Azure SQL Database 中的資源管理
適用於:![]() Azure SQL 資料庫
Azure SQL 資料庫
本文提供 Azure SQL Database 中資源管理的概觀。 其會提供達到資源限制時所發生情況的相關資訊,並描述用來強制執行這些限制的資源治理機制。
如需了解單一資料庫每個定價層的特定資源限制,請參閱
如需了解彈性集區資源限制,請參閱:
如需了解 Azure Synapse Analytics 專用 SQL 集區限制,請參閱:
各區域訂用帳戶虛擬核心限制
2024 年 3 月起,訂用帳戶每個訂用帳戶的每個區域都有下列虛擬核心限制:
| 訂用帳戶類型 | 預設虛擬核心限制 |
|---|---|
| Enterprise 合約 (EA) | 2000 |
| 免費試用 | 10 |
| Microsoft for Startups | 100 |
| MSDN / MPN / Imagine / AzurePass / Azure for Students | 40 |
| 隨用隨付 (PAYG) | 150 |
請考慮下列事項:
- 這些限制適用於新的和現有的訂用帳戶。
- 使用 DTU 購買模型 佈建的資料庫和彈性集區計入虛擬核心配額,反之亦然。 使用的每個虛擬核心都相當於伺服器層級配額所使用的 100 個 DTU。
- 預設限制包括針對已佈建的計算資料庫/彈性集區所設定的虛擬核心,以及針對無伺服器資料庫設定的最大虛擬核心。
- 您可以使用訂用帳戶使用量 - 取得 REST API 呼叫,判斷訂用帳戶目前的虛擬核心使用量。
- 若要要求比預設值高的虛擬核心配額,請在 Azure 入口網站提交新的支援要求。 如需詳細資訊,請參閱要求增加 Azure SQL Database 配額。
邏輯伺服器限制
| 資源 | 限制 |
|---|---|
| 每一邏輯伺服器的資料庫 | 5000 |
| 區域中每個訂用帳戶的邏輯伺服器預設數目 | 250 |
| 區域中每個訂用帳戶的邏輯伺服器數目上限 | 250 |
| 每一邏輯伺服器的彈性集區數目上限 | 受限於 DTU 或 vCore 數目。 例如,如果每個集區是 1000 DTU,則伺服器可以支援 54 集區。 |
重要
每當資料庫數量接近每部邏輯伺服器的限制時,可能會出現下列情況:
- 使用
master資料庫執行查詢時,延遲狀況增加。 這包含資源使用率統計資料的檢視,例如sys.resource_stats。 - 管理作業以及涉及列舉伺服器中資料庫入口網站檢視點的轉譯作業,皆增加延遲狀況。
達到資料庫資源限制時會發生什麼情況
計算 CPU
當資料庫計算 CPU 使用率變高時,查詢延遲會增加,而且查詢甚至可能逾時。在這些情況下,查詢可能會由服務排入佇列,並在資源可用時提供資源以執行。
如果觀察到高計算使用率,緩和選項包括:
儲存體
當使用的資料空間達到資料庫層級或彈性集區層級的資料大小上限時,插入及更新會增加資料大小失敗,而用戶端會收到錯誤訊息。 SELECT 和 DELETE 陳述式不會受到影響。
在進階版與業務關鍵服務層級中,若單一資料庫或彈性集區的資料、交易記錄與 tempdb 所消耗的合併儲存體超過本機儲存體大小上限,則用戶端也會收到錯誤訊息。 如需詳細資訊,請參閱儲存體空間管理。
如果觀察到高儲存空間使用率,緩和選項包括:
- 增加資料庫或彈性集區的資料大小上限,或擴大至具有較高資料大小上限的服務目標。 請參閱調整單一資料庫資源和調整彈性集區資源。
- 若資料庫在彈性集區中,則也可將其移出集區,如此便不會與其他資料庫共用其儲存空間。
- 壓縮資料庫以回收未使用的空間。 如需其他資訊,請參閱 管理 Azure SQL 資料庫中的檔案空間。
- 在彈性集區中,壓縮資料庫可為集區中的其他資料庫提供更多儲存體。
- 檢查高空間使用率是否肇因於持續版本存放區 (PVS) 的大小激增。 PVS 是每個資料庫的一部分,用來實作加速資料庫復原。 若要判斷目前的 PVS 大小,請參閱 PVS 疑難排解。 大型 PVS 大小的常見原因是長時間 (數小時) 開啟的交易,這會防止清除 PVS 中較舊的資料列版本。
- 針對進階版與業務關鍵服務層級中消耗大量儲存體的資料庫與彈性集區,您可能會收到空間不足的錯誤,即使資料庫或彈性集區中的已使用空間低於其資料大小上限。 若
tempdb或交易記錄檔消耗大量儲存體,並即將達到本機儲存體上限時,便可能發生此情況。 容錯移轉資料庫或彈性集區,以將tempdb重設為其較小的初始大小,或是壓縮交易記錄以減少本機儲存體耗用量。
工作階段、背景工作角色和要求
工作階段、背景工作角色和要求的定義如下:
- 工作階段代表連線到資料庫引擎的流程。
- 要求是查詢或批次的邏輯表示法。 要求是由連線至工作階段的用戶端所發出。 經過一段時間後,可在相同的工作階段上發出多個要求。
- 背景工作執行緒 (也稱為背景工作角色或執行緒) 是作業系統執行緒的邏輯表示法。 使用平行查詢執行計畫執行時,一個要求會具有許多背景工作角色,或使用序列 (單一執行緒) 執行計畫執行時,具有單一背景工作角色。 背景工作角色也需要支援要求以外的活動:例如,背景工作角色需要在工作階段連線時處理登入要求。
如需這些概念的詳細資訊,請參閱執行緒和工作架構指南。
背景工作角色的數量上限取決於服務層級和計算大小。 達到工作階段或背景工作角色的限制時,會拒絕新要求,而且用戶端會收到錯誤訊息。 雖然應用程式能控制連線數目,但並行背景工作角色的數目通常難以估計及控制。 特別是在尖峰負載期間,資料庫資源達到上限,背景工作角色也由於長時間執行的查詢、大型封鎖鏈或過度的查詢平行處理原則而不斷累積。
注意
Azure SQL Database 的初始供應項目僅支援單一執行緒查詢。 在那時,要求數目一律等於背景工作角色數目。 Azure SQL Database 中的錯誤訊息 10928 只包含僅供回溯相容性用途的訊息 The request limit for the database is *N* and has been reached。 達到的限制實際上是背景工作角色數目。
如果平行處理原則的最大程度 (MAXDOP) 設定等於零或大於一,則背景工作數目會遠高於要求數目,而且比 MAXDOP 等於一時更快達到限制。
- 深入了解資源治理錯誤中的錯誤 10928。
- 深入了解錯誤 10928 和 10936 中的要求限制耗盡。
您可以透過下列方式緩解接近或達到背景工作角色或工作階段限制:
- 提高資料庫或彈性集區的服務層級或計算大小。 請參閱調整單一資料庫資源和調整彈性集區資源。
- 如果背景工作角色數目的增加是由於競爭計算資源所致,最佳化查詢可降低資源使用率。 如需詳細資訊,請參閱查詢微調/提示。
- 最佳化查詢工作負載可減少發生次數和查詢封鎖的持續時間。 如需詳細資訊,請參閱了解並解決 Azure SQL 封鎖問題。
- 如果適當,請減少 MAXDOP 設定。
依服務層級和計算大小尋找 Azure SQL Database 的背景工作角色和工作階段限制:
深入了解在資源治理錯誤中針對工作階段或背景工作角色限制的特定錯誤進行疑難排解。
外部連線
透過 sp_invoke_external_rest_endpoint 建立的外部端點並行連線數上限為背景工作執行緒數的 10%,而背景工作角色的固定上限為 150。
記憶體
不同於其他資源不同 (CPU、背景工作角色、儲存體),達到記憶體限制並不會對查詢效能造成負面影響,也不會導致錯誤和失敗。 如記憶體管理架構指南所詳述,資料庫引擎通常會依設計使用所有可用的記憶體。 記憶體主要用於快取資料,以避免較慢的儲存體存取速度。 因此,較高的記憶體使用率通常可改善查詢效能,因為從記憶體進行較快的讀取,而不是從儲存體進行較慢的讀取。
在資料庫引擎啟動之後,當工作負載開始從儲存體讀取資料時,資料庫引擎會積極地快取記憶體中的資料。 在這個初始加速期間之後,通常預期會看到 sys.dm_db_resource_stats 中的 avg_memory_usage_percent 和 avg_instance_memory_percent 資料行,並且 sql_instance_memory_percent Azure 監視器計量接近於 100% (特別是非閒置的資料庫),而且不會完全納入記憶體中。
注意
sql_instance_memory_percent 計量會反映資料庫引擎的總記憶體使用量。 即使執行高強度的工作負載,此計量也可能無法達到 100%。 這是因為小部分的可用記憶體會保留給資料快取以外的重要記憶體配置,例如執行緒堆疊和可執行模組。
除了資料快取之外,還會在資料庫引擎的其他元件中使用記憶體。 在出現使用記憶體的需求,且資料快取使用了所有可用的記憶體時,資料庫引擎就會減少資料快取大小,讓記憶體可供其他元件使用,並在其他元件釋出記憶體時,動態增長資料快取。
在罕見的情況下,充分要求的工作負載可能會導致記憶體不足的狀況,進而造成記憶體不足的錯誤。 記憶體不足錯誤會發生在 0% 與 100% 之間的任何記憶體使用率層級。 記憶體不足錯誤更有可能發生在較小的計算大小中,它們具有按比例的較小記憶體限制,以及/或使用更多記憶體來進行查詢處理的工作負載,例如在密集彈性集區中。
如果遇到記憶體不足錯誤,緩解選項包含:
- 檢閱 sys.dm_os_out_of_memory_events 中的 OOM 條件詳細資料。
- 提高資料庫或彈性集區的服務層級或計算大小。 請參閱調整單一資料庫資源和調整彈性集區資源。
- 最佳化查詢和設定可減少記憶體使用率。 下表描述常用的解決方案。
| 解決方法 | 描述 |
|---|---|
| 減少記憶體授與的大小 | 如需記憶體授與的詳細資訊,請參閱了解 SQL Server 記憶體授與部落格文章。 避免過度大量記憶體授與的常用解決方案,是將統計資料保持最新狀態。 這樣就能更精確地估計查詢引擎的記憶體耗用量,以避免大量記憶體授與。 根據預設,在使用相容性層級 140 及以上的資料庫中,資料庫引擎會使用批次模式記憶體授與意見反應,自動調整記憶體授與大小。 同樣地,在使用相容性層級 150 及以上的資料庫中,資料庫引擎也會使用資料列模式記憶體授與意見反應,以進行更常見的資料列模式查詢。 這項內建功能可協助避免由於大量記憶體授與,而發生記憶體不足的錯誤。 |
| 減少查詢計劃快取的大小 | 資料庫引擎會在記憶體中快取查詢計劃,以避免在執行每個查詢時編譯查詢計劃。 若要避免只使用一次的快取計畫所造成的查詢計畫快取膨脹,請務必使用參數化查詢,並考慮啟用 OPTIMIZE_FOR_AD_HOC_WORKLOADS 資料庫範圍設定。 |
| 減少鎖定記憶體的大小 | 資料庫引擎會使用記憶體來進行鎖定。 可能的話,請避免可能取得大量鎖定,並導致高鎖定記憶體耗用量的大型交易。 |
使用者工作負載和內部流程的資源使用量
Azure SQL Database 需要計算資源來實作核心服務功能,例如高可用性和災害復原、資料庫備份和還原、監視、查詢存放區、自動調整等等。系統會使用資源管理機制,針對這些內部流程騰出整體資源的有限部分,讓使用者工作負載可以使用其餘的資源。 當內部流程未使用計算資源時,系統會使它們可供使用者工作負載使用。
使用者工作負載和內部流程的 CPU 和記憶體耗用量總計,會在 sys.dm_db_resource_stats 和 sys.resource_stats 檢視的 avg_instance_cpu_percent 和 avg_instance_memory_percent 資料行中報告。 對於集區層級的單一資料庫和彈性集區,也會透過 sql_instance_cpu_percent 和 sql_instance_memory_percent Azure 監視器計量報告此資料。
注意
sql_instance_cpu_percent 和 sql_instance_memory_percent Azure 監視器計量自 2023 年 7 月起可供使用。 它們完全相當於先前可用的 sqlserver_process_core_percent 和 sqlserver_process_memory_percent 計量。 後兩個計量仍可供使用,但未來將會被移除。 若要避免資料庫監視中斷,請勿使用較舊的計量。
這些計量不適用於使用基本、S1 和 S2 服務目標的資料庫。 下列參考的動態管理檢視中提供相同的資料。
每個資料庫中使用者工作負載的 CPU 和記憶體耗用量,會在 sys.dm_db_resource_stats 和 sys.resource_stats 檢視的 avg_cpu_percent 和 avg_memory_usage_percent 資料行中報告。 針對彈性集區,集區層級資源耗用量會在 sys.elastic_pool_resource_stats 檢視中回報 (記錄報告案例),並以 sys.dm_elastic_pool_resource_stats 回報以供即時監視。 對於集區層級的單一資料庫和彈性集區,也會透過 cpu_percent Azure 監視器計量報告使用者工作負載 CPU 耗用量。
使用者工作負載和內部流程最近資源耗用量的更詳細明細,會在 sys.dm_resource_governor_resource_pools_history_ex 和 sys.dm_resource_governor_workload_groups_history_ex 檢視中報告。 如需這些檢視所參考資源集區和工作負載群組的詳細資料,請參閱資源治理。 這些檢視會報告使用者工作負載的資源使用率,以及相關聯資源集區和工作負載群組中的特定內部流程。
提示
在監視工作負載效能疑難排解時,請務必同時考慮使用者工作負載和內部流程 (avg_instance_cpu_percent、sql_instance_cpu_percent) 的使用者 CPU 耗用量 (avg_cpu_percent、cpu_percent) 和 CPU 耗用量總計。 如果其中一個計量落在 70-100% 範圍內,則效能可能會受到顯著影響。
使用者 CPU 使用量被定義為每個服務目標中的使用者工作負載 CPU 限制百分比。 同樣,總計 CPU 使用量被定義為所有工作負載的 CPU 限制百分比。 由於這兩個限制不同,因此使用者和總計 CPU 使用量會以不同的規模來測量,而且彼此不直接比較。
如果使用者 CPU 使用量達到 100%,表示使用者工作負載會完全使用它在所選服務目標中可用的 CPU 容量,即使總計 CPU 使用量仍低於 100%。
當總計 CPU 使用量達到 70%-100% 範圍時,即使使用者 CPU 使用量仍明顯低於 100%,仍可以看到使用者工作負載輸送量持平且查詢延遲增加。 使用較小的服務目標搭配中等配置的計算資源,但相對密集的使用者工作負載 (例如在 密集彈性集區中) 時,更有可能發生這種情況。 當內部流程暫時需要額外的資源時 (例如,在建立資料庫的新複本或備份資料庫時),較小的服務目標也會發生這種情況。
同樣,當使用者 CPU 使用量達到 70%-100% 範圍時,使用者工作負載輸送量將持平,而且查詢延遲也會增加,即使總計 CPU 使用量遠低於其限制。
當使用者 CPU 使用量或總計 CPU 使用量很高時,緩解選項與計算 CPU 區段中所述的相同,並包含服務目標增加及/或使用者工作負載最佳化。
注意
即使在完全閑置的資料庫或彈性集區上,由於背景資料庫引擎活動,總計 CPU 使用量絕不為零。 視特定背景活動、計算大小和先前的使用者工作負載而定,它可以在廣泛的範圍內波動。
資源管理
為了強制執行資源限制,Azure SQL Database 會使用以 SQL Server Resource Governor 為基礎的資源治理實作,同時已將其修改並擴充至可在雲端中執行。 在 SQL Database 中,多個資源集區和工作負載群組 (同時在集區和群組層級設定資源限制) 提供平衡的資料庫即服務。 使用者工作負載和內部工作負載會分類為個別的資源集區和工作負載群組。 主要和可讀取次要複本 (包括異地複本) 上的使用者工作負載會分類為 SloSharedPool1 資源集區和 UserPrimaryGroup.DBId[N] 工作負載群組,其中 [N] 代表資料庫識別碼值。 此外,也有多個資源集區和工作負載群組適用於各種內部工作負載。
除了使用 Resource Governor 來治理資料庫引擎內的資源之外,Azure SQL Database 也會使用 Windows工作物件進行流程層級資源治理,以及使用 Windows File Server Resource Manager (FSRM) 進行儲存體配額管理。
Azure SQL Database 資源治理本質上是階層式治理。 從上到下,在作業系統層級和儲存體磁碟區層級,使用作業系統資源治理機制和 Resource Governor,接著在資源集區層級使用 Resource Governor,然後在工作負載群組層級使用 Resource Governor 來強制執行限制。 對於目前資料庫或彈性集區有效的資源治理限制,會在 sys.dm_user_db_resource_governance 檢視中報告。
資料 I/O 管理
資料 I/O 治理是 Azure SQL Database 中的流程,用來限制對資料庫資料檔案的讀取和寫入實體 I/O。 系統會針對每個服務等級設定 IOPS 限制,將「擾鄰」效果降至最低,以在多組織用戶共享服務提供資源分派公平性,並維持在基礎硬體效能和儲存體容量範圍內。
若為單一資料庫,工作負載群組限制會套用至針對資料庫的所有儲存體 I/O。 若為彈性集區,工作負載群組限制會套用至集區中的每個資料庫。 此外,資源集區限制會額外地套用至彈性集區的累計 I/O。 在 tempdb 中,I/O 會受到工作負載群組限制的影響,但基本、標準與一般用途服務層級除外,其中會套用較高的 tempdb I/O 限制。 一般而言,工作負載可能無法針對資料庫 (單一或集區) 達成資源集區限制,因為工作負載群組限制低於資源集區限制,且更快地限制 IOPS/輸送量。 不過,合併的工作負載可能會針對相同集區中的多個資料庫達到集區限制。
例如,如果查詢在沒有任何 I/O 資源管理的情況下產生 1000 IOPS,但工作負載群組的最大 IOPS 限制設定為 900 IOPS,則查詢不會產生超過 900 的 IOPS。 不過,如果資源集區的最大 IOPS 限制設定為 1500 IOPS,且所有與資源集區相關聯的工作負載群組的 I/O 總計超過 1500 IOPS,則系統可能減少相同查詢的 I/O,以低於 900 IOPS 的工作群組限制。
sys.dm_user_db_resource_governance 檢視所傳回的 IOPS 和輸送量最大值可充當限制/上限,但不會充當保證。 此外,資源治理不保證任何特定的儲存體延遲。 給定使用者工作負載最能實現的延遲、IOPS 和輸送量,不僅取決於 I/O 資源治理限制,也取決於混合使用的 I/O 大小,以及基礎儲存體的功能。 SQL Database 會使用大小介於 512 位元組與 4 MB 之間的 I/O 操作。 基於強制執行 IOPS 限制的目的,無論大小為何,都會計入每個 I/O,但具有 Azure 儲存體中資料檔案的資料庫除外。 在此情況下,大於 256 KB 的 IO 會以多個 256-KB I/O 計入,以與 Azure 儲存體 I/O 計入一致。
對於基本、標準和一般用途資料庫 (使用 Azure 儲存體中的資料檔案),如果資料庫沒有足夠的資料檔案,以累計方式提供此數量的 IOPS,或如果資料未平均分散於檔案之間,或如果基礎 Blob 的效能層級限制低於資源治理限制的 IOPS/輸送量,則可能無法達到 primary_group_max_io 值。 同樣,使用頻繁交易認可所產生的小型記錄 IO 操作時,由於基礎 Azure 儲存體 Blob 的 IOPS 限制,工作負載可能無法達到 primary_max_log_rate 值。 針對使用 Azure 進階儲存體的資料庫,Azure SQL Database 會使用夠大的儲存體 Blob 來取得所需的 IOPS/輸送量,不論資料庫大小為何。 針對較大的資料庫,系統會建立多個資料檔案,以增加 IOPS/輸送量容量總計。
資源使用率 (例如在 sys.dm_db_resource_stats、sys.resource_stats、sys.dm_elastic_pool_resource_stats 和 sys.elastic_pool_resource_stats 檢視中回報的 avg_data_io_percent 和 avg_log_write_percent) 計算是以資源治理上限的百分比表示。 因此,當資源治理以外的因素限制 IOPS/輸送量時,即使回報的資源使用率仍低於100%,還是可以在工作負載增加時,看到 IOPS/輸送量持平且延遲增加。
若要監視每個資料庫檔案的讀取和寫入 IOPS、輸送量和延遲,請使用 sys.dm_io_virtual_file_stats() 函數。 此函數會針對資料庫顯示所有 I/O (包含不計入 avg_data_io_percent 的背景 I/O),但會使用基礎儲存體的 IOPS 和輸送量,而且可能會影響觀察到的儲存體延遲。 此函數會分別在 io_stall_queued_read_ms 和 io_stall_queued_write_ms 資料行中,報告 I/O 資源治理針對讀取和寫入所引進的額外延遲。
交易記錄速率治理
交易記錄速率治理是 Azure SQL Database 中的流程,用來限制工作負載的高內嵌速率,例如大量插入、SELECT INTO 和索引建置。 這些限制是在記錄產生速率的次秒層級進行追蹤和強制執行,而不論可以針對資料檔案發出多少 IO,都會限制輸送量。 交易記錄產生速率目前以線性方式擴大到硬體相依和服務層級相依的點。
系統會設定記錄速率,如此它們即可在各種案例中實現和維持,而整體系統可以維護其功能,並將對使用者負載的影響降到最低。 記錄速率治理可確保交易記錄備份保持在已發佈的可復原性 SLA 內。 此治理也會防止次要複本上的過度待辦項目,這可能會在容錯移轉期間導致超過預期的停機。
系統不會治理或限制交易記錄檔的實際實體 IO。 產生記錄時,會評估和評量每項作業,其是否應該延遲,以便維持所需的最大記錄速率 (MB/每秒)。 當記錄排清至儲存體時,不會增加延遲,而是在本身產生記錄速率期間套用記錄速率治理。
在執行階段所加諸的實際記錄產生速率也會受到回饋機制影響,這時會暫時減少允許的記錄速率,讓系統可以穩定。 記錄檔空間管理,其會避免用光記錄空間的情況,而資料複寫機制可能會暫時降低整體系統限制。
記錄速率管理員流量成形是透過下列等候類型來呈現 (在 sys.dm_exec_requests 和 sys.dm_os_wait_stats 檢視中公開):
| 等候類型 | 備註 |
|---|---|
LOG_RATE_GOVERNOR |
資料庫限制 |
POOL_LOG_RATE_GOVERNOR |
集區限制 |
INSTANCE_LOG_RATE_GOVERNOR |
執行個體層級限制 |
HADR_THROTTLE_LOG_RATE_SEND_RECV_QUEUE_SIZE |
回饋控制,進階/業務關鍵中的可用性群組實體複寫未繼續進行 |
HADR_THROTTLE_LOG_RATE_LOG_SIZE |
回饋控制,限制速率以避免記錄空間不足的狀況 |
HADR_THROTTLE_LOG_RATE_MISMATCHED_SLO |
異地複寫回饋控制,限制記錄速率,以避免高資料延遲及避免無法使用異地次要資料庫 |
遇到阻礙所需可擴縮性的記錄速率限制時,請考慮下列選項:
- 擴大至較高的服務層級,以取得服務層級的最大記錄速率,或切換至不同的服務層級。 無論選擇的服務層級為何,超大規模資料庫服務層級都會為每個資料庫提供 100 MB/秒的記錄速率,為每個彈性集區提供 125 MB/秒的記錄速率。
- 若要載入的資料為暫時性 (例如 ETL 處理序中的臨時資料),則可將其載入至
tempdb(此為最低限度記錄)。 - 對於分析案例、載入至叢集資料行存放區資料表,或其索引使用資料壓縮的資料表。 這會減少所需的記錄速率。 這項技術會增加 CPU 使用率,而且只適用於可從叢集資料行存放區索引或資料壓縮獲益的資料集。
儲存體空間治理
在進階和業務關鍵服務層級中,客戶資料 (包含資料檔案、交易記錄檔和 tempdb 檔案) 會儲存在機器 (其中裝載資料庫或彈性集區) 的本機 SSD 儲存體上。 本機 SSD 儲存體提供高 IOPS 和輸送量,以及低 I/O 延遲。 除了客戶資料之外,本機儲存體還會用於作業系統、管理軟體、監視資料和記錄,以及系統作業所需的其他檔案。
本機儲存體大小是有限的,而且取決於硬體功能,這會決定本機儲存體上限,或是留給客戶資料的本機儲存體。 此限制的設定旨在最大化客戶資料儲存體,同時確保安全且可靠的系統操作。 若要尋找每個服務目標的最大本機儲存體值,請參閱單一資料庫和彈性集區的資源限制文件。
您也可以使用下列查詢來尋找此值,以及給定資料庫或彈性集區目前使用的本機儲存體數量:
SELECT server_name, database_name, slo_name, user_data_directory_space_quota_mb, user_data_directory_space_usage_mb
FROM sys.dm_user_db_resource_governance
WHERE database_id = DB_ID();
| 資料行 | 描述 |
|---|---|
server_name |
邏輯伺服器名稱 |
database_name |
資料庫名稱 |
slo_name |
服務目標名稱,包括硬體世代 |
user_data_directory_space_quota_mb |
最大本機儲存體 (以 MB 為單位) |
user_data_directory_space_usage_mb |
資料檔案、交易記錄檔與 tempdb 檔案目前的本機儲存體耗用量 (MB)。 每隔 5 分鐘更新一次。 |
此查詢應該在使用者資料庫中執行,而不是在 master 資料庫中執行。 若為彈性集區,可以在集區中的任何資料庫中執行查詢。 報告值適用於整個集區。
重要
在進階版與業務關鍵服務層級中,若工作負載嘗試將資料檔案、交易記錄檔與 tempdb 檔案所消耗的合併本機儲存體增加超過本機儲存體上限時,便會發生空間不足的錯誤。 即使資料庫檔案中的已使用空間尚未達到檔案的大小上限,也會發生這種情況。
除了進階版與業務關鍵的 tempdb 資料庫與超大規模 RBPEX 快取以外,服務層級的資料庫也會使用本機 SSD 儲存體。 建立及刪除資料庫,以及增加或減少其大小時,機器上的本機儲存體耗用量會隨時間波動。 如果系統偵測到機器上的可用本機儲存空間很低,而且資料庫或彈性集區有用光空間的風險,則它會將資料庫或彈性集區移至具有足夠可用本機儲存體的不同機器。
此移動會以連線方式進行,類似於資料庫調整作業,而且具有類似的影響,包括在作業結束時短暫的容錯移轉 (數秒)。 此容錯移轉會終止開啟的連線並復原交易,這可能會在當時使用資料庫影響應用程式。
因為將所有資料都複製到不同機器上的本機儲存體磁碟區,所以移動進階版與業務關鍵中較大的資料庫需要花費大量時間。 在此期間,若資料庫、彈性集區,或 tempdb 資料庫的本機空間耗用量快速增長,則空間不足的風險也會一同增加。 系統會以平衡方式起始資料庫移動,以將空間不足的錯誤減至最少,同時避免不必要的容錯移轉。
tempdb 大小
Azure SQL Database 中,tempdb 的大小限制取決於購買與部署模型。
若要深入了解,請檢閱下列項目的 tempdb 大小限制:
先前可用的硬體
本章節包含先前可用硬體的詳細資料。
- Gen4 硬體已淘汰,無法佈建、擴增或縮減。 將您的資料庫移轉至受支援的硬體世代,以獲得更廣泛的虛擬核心和儲存體擴充性、加速網路、最佳 IO 效能,以及最少的延遲。 如需詳細資訊,請參閱 Azure SQL 資料庫上對第 4 代硬體的支援已結束。
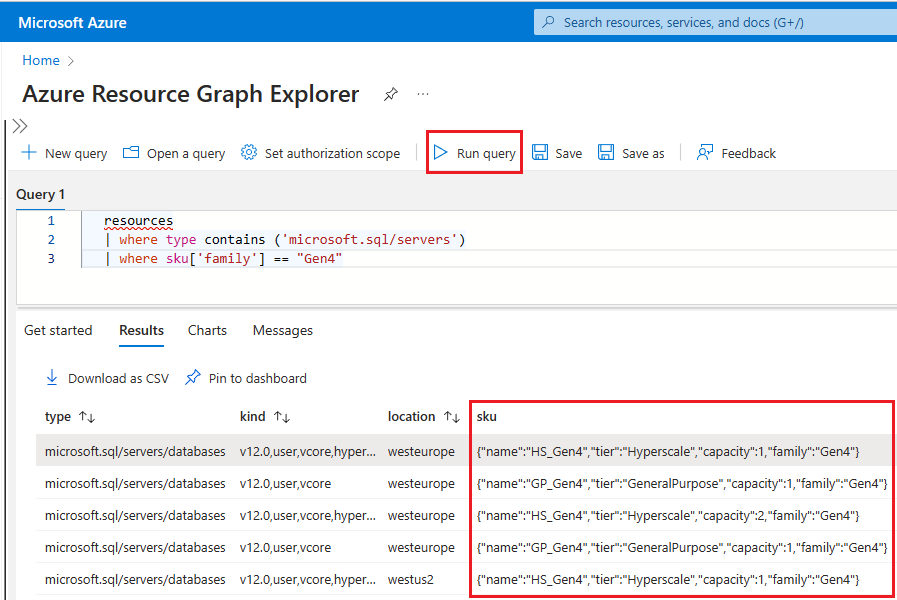
您可以使用 Azure Resource Graph Explorer 來識別目前使用 Gen4 硬體的所有 Azure SQL Database 資源,也可以檢查 Azure 入口網站中特定邏輯伺服器資源所使用的硬體。
您至少必須具有 Azure 物件或物件群組的 read 權限,才能在 Azure Resource Graph Explorer 中查看結果。
若要使用 Resource Graph Explorer 來識別仍在使用 Gen4 硬體的 Azure SQL 資源,請遵循下列步驟:
移至 Azure 入口網站。
在搜尋方塊中搜尋
Resource graph,然後從搜尋結果中選擇 [Resource Graph Explorer] 服務。在查詢視窗中,輸入下列查詢,然後選取 [執行查詢]:
resources | where type contains ('microsoft.sql/servers') | where sku['family'] == "Gen4"[結果] 窗格顯示 Azure 中使用 Gen4 硬體的所有目前已部署的資源。
若要檢查 Azure 中特定邏輯伺服器所使用的硬體,請遵循下列步驟:
- 移至 Azure 入口網站。
- 在搜尋方塊中搜尋
SQL servers,然後從搜尋結果中選擇 [SQL 伺服器],以開啟 [SQL 伺服器] 頁面並檢視所選訂用帳戶的所有伺服器。 - 選取感興趣的伺服器,以開啟伺服器的 [概觀] 頁面。
- 向下捲動至可用的資源,並檢查使用 gen4 硬體的資源所適用的 [定價層] 資料行。
![螢幕擷取畫面:Azure 中邏輯伺服器的 [概觀] 頁面,其中已選取 [概觀] 頁面並醒目提示 gen4。](../includes/media/identify-gen4-hardware/identify-gen4-hardware.png?view=azuresql)
若要將資源移轉至標準系列硬體,請檢閱變更硬體。
相關內容
- 如需一般 Azure 限制的相關資訊,請參閱 Azure 訂用帳戶和服務限制、配額及條件約束。
- 如需 DTU 與 eDTU 的相關資訊,請參閱 DTU 與 eDTU。
- 如需
tempdb大小限制的資訊,請參閱單一虛擬核心資料庫、集區虛擬核心資料庫、單一 DTU 資料庫,以及集區 DTU 資料庫。