探索解决方案体系结构
让我们来修改机器学习操作 (MLOps) 体系结构,以了解我们尝试实现的目标。
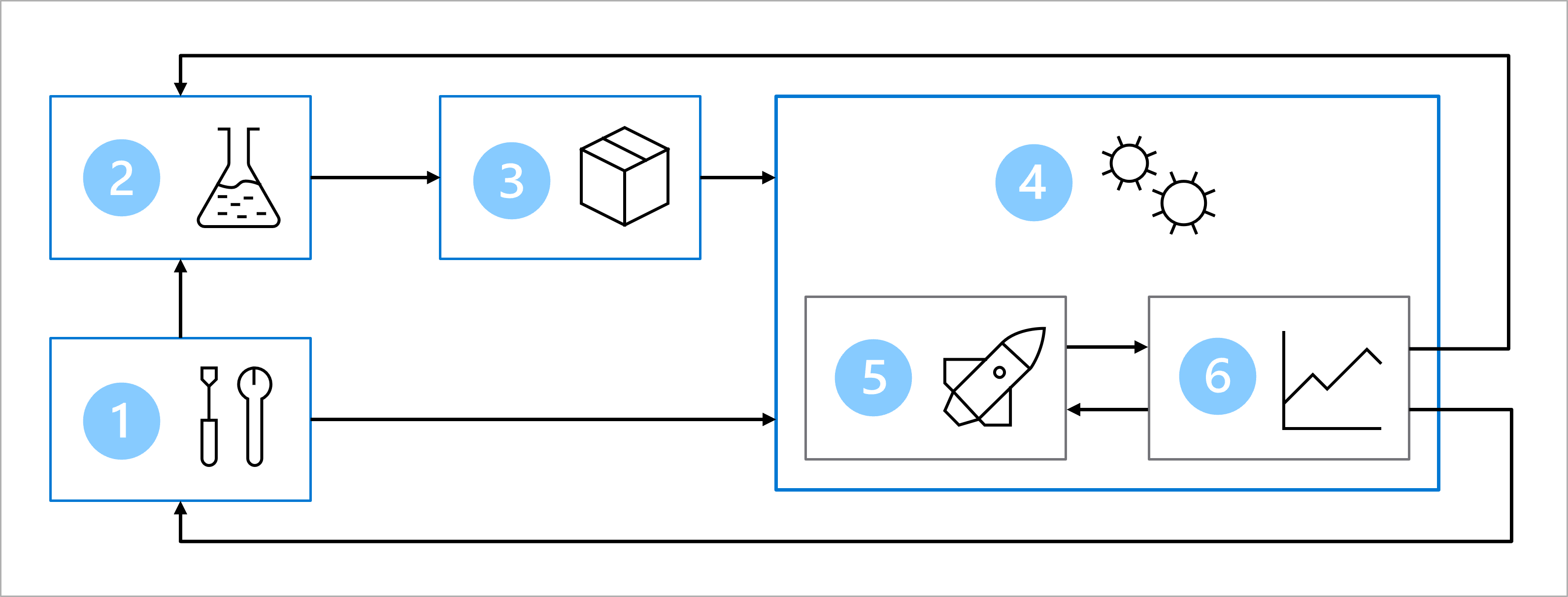
假设你与数据科学和软件开发团队一致同意使用以下体系结构来训练、测试和部署糖尿病分类模型:
注意
此图是 MLOps 体系结构的简化表示形式。 若要查看更详细的体系结构,请浏览 MLOps (v2) 解决方案加速器中的各种用例。
体系结构包括:
- 设置:为解决方案创建所有必需的 Azure 资源。
- 模型开发(内部循环):浏览并处理数据来训练和评估模型。
- 持续集成:打包并注册模型。
- 模型部署(外部循环):部署模型。
- 持续部署:测试模型并提升到生产环境。
- 监视:监视模型和终结点性能。
数据科学团队负责模型开发。 软件开发团队负责将部署的模型与从业者用来评估患者是否患有糖尿病的 Web 应用集成。 你负责执行模型的开发到部署阶段。
你希望数据科学团队不断提出针对用于训练模型的脚本的更改建议。 每当训练脚本发生更改时,你都需要重新训练模型并将模型重新部署到现有终结点。
你希望让数据科学团队能够在无需更改已准备好用于生产的代码的情况下进行试验。 你还希望确保任何新代码或更新的代码在通过质量检查后自动获得同意。 验证用于训练模型的代码后,你将使用更新的训练脚本来训练新模型并对其进行部署。
若要在更新生产代码之前跟踪更改并验证代码,则需要使用分支。 你与数据科学团队就此事项达成了一致:每次他们想要进行更改时,都需创建一个功能分支以创建代码副本,并对该副本进行更改。
任何数据科学家都可以创建功能分支并在其中进行操作。 在他们更新代码并希望将该代码作为新的生产代码后,必须创建一个拉取请求。 在拉取请求中,建议的更改将对其他人员可见,使其他人员有机会查看和讨论这些更改。
每当创建拉取请求时,你都希望自动检查代码是否正常工作,以及代码的质量是否符合组织的标准。 代码通过质量检查后,首席数据科学家需要查看更改并批准更新,然后才能合并拉取请求,并相应地更新主分支中的代码。
重要
不应允许任何人将更改推送到主分支。 为了保护代码(尤其是生产代码),你需要强制要求只能通过需要获得批准的拉取请求来更新主分支。