?
测试数据集的意义有两个方面。
首先,如果测试性能在训练期间停止改进,我们可以停止,没有必要继续。 如果继续操作,最终就会鼓励模型学习有关不在测试数据集中的训练数据集的详细信息,这就是过度拟合。
其次,我们可以在训练后使用测试数据集。 这可以向我们指明最终模型在看到此前未看到的“真实”数据时的工作情况。
对于成本函数,这意味着什么?
当我们同时使用训练数据集和测试数据集时,最终会计算两个成本函数。
第一个成本函数使用训练数据集,就像之前看到的那样。 此成本函数将提供给优化器并用于训练模型。
第二个成本函数是使用测试数据集计算的。 我们使用它来检查模型在现实世界中的工作情况。 成本函数的结果不用于训练模型。 为了计算结果,我们将暂停训练,查看模型在测试数据集方面的表现,然后继续训练。