排查似乎永远不会以SQL Server结束的查询
本文介绍以下问题的故障排除步骤:查询似乎从未完成,或者完成该查询可能需要数小时或数天。
什么是永无止境的查询?
本文档重点介绍继续执行或编译的查询,即其 CPU 继续增加。 它不适用于被阻止或等待某些资源( (CPU 保持不变或) 变化很少)的查询。
重要
如果保留查询以完成其执行,它将最终完成。 它可能需要几秒钟,或者可能需要几天时间。
术语永无止境用于描述当查询最终完成时查询未完成的感觉。
标识永无止境的查询
若要确定查询是持续执行还是停滞在瓶颈上,请执行以下步骤:
运行以下查询:
DECLARE @cntr int = 0 WHILE (@cntr < 3) BEGIN SELECT TOP 10 s.session_id, r.status, r.wait_time, r.wait_type, r.wait_resource, r.cpu_time, r.logical_reads, r.reads, r.writes, r.total_elapsed_time / (1000 * 60) 'Elaps M', SUBSTRING(st.TEXT, (r.statement_start_offset / 2) + 1, ((CASE r.statement_end_offset WHEN -1 THEN DATALENGTH(st.TEXT) ELSE r.statement_end_offset END - r.statement_start_offset) / 2) + 1) AS statement_text, COALESCE(QUOTENAME(DB_NAME(st.dbid)) + N'.' + QUOTENAME(OBJECT_SCHEMA_NAME(st.objectid, st.dbid)) + N'.' + QUOTENAME(OBJECT_NAME(st.objectid, st.dbid)), '') AS command_text, r.command, s.login_name, s.host_name, s.program_name, s.last_request_end_time, s.login_time, r.open_transaction_count, atrn.name as transaction_name, atrn.transaction_id, atrn.transaction_state FROM sys.dm_exec_sessions AS s JOIN sys.dm_exec_requests AS r ON r.session_id = s.session_id CROSS APPLY sys.Dm_exec_sql_text(r.sql_handle) AS st LEFT JOIN (sys.dm_tran_session_transactions AS stran JOIN sys.dm_tran_active_transactions AS atrn ON stran.transaction_id = atrn.transaction_id) ON stran.session_id =s.session_id WHERE r.session_id != @@SPID ORDER BY r.cpu_time DESC SET @cntr = @cntr + 1 WAITFOR DELAY '00:00:05' END检查示例输出。
当你注意到类似于以下输出的输出时,本文中的故障排除步骤特别适用,其中 CPU 正随着运行时间成比例地增加,而没有长时间等待。 请务必注意,在这种情况下,中的
logical_reads更改并不相关,因为某些受 CPU 限制的 T-SQL 请求可能根本不执行任何逻辑读取 (例如执行计算或WHILE循环) 。session_id status cpu_time logical_reads wait_time wait_type 56 运行 7038 101000 0 NULL 56 可运行 12040 301000 0 NULL 56 运行 17020 523000 0 NULL 如果观察到类似于以下的等待方案,其中 CPU 不会发生细微变化或变化,并且会话正在等待资源,则本文不适用。
session_id status cpu_time logical_reads wait_time wait_type 56 已挂起 0 3 8312 LCK_M_U 56 已挂起 0 3 13318 LCK_M_U 56 已挂起 0 5 18331 LCK_M_U
有关详细信息,请参阅 诊断等待或瓶颈。
编译时间长
在极少数情况下,你可能会观察到 CPU 会随着时间的推移而持续增加,但这不是由查询执行驱动的。 相反,它可能由过长的编译驱动, (查询) 的分析和编译。 在这些情况下,检查transaction_name输出列并查找 值sqlsource_transform。 此事务名称指示编译。
收集诊断数据
- SQL Server 2008 - sp2) 之前的 SQL Server 2014 (
- sp2) 之后SQL Server 2014 (2014 SQL Server 2016 (sp1)
- SP1) 和 2017 SQL Server 之后SQL Server 2016 (
- SQL Server 2019 及更高版本
若要使用 SQL Server Management Studio ( SSMS) 收集诊断数据,请执行以下步骤:
捕获 估计的查询执行计划 XML。
查看查询计划,看看是否有任何明显的迹象表明速度缓慢可能来自何处。 典型示例包括:
- 表或索引扫描 (查看估计行) 。
- 由巨大的外部表数据集驱动的嵌套循环。
- 在循环的内侧具有大型分支的嵌套循环。
- 表假脱机。
SELECT列表中需要很长时间来处理每行的函数。
如果查询随时快速运行,则可以捕获要比较 的实际 XML 执行计划的 “快速”执行。
查看收集的计划的方法
本部分将说明如何查看收集的数据。 它将使用SQL Server 2016 SP1 及更高版本和版本中收集的扩展 *.sqlplan) (多个 XML 查询计划。
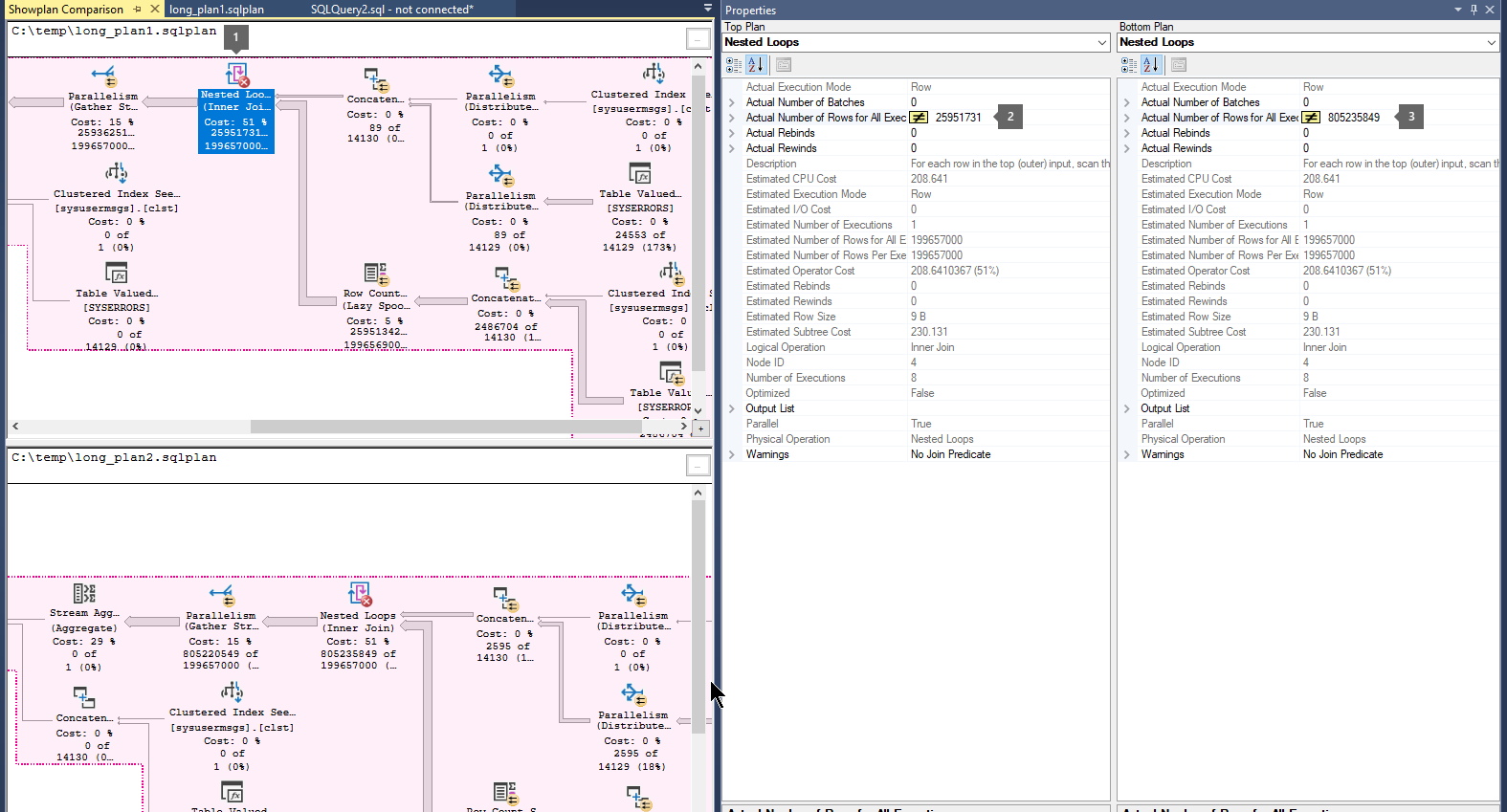
请按照以下步骤 比较执行计划:
(.sqlplan) 打开以前保存的查询执行计划文件。
右键单击执行计划的空白区域,然后选择“ 比较显示计划”。
选择要比较的第二个查询计划文件。
查找指示大量行在运算符之间流动的粗箭头。 然后选择箭头之前或之后的运算符,并比较两个计划 的实际 行数。
比较第二个和第三个计划,以确定最大的行流是否在同一运算符中发生。
下面是一个示例:

解决方案
确保更新查询中使用的表的统计信息。
在查询计划中查找缺少的索引建议并应用任何索引。
重写查询,以简化查询:
- 使用更具选择性
WHERE的谓词来减少预先处理的数据。 - 把它拆开。
- 在临时表中选择一些部件,稍后再联接它们。
- 在
TOP由于优化器行目标而长时间运行的查询中删除 、EXISTS和FAST(T-SQL) 。 或者,可以使用提示DISABLE_OPTIMIZER_ROWGOAL。 有关详细信息,请参阅行Goals消失的流氓。 - 在将语句合并为单个大查询时,避免使用通用表表达式 (CTE) 。
- 使用更具选择性
尝试使用 查询提示 生成更好的计划:
HASH JOIN或MERGE JOIN提示FORCE ORDER提示FORCESEEK提示RECOMPILE- 如果你有一个可强制执行的快速查询计划,请使用
PLAN N'<xml_plan>'
查询存储 (QDS) ,如果存在此类计划,并且SQL Server版本支持查询存储,请使用强制实施一个良好的已知计划。
诊断等待或瓶颈
此处包含此部分作为参考,以防你的问题不是长时间运行的 CPU 驱动查询。 可以使用它来排查由于等待时间过长而导致的查询。
若要优化等待瓶颈的查询,请确定等待时间以及瓶颈 (等待类型) 的位置。 确认 等待类型 后,请减少等待时间或完全消除等待。
若要计算近似等待时间,请从查询的运行时间中减去 CPU 时间 (辅助角色时间) 。 通常,CPU 时间是实际执行时间,查询生存期的剩余部分正在等待。
有关如何计算近似等待持续时间的示例:
| 运行时间 (ms) | cpu time (ms) | 等待时间 (ms) |
|---|---|---|
| 3200 | 3000 | 200 |
| 7080 | 1000 | 6080 |
确定瓶颈或等待
若要识别历史长时间等待查询 (例如, >总运行时间的 20% 是等待时间) ,请运行以下查询。 此查询使用自SQL Server开始以来缓存查询计划的性能统计信息。
SELECT t.text, qs.total_elapsed_time / qs.execution_count AS avg_elapsed_time, qs.total_worker_time / qs.execution_count AS avg_cpu_time, (qs.total_elapsed_time - qs.total_worker_time) / qs.execution_count AS avg_wait_time, qs.total_logical_reads / qs.execution_count AS avg_logical_reads, qs.total_logical_writes / qs.execution_count AS avg_writes, qs.total_elapsed_time AS cumulative_elapsed_time FROM sys.dm_exec_query_stats qs CROSS apply sys.Dm_exec_sql_text (sql_handle) t WHERE (qs.total_elapsed_time - qs.total_worker_time) / qs.total_elapsed_time > 0.2 ORDER BY qs.total_elapsed_time / qs.execution_count DESC若要确定等待时间超过 500 毫秒的当前正在执行的查询,请运行以下查询:
SELECT r.session_id, r.wait_type, r.wait_time AS wait_time_ms FROM sys.dm_exec_requests r JOIN sys.dm_exec_sessions s ON r.session_id = s.session_id WHERE wait_time > 500 AND is_user_process = 1如果可以收集查询计划,检查 SSMS 中的执行计划属性中的 WaitStats:
- 运行包含 实际执行 计划的查询。
- 右键单击“ 执行计划 ”选项卡中最左侧的运算符
- 选择 “属性” ,然后选择 “WaitStats 属性”。
- 检查 WaitTimeMs 和 WaitType。
如果熟悉 PSSDiag/SQLdiag 或 SQL LogScout LightPerf/GeneralPerf 方案,请考虑使用其中任一方案来收集性能统计信息,并确定SQL Server实例上的等待查询。 可以导入收集的数据文件,并使用 SQL Nexus 分析性能数据。
帮助消除或减少等待的引用
每种等待类型的原因和解决方法各不相同。 没有一种常规方法可以解决所有等待类型。 下面是排查和解决常见等待类型问题的文章:
- 了解并解决 (LCK_M_*) 阻塞性问题
- 了解并解决Azure SQL数据库阻塞问题
- 排查 I/O 问题导致的SQL Server性能缓慢 (PAGEIOLATCH_*、WRITELOG、IO_COMPLETION、BACKUPIO)
- 解决SQL Server中最后一页插入PAGELATCH_EX争用问题
- 内存授予解释和解决方案 (RESOURCE_SEMAPHORE)
- 排查ASYNC_NETWORK_IO等待类型导致查询速度缓慢的问题
- 排查Always On可用性组的高HADR_SYNC_COMMIT等待类型问题
- 工作原理:CMEMTHREAD 和调试
- 使并行度 (CXPACKET 和 CXCONSUMER)
- THREADPOOL 等待
有关许多 Wait 类型的说明及其指示的内容,请参阅 “等待类型”中的表。
反馈
即将发布:在整个 2024 年,我们将逐步淘汰作为内容反馈机制的“GitHub 问题”,并将其取代为新的反馈系统。 有关详细信息,请参阅:https://aka.ms/ContentUserFeedback。
提交和查看相关反馈