什么是回归?
回归的工作原理是在表示被观察的事物特征(称为特征)的数据变量与我们试图预测的变量(称为标签)之间建立关系。
回想一下,我们的公司要租赁自行车,并且想要预测给定一天内的预期租赁数量。 在本例中,特征包括星期几和月份等。而标签是自行车租赁数。
为了训练相应模型,我们从包含特征和标签已知值的数据样本开始。因此,在此例中,我们需要包含日期、天气情况和自行车租赁数量的历史数据。
然后,将此数据样本拆分为两个子集:
- 训练数据集,我们将对其应用一种算法,该算法确定封装了特征值与已知标签值之间关系的函数。
- 验证或测试数据集,可用来评估模型,方法是使用该数据集生成标签的预测,并将预测与实际的已知标签值进行比较。
使用具有已知标签值的历史数据来训练模型使回归成为监督式机器学习的一个示例。
一个简单示例
让我们通过一个简单的示例来了解训练和评估过程的原理。 假设我们简化了方案,以便可以使用单个特征(即每日平均温度)来预测自行车租赁标签。
我们从一些数据开始,其中包括每日平均温度特征和自行车租赁标签的已知值。
| 温度 | 租赁数 |
|---|---|
| 56 | 115 |
| 61 | 126 |
| 67 | 137 |
| 72 | 140 |
| 76 | 152 |
| 82 | 156 |
| 54 | 114 |
| 62 | 129 |
现在,我们将随机选择其中五个观察值,并使用它们训练回归模型。 当我们讨论“训练模型”时,我们指的是找到一个函数(一个数学方程,称之为 f),它可以使用温度特定(我们称之为 x)计算出租赁数(我们称之为 y)。 换句话说,我们需要定义以下函数:f(x) = y。
训练数据集如下所示:
| x | y |
|---|---|
| 56 | 115 |
| 61 | 126 |
| 67 | 137 |
| 72 | 140 |
| 76 | 152 |
首先,在图表上绘制 x 和 y 的训练值:

现在,需要将这些值拟合为一个函数,以实现一些随机变化。 你可能会发现,绘制的点几乎形成了一条对角线,换句话说,x 和 y 之间存在明显的线性关系,因此我们需要找出最适合数据样本的线性函数。 可以使用多种算法来确定此函数,这些算法最终将找到一条与所绘制点的总体方差最小的直线,如下所示:
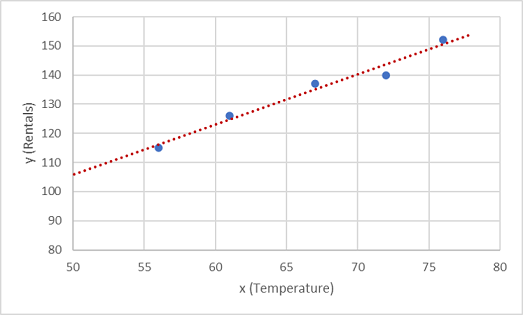
该线表示一个线性函数,可以将其与任何 x 值一起使用,以应用该线的斜率及其截距(当 x 为 0 时,该线与 y 轴交叉)来计算 y。 在本例中,如果将该线向左延伸,会发现当 x 为 0 时 y 约为 20,并且该线的斜率决定了 x 每向右移动一个单位,y 会增加约 1.7。 因此,我们可以将 f 函数计算为 20 + 1.7x。
现在我们已经定义了预测函数,可以使用它来预测所保留的验证数据的标签,并将预测值(通常用符号“ŷ”或“y-hat”表示)与实际已知的 y 值进行比较。
| x | y | ŷ |
|---|---|---|
| 82 | 156 | 159.4 |
| 54 | 114 | 111.8 |
| 62 | 129 | 125.4 |
让我们看一下 y 和 ŷ 值在绘图中的比较情况:
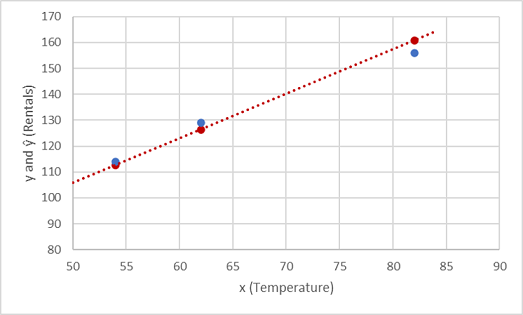
函数线上的绘制点是由函数计算的预测 ŷ 值,而其他绘制点是实际 y 值。
可以采用多种方法来度量预测值和实际值之间的差值,并且可以使用这些指标来评估模型的预测效果。
备注
机器学习基于统计和数学,因此必须了解统计学家和数学家(以及数据科学家)使用的特定术语。 可以将预测标签值与实际标签值之间的差值视为误差的度量。 但是实际上,“实际”值是基于样本观察值的(其本身可能会有一些随机变化)。 为了明确我们将预测值 (ŷ) 与观察值 (y) 进行比较,我们将它们之间的差值称为残差。 我们可以汇总所有验证数据预测的残差,以计算模型中的总体损失,作为对其预测性能的度量。
度量损失的最常见方法之一是对各个残差求平方,求平方和,然后计算平均值。 对残差进行平方处理可以使计算基于绝对值(忽略差值是负还是正),并对较大的差值赋予较大的权重。 此指标称为均方误差。
对于我们的验证数据,计算结果如下所示:
| y | ŷ | y - ŷ | (y - ŷ)2 |
|---|---|---|---|
| 156 | 159.4 | -3.4 | 11.56 |
| 114 | 111.8 | 2.2 | 4.84 |
| 129 | 125.4 | 3.6 | 12.96 |
| Sum | ∑ | 29.36 | |
| 平均值 | x̄ | 9.79 |
因此,基于 MSE 指标的模型损失为 9.79。
那有什么好处吗? 很难判断,因为 MSE 值未用有意义的度量单位表示。 我们知道,该值越小,模型中的损失就越少,因此其预测效果就越好。 这使它成为了比较两个模型并找到性能最好的模型的有用指标。
有时,用与预测标签值本身相同的度量单位来表示损失更为有用,在本例中,为租赁数量。 为此,可以计算 MSE 的平方根,此操作必定会生成一个已知指标,即均方根误差 (RMSE)。
√9.79 = 3.13
因此,我们模型的 RMSE 表明损失刚超过 3,可以粗略地解释为,平均而言,错误预测的误差为大约 3 次租赁。
还有许多其他指标可用于度量回归中的损失。 例如,R2(R 平方)(有时称为确定系数),是 x 和 y 平方之间的相关性。 这会生成一个介于 0 和 1 之间的值,该值可测量模型可以解释的方差量。 通常,此值越接近 1,模型的预测效果就越好。