測試您的模型
成功訓練模型之後,您可以使用翻譯來評估模型的品質。 若要做出使用標準模型還是自訂模型的明智決策,您應該評估自訂模型 BLEU 分數與標準模型「基準 BLEU」之間的差異。 如果您的模型是在較窄的領域中訓練,且您的訓練資料與測試資料相一致,則可期待會得到較高的 BLEU 分數。
BLEU 分數
BLEU (雙語評估替補) 是一種演算法,可用來評估從某種語言翻譯為另一種語言的文字精確度或正確性。 自訂翻譯工具使用 BLEU 計量作為傳達翻譯正確性的一種方式。
BLEU 分數是介於零到 100 之間的數字。 分數零指出低品質翻譯,其中翻譯中沒有任何項目符合參考。 分數 100 指出與參考完全相同的完美翻譯。 不需要取得分數 100:BLEU 40 到 60 之間的分數指出高品質翻譯。
模型詳細資料
選取 [模型詳細資料] 刀鋒視窗。
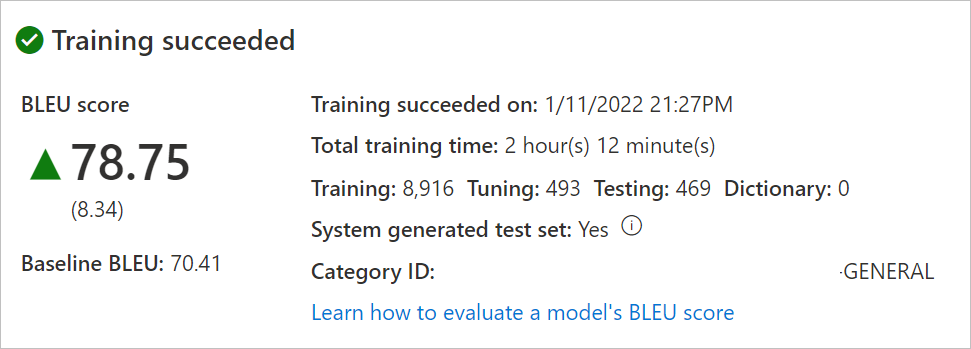
選取模型名稱。 檢閱訓練日期/時間、總訓練時間,以及用於訓練、微調、測試和字典的句子數目。 檢查系統是否已產生測試和微調集。 使用
Category ID進行翻譯要求。評估模型 BLEU 分數。 檢閱測試集:[BLEU 分數] 是自訂訓練分數,而 [基準 BLEU] 是用於自訂的預先訓練基準模型。 較高的 [BLEU 分數] 表示使用自訂模型可具有較高的翻譯品質。
測試模型的翻譯品質
選取 [測試模型] 刀鋒視窗。
選取模型 [名稱]。
人類針對 [參考] (測試集的目標翻譯),從 [自訂模型] 和 [基準模型] (用於自訂的預先訓練基準) 進行翻譯評估。
如果對訓練結果感到滿意,請為訓練的模型提出部署要求。
下一步
- 了解如何發佈/部署自訂模型。
- 了解如何使用自訂模型來翻譯文件。