在 Azure Databricks 上使用 Jenkins 進行 CI/CD
注意
本文涵蓋 Databricks 既不提供也不支援的 Jenkins。 若要連絡提供者,請參閱 Jenkins 說明。
有許多 CI/CD 工具可用來管理和執行 CI/CD 管線。 本文說明如何使用 Jenkins 自動化伺服器。 CI/CD 是一種設計模式,因此在其他各工具中使用本文所述的步驟和階段時,應對相應的管線定義語言進行一些變更。 此外,此範例管線中的大部分程式碼都執行標準 Python 程式碼 (可以在其他工具中叫用)。 如需 Azure Databricks 上的 CI/CD 概觀,請參閱什麼是 Azure Databricks 上的 CI/CD?。
如需有關改為將 Azure DevOps 與 Azure Databricks 搭配使用的資訊,請參閱使用 Azure DevOps 在 Azure Databricks 上進行持續整合和傳遞。
CI/CD 開發工作流程
Databricks 建議使用 Jenkins 進行下列 CI/CD 開發工作流程:
- 透過第三方 Git 供應商建立存放庫或使用現有存放庫。
- 將本機開發機器連線至相同的第三方存放庫。 如需指示,請參閱第三方 Git 供應商的文件。
- 將任何現有的已更新成品 (例如筆記本、程式碼檔案和組建指令碼) 從第三方存放庫向下提取到本機開發電腦上。
- 視需要,在本機開發電腦上建立、更新和測試成品。 然後將任何新的和已變更的成品從本機開發電腦推送到第三方存放庫。 如需指示,請參閱第第三方 Git 供應商的文件。
- 視需要重複步驟 3 和 4。
- 定期使用 Jenkins 作為整合方法,將成品從第三方存放庫自動向下提取到本機開發電腦或 Azure Databricks 工作區;在本機開發電腦或 Azure Databricks 工作區上組建、測試和執行程式碼;報告測試和執行結果。 雖然您可以手動執行 Jenkins,但在實際的實作中,您會指示第三方 Git 供應商在每次發生特定事件 (例如存放庫提取要求) 時執行 Jenkins。
本文的其餘部分使用範例專案來說明使用 Jenkins 實作上述 CI/CD 開發工作流程的一種方法。
如需有關使用 Azure DevOps 代替 Jenkins 的資訊,請參閱使用 Azure DevOps 在 Azure Databricks 上進行持續整合和傳遞。
本機開發電腦設定
本文的範例使用 Jenkins 指示 Databricks CLI 和 Databricks Asset Bundle 執行下列動作:
- 在本機開發電腦上組建 Python Wheel 檔案。
- 將組建的 Python Wheel 檔案以及其他 Python 檔案和 Python 筆記本從本機開發電腦部署至 Azure Databricks 工作區。
- 在該工作區中測試和執行上傳的 Python Wheel 檔案和筆記本。
若要設定本機開發電腦,以指示 Azure Databricks 工作區執行此範例的組建和上傳階段,請在本機開發電腦上執行下列動作:
步驟 1:安裝所需的工具
在此步驟中,您將在本機開發電腦上安裝 Databricks CLI、Jenkins、jq 和 Python Wheel 組建工具。 執行此範例需要這些工具。
安裝 Databricks CLI 0.205 或更新版本 (如果尚未安裝)。 Jenkins 使用 Databricks CLI 來傳遞此範例的測試並在工作區上執行指示。 請參閱安裝或更新 Databricks CLI。
安裝並啟動 Jenkins (如果尚未這麼做)。 請參閱安裝適用於 Linux、macOS 或 Windows 的 Jenkins。
安裝 jq。 此範例使用
jq來剖析一些 JSON 格式的命令輸出。使用
pip透過下列命令安裝 Python Wheel 組建工具 (某些系統可能需要您使用pip3而非pip):pip install --upgrade wheel
步驟 2:建立 Jenkins 管線
在此步驟中,您使用 Jenkins 為本文的範圍建立 Jenkins 管線。 Jenkins 提供了幾種不同的專案類型,以建立 CI/CD 管線。 Jenkins 管線提供了一個介面,用於透過使用 Groovy 程式碼呼叫和設定 Jenkins 外掛程式以定義 Jenkins 管線中的階段。
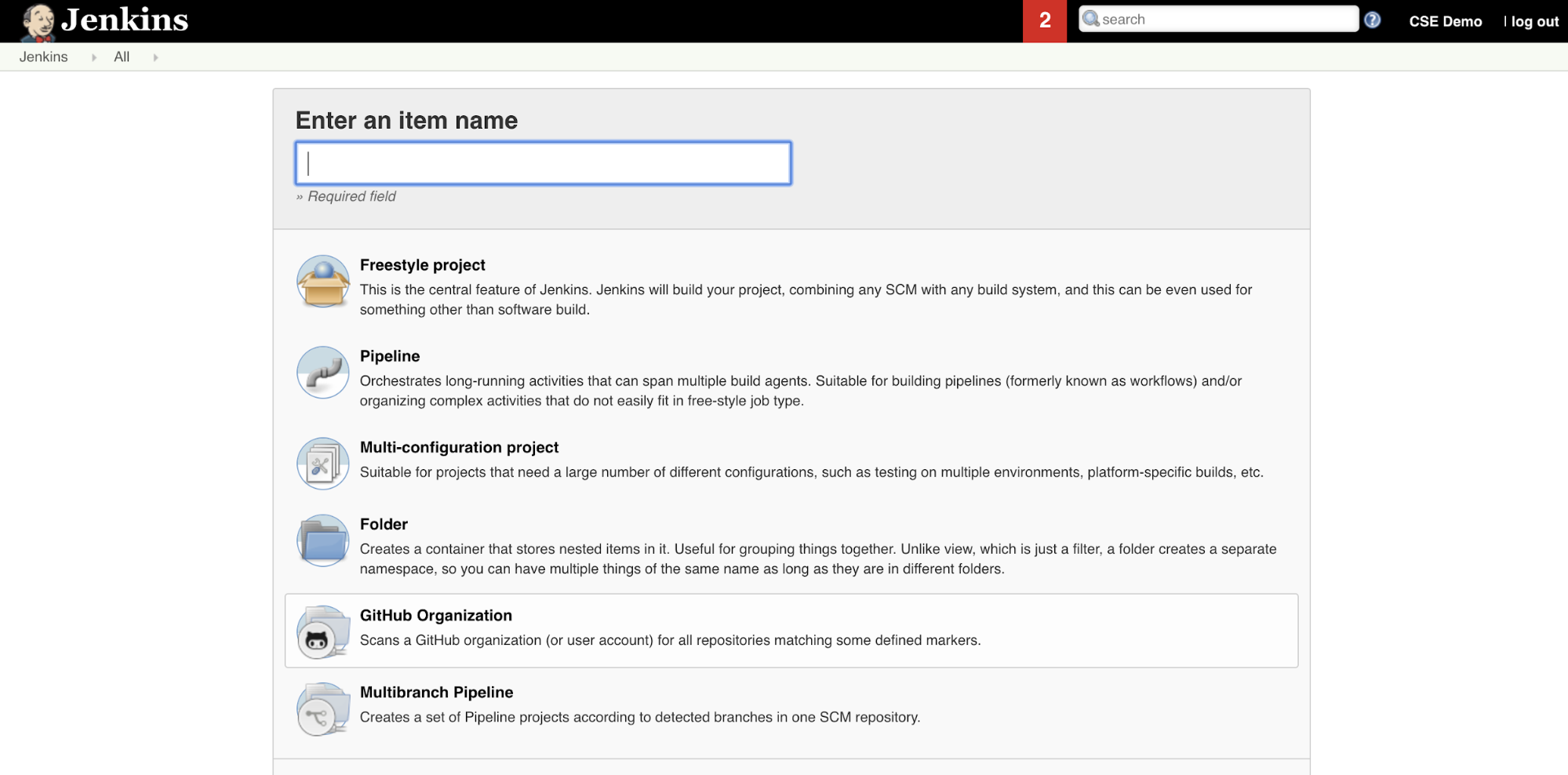
若要在 Jenkins 中建立 Jenkins 管線,請執行以下操作:
- 啟動 Jenkins 之後,從 Jenkins [儀表板] 中按一下 [新增項目]。
- 對於 [輸入項目名稱],鍵入 Jenkins 管線的名稱,例如
jenkins-demo。 - 按一下 [管線] 專案類型圖示。
- 按一下 [確定]。 Jenkins 管線的 [設定] 頁面隨即出現。
- 在 [管線] 區域中的 [定義] 下拉式清單中,選取 [SCM 中的管線指令碼]。
- 在 [SCM] 下拉式清單中,選取 [Git]。
- 對於 [存放庫 URL],鍵入協力廠商 Git 供應商託管的存放庫的 URL。
- 對於 [分支規範],鍵入
*/<branch-name>,其中<branch-name>是您要使用的存放庫中的分支名稱,例如*/main。 - 對於 [指令碼路徑],鍵入
Jenkinsfile(如果尚未設定)。 您將在本文稍後建立Jenkinsfile。 - 取消核取名為 [輕量型簽出] 的方塊 (如果已核取)。
- 按一下 [檔案] 。
步驟 3:將全域環境變數新增至 Jenkins
在此步驟中,您將三個全域環境變數新增至 Jenkins。 Jenkins 將這些環境變數傳遞給 Databricks CLI。 Databricks CLI 需要這些環境變數的值,才能向 Azure Databricks 工作區進行驗證。 此範例對服務主體使用 OAuth 電腦對電腦 (M2M) 驗證 (不過其他驗證類型也可用)。 若要為 Azure Databricks 工作區設定 OAuth M2M 驗證,請參閱使用 OAuth (OAuth M2M) 透過服務主體對 Azure Databricks 的存取進行驗證。
此範例的三個全域環境變數如下:
DATABRICKS_HOST,設定為您的 Azure Databricks 工作區 URL,以https://開頭。 請參閱工作區執行個體名稱、URL 和識別碼。DATABRICKS_CLIENT_ID,設定為服務主體的用戶端識別碼,也稱為應用程式識別碼。DATABRICKS_CLIENT_SECRET,設定為服務主體的 Azure Databricks OAuth 祕密。
若要在 Jenkins 中設定全域環境變數,請從 Jenkins [儀表板] 中:
- 在側邊欄中,按一下 [管理 Jenkins]。
- 在 [系統組態] 區段中,按一下 [系統]。
- 在 [全域屬性] 區段中,核取名為 [環境變數] 的方塊。
- 按一下 [新增],然後輸入環境變數的 [名稱] 和 [值]。 對每個額外的環境變數重複此動作。
- 當您完成新增環境變數時,按一下 [儲存] 以返回 Jenkins [儀表板]。
設計 Jenkins 管線
Jenkins 提供了幾種不同的專案類型,以建立 CI/CD 管線。 此範例實作 Jenkins 管線。 Jenkins 管線提供了一個介面,用於透過使用 Groovy 程式碼呼叫和設定 Jenkins 外掛程式以定義 Jenkins 管線中的階段。
將 Jenkins 管線定義寫入稱為 Jenkinsfile 的文字檔中,此檔案會簽入專案的原始檔控制存放庫中。 如需詳細資訊,請參閱 Jenkins 管線。 以下是本文範例的 Jenkins 管線。 在此範例 Jenkinsfile 中,取代下列預留位置:
- 將
<user-name>和<repo-name>取代為使用者名稱和協力廠商 Git 供應商託管的存放庫名稱。 本文使用 GitHub URL 作為範例。 - 將
<release-branch-name>取代為存放庫中發行分支的名稱。 例如,可以是main。 - 將
<databricks-cli-installation-path>取代為安裝 Databricks CLI 的本機開發電腦上的路徑。 例如,在 macOS 上,可以是/usr/local/bin。 - 將
<jq-installation-path>取代為安裝jq的本機開發電腦上的路徑。 例如,在 macOS 上,可以是/usr/local/bin。 - 將
<job-prefix-name>取代為一些字串,以協助唯一識別在此範例工作區中建立的 Azure Databricks 作業。 例如,可以是jenkins-demo。 - 請注意,
BUNDLETARGET已設定為dev,它是本文稍後定義的 Databricks Asset Bundle 目標的名稱。 在實際的實作中,您會將其變更為您自己的套件組合目標的名稱。 本文稍後會提供有關套件組合目標的更多詳細資料。
以下是 Jenkinsfile,其必須新增至存放庫的根目錄:
// Filename: Jenkinsfile
node {
def GITREPOREMOTE = "https://github.com/<user-name>/<repo-name>.git"
def GITBRANCH = "<release-branch-name>"
def DBCLIPATH = "<databricks-cli-installation-path>"
def JQPATH = "<jq-installation-path>"
def JOBPREFIX = "<job-prefix-name>"
def BUNDLETARGET = "dev"
stage('Checkout') {
git branch: GITBRANCH, url: GITREPOREMOTE
}
stage('Validate Bundle') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle validate -t ${BUNDLETARGET}
"""
}
stage('Deploy Bundle') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle deploy -t ${BUNDLETARGET}
"""
}
stage('Run Unit Tests') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle run -t ${BUNDLETARGET} run-unit-tests
"""
}
stage('Run Notebook') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle run -t ${BUNDLETARGET} run-dabdemo-notebook
"""
}
stage('Evaluate Notebook Runs') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle run -t ${BUNDLETARGET} evaluate-notebook-runs
"""
}
stage('Import Test Results') {
def DATABRICKS_BUNDLE_WORKSPACE_ROOT_PATH
def getPath = "${DBCLIPATH}/databricks bundle validate -t ${BUNDLETARGET} | ${JQPATH}/jq -r .workspace.file_path"
def output = sh(script: getPath, returnStdout: true).trim()
if (output) {
DATABRICKS_BUNDLE_WORKSPACE_ROOT_PATH = "${output}"
} else {
error "Failed to capture output or command execution failed: ${getPath}"
}
sh """#!/bin/bash
${DBCLIPATH}/databricks workspace export-dir \
${DATABRICKS_BUNDLE_WORKSPACE_ROOT_PATH}/Validation/Output/test-results \
${WORKSPACE}/Validation/Output/test-results \
-t ${BUNDLETARGET} \
--overwrite
"""
}
stage('Publish Test Results') {
junit allowEmptyResults: true, testResults: '**/test-results/*.xml', skipPublishingChecks: true
}
}
本文的其餘部分說明此 Jenkins 管線中的每個階段,以及如何設定 Jenkins 在該階段執行所需的成品和命令。
從第三方存放庫提取最新的成品
此 Jenkins 管線中的第一個階段 (Checkout 階段) 的定義如下:
stage('Checkout') {
git branch: GITBRANCH, url: GITREPOREMOTE
}
此階段可確保 Jenkins 在本機開發電腦上使用的工作目錄具有來自第三方 Git 存放庫的最新成品。 通常,Jenkins 會將此工作目錄設定為 <your-user-home-directory>/.jenkins/workspace/<pipeline-name>。 這可讓您在相同的本機開發電腦上,將您自己的開發成品複本與 Jenkins 使用的來自第三方 Git 存放庫的成品分開。
驗證 Databricks Asset Bundle
此 Jenkins 管線中的第二個階段 (Validate Bundle 階段) 的定義如下:
stage('Validate Bundle') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle validate -t ${BUNDLETARGET}
"""
}
此階段可確保用於測試和執行成品的工作流程的 Databricks Asset Bundle 在語法上正確無誤。 Databricks Asset Bundles,一般稱為套件組合,可讓您將完整的資料、分析和 ML 專案表示為來源檔案的集合。 請參閱什麼是 Databricks Asset Bundles?。
若要定義本文的套件組合,請在本機電腦上的複製的存放庫根目錄中建立名為 databricks.yml 的檔案。 在此範例 databricks.yml 檔案中,取代下列預留位置:
- 將
<bundle-name>取代為套件組合的唯一程式設計名稱。 例如,可以是jenkins-demo。 - 將
<job-prefix-name>取代為一些字串,以協助唯一識別在此範例工作區中建立的 Azure Databricks 作業。 例如,可以是jenkins-demo。 它應與 Jenkinsfile 中的JOBPREFIX值相符。 - 將
<spark-version-id>取代為作業叢集的 Databricks Runtime 版本識別碼,例如13.3.x-scala2.12。 - 將
<cluster-node-type-id>取代為作業叢集的節點類型識別碼,例如Standard_DS3_v2。 - 請注意,
dev對應中的targets與 Jenkinsfile 中的BUNDLETARGET相同。 套件組合目標會指定主機和相關部署行為。
以下是 databricks.yml 檔案,此檔案必須新增至存放庫的根目錄,才能使此範例正常運作:
# Filename: databricks.yml
bundle:
name: <bundle-name>
variables:
job_prefix:
description: A unifying prefix for this bundle's job and task names.
default: <job-prefix-name>
spark_version:
description: The cluster's Spark version ID.
default: <spark-version-id>
node_type_id:
description: The cluster's node type ID.
default: <cluster-node-type-id>
artifacts:
dabdemo-wheel:
type: whl
path: ./Libraries/python/dabdemo
resources:
jobs:
run-unit-tests:
name: ${var.job_prefix}-run-unit-tests
tasks:
- task_key: ${var.job_prefix}-run-unit-tests-task
new_cluster:
spark_version: ${var.spark_version}
node_type_id: ${var.node_type_id}
num_workers: 1
spark_env_vars:
WORKSPACEBUNDLEPATH: ${workspace.root_path}
notebook_task:
notebook_path: ./run_unit_tests.py
source: WORKSPACE
libraries:
- pypi:
package: pytest
run-dabdemo-notebook:
name: ${var.job_prefix}-run-dabdemo-notebook
tasks:
- task_key: ${var.job_prefix}-run-dabdemo-notebook-task
new_cluster:
spark_version: ${var.spark_version}
node_type_id: ${var.node_type_id}
num_workers: 1
data_security_mode: SINGLE_USER
spark_env_vars:
WORKSPACEBUNDLEPATH: ${workspace.root_path}
notebook_task:
notebook_path: ./dabdemo_notebook.py
source: WORKSPACE
libraries:
- whl: "/Workspace${workspace.root_path}/files/Libraries/python/dabdemo/dist/dabdemo-0.0.1-py3-none-any.whl"
evaluate-notebook-runs:
name: ${var.job_prefix}-evaluate-notebook-runs
tasks:
- task_key: ${var.job_prefix}-evaluate-notebook-runs-task
new_cluster:
spark_version: ${var.spark_version}
node_type_id: ${var.node_type_id}
num_workers: 1
spark_env_vars:
WORKSPACEBUNDLEPATH: ${workspace.root_path}
spark_python_task:
python_file: ./evaluate_notebook_runs.py
source: WORKSPACE
libraries:
- pypi:
package: unittest-xml-reporting
targets:
dev:
mode: development
如需有關 databricks.yml 檔案的詳細資訊,請參閱 Databricks Asset Bundle 組態。
將套件組合部署至工作區
Jenkins 管線的第三個階段 (名為 Deploy Bundle) 的定義如下:
stage('Deploy Bundle') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle deploy -t ${BUNDLETARGET}
"""
}
此階段執行兩項操作:
- 由於
artifact檔案中的databricks.yml對應設定為whl,因此這會指示 Databricks CLI 使用指定位置中的setup.py檔案組建 Python Wheel 檔案。 - 在本機開發電腦上組建 Python Wheel 檔案後,Databricks CLI 會將組建的 Python Wheel 檔案以及指定的 Python 檔案和筆記本部署至 Azure Databricks 工作區。 根據預設,Databricks Asset Bundle 會將 Python Wheel 檔案和其他檔案部署至
/Workspace/Users/<your-username>/.bundle/<bundle-name>/<target-name>。
若要讓 Python Wheel 檔案按 databricks.yml 檔案中指定的方式組建,請在本機電腦上的複製的存放庫根目錄中建立下列資料夾和檔案。
若要定義執行筆記本時所依據的 Python Wheel 檔案的邏輯和單元測試,請建立名為 addcol.py 和 test_addcol.py 的兩個檔案,並將其新增至存放庫的 Libraries 資料夾內名為 python/dabdemo/dabdemo 的資料夾結構,如下所示 (為簡潔起見,省略號表示存放庫中省略的資料夾):
├── ...
├── Libraries
│ └── python
│ └── dabdemo
│ └── dabdemo
│ ├── addcol.py
│ └── test_addcol.py
├── ...
addcol.py 檔案包含程式庫函式,稍後會組建到 Python Wheel 檔案中,然後安裝在 Azure Databricks 叢集上。 這是一個簡單的函式,可將填入常值的新資料行新增至 Apache Spark DataFrame:
# Filename: addcol.py
import pyspark.sql.functions as F
def with_status(df):
return df.withColumn("status", F.lit("checked"))
檔案 test_addcol.py 包含測試,以將模擬 DataFrame 物件傳遞至 addcol.py 中定義的 with_status 函式。 然後,結果會與包含預期值的 DataFrame 物件進行比較。 如果值相符 (在此案例中它們相符),則測試會通過:
# Filename: test_addcol.py
import pytest
from pyspark.sql import SparkSession
from dabdemo.addcol import *
class TestAppendCol(object):
def test_with_status(self):
spark = SparkSession.builder.getOrCreate()
source_data = [
("paula", "white", "paula.white@example.com"),
("john", "baer", "john.baer@example.com")
]
source_df = spark.createDataFrame(
source_data,
["first_name", "last_name", "email"]
)
actual_df = with_status(source_df)
expected_data = [
("paula", "white", "paula.white@example.com", "checked"),
("john", "baer", "john.baer@example.com", "checked")
]
expected_df = spark.createDataFrame(
expected_data,
["first_name", "last_name", "email", "status"]
)
assert(expected_df.collect() == actual_df.collect())
若要讓 Databricks CLI 正確地將此程式庫程式碼封裝到 Python Wheel 檔案中,請在與上述兩個檔案相同的資料夾中建立名為 __init__.py 和 __main__.py 的兩個檔案。 此外,在 setup.py 資料夾中建立名為 python/dabdemo 的檔案,如下所示 (為簡潔起見,省略號指示省略的資料夾):
├── ...
├── Libraries
│ └── python
│ └── dabdemo
│ ├── dabdemo
│ │ ├── __init__.py
│ │ ├── __main__.py
│ │ ├── addcol.py
│ │ └── test_addcol.py
│ └── setup.py
├── ...
檔案 __init__.py 包含程式庫的版本號碼和作者。 以您的名稱取代 <my-author-name>:
# Filename: __init__.py
__version__ = '0.0.1'
__author__ = '<my-author-name>'
import sys, os
sys.path.append(os.path.join(os.path.dirname(__file__), "..", ".."))
檔案 __main__.py 包含程式庫的進入點:
# Filename: __main__.py
import sys, os
sys.path.append(os.path.join(os.path.dirname(__file__), "..", ".."))
from addcol import *
def main():
pass
if __name__ == "__main__":
main()
檔案 setup.py 包含將程式庫組建至 Python Wheel 檔案的其他設定。 將 <my-url>、<my-author-name>@<my-organization> 和 <my-package-description> 取代為意義的值:
# Filename: setup.py
from setuptools import setup, find_packages
import dabdemo
setup(
name = "dabdemo",
version = dabdemo.__version__,
author = dabdemo.__author__,
url = "https://<my-url>",
author_email = "<my-author-name>@<my-organization>",
description = "<my-package-description>",
packages = find_packages(include = ["dabdemo"]),
entry_points={"group_1": "run=dabdemo.__main__:main"},
install_requires = ["setuptools"]
)
測試 Python Wheel 的元件邏輯
Run Unit Tests 階段 (Jenkins 管線的第四個階段) 使用 pytest 來測試程式庫的邏輯,以確定其如組建般運作。 此階段的定義如下:
stage('Run Unit Tests') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle run -t ${BUNDLETARGET} run-unit-tests
"""
}
此階段使用 Databricks CLI 來執行筆記本作業。 此作業會執行具有檔案名 run-unit-test.py 的 Python 筆記本。 此筆記本會針對此程式庫的邏輯執行 pytest。
若要執行此範例的單元測試,請將包含下列內容的 Python 筆記本檔案 (名為 run_unit_tests.py) 新增至本機電腦上的複製的存放庫根目錄:
# Databricks notebook source
# COMMAND ----------
# MAGIC %sh
# MAGIC
# MAGIC mkdir -p "/Workspace${WORKSPACEBUNDLEPATH}/Validation/reports/junit/test-reports"
# COMMAND ----------
# Prepare to run pytest.
import sys, pytest, os
# Skip writing pyc files on a readonly filesystem.
sys.dont_write_bytecode = True
# Run pytest.
retcode = pytest.main(["--junit-xml", f"/Workspace{os.getenv('WORKSPACEBUNDLEPATH')}/Validation/reports/junit/test-reports/TEST-libout.xml",
f"/Workspace{os.getenv('WORKSPACEBUNDLEPATH')}/files/Libraries/python/dabdemo/dabdemo/"])
# Fail the cell execution if there are any test failures.
assert retcode == 0, "The pytest invocation failed. See the log for details."
使用組建的 Python Wheel
此 Jenkins 管線的第五個階段 (名為 Run Notebook) 執行一個 Python 筆記本,該筆記本呼叫組建的 Python Wheel 檔案中的邏輯,如下所示:
stage('Run Notebook') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle run -t ${BUNDLETARGET} run-dabdemo-notebook
"""
}
此階段執行 Databricks CLI,後者指示工作區執行筆記本作業。 此筆記本會建立 DataFrame 物件、將其傳遞給程式庫的 with_status 函式、列印結果,以及報告作業的執行結果。 透過在本機開發電腦上的複製的存放庫根目錄中新增包含下列內容的 Python 筆記本檔案 (名為 dabdaddemo_notebook.py) 來建立筆記本:
# Databricks notebook source
# COMMAND ----------
# Restart Python after installing the wheel.
dbutils.library.restartPython()
# COMMAND ----------
from dabdemo.addcol import with_status
df = (spark.createDataFrame(
schema = ["first_name", "last_name", "email"],
data = [
("paula", "white", "paula.white@example.com"),
("john", "baer", "john.baer@example.com")
]
))
new_df = with_status(df)
display(new_df)
# Expected output:
#
# +------------+-----------+-------------------------+---------+
# │first_name │last_name │email │status |
# +============+===========+=========================+=========+
# │paula │white │paula.white@example.com │checked |
# +------------+-----------+-------------------------+---------+
# │john │baer │john.baer@example.com │checked |
# +------------+-----------+-------------------------+---------+
評估筆記本作業執行結果
Evaluate Notebook Runs 階段 (Jenkins 管線的第六個階段) 會評估前面的筆記本作業執行的結果。 此階段的定義如下:
stage('Evaluate Notebook Runs') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle run -t ${BUNDLETARGET} evaluate-notebook-runs
"""
}
此階段執行 Databricks CLI,後者指示工作區執行 Python 檔案作業。 此 Python 檔案會確定筆記本作業執行的失敗和成功條件,並報告此失敗或成功結果。 在本機開發電腦中的複製的存放庫根目錄中,建立包含下列內容的檔案 (名為 evaluate_notebook_runs.py):
import unittest
import xmlrunner
import json
import glob
import os
class TestJobOutput(unittest.TestCase):
test_output_path = f"/Workspace${os.getenv('WORKSPACEBUNDLEPATH')}/Validation/Output"
def test_performance(self):
path = self.test_output_path
statuses = []
for filename in glob.glob(os.path.join(path, '*.json')):
print('Evaluating: ' + filename)
with open(filename) as f:
data = json.load(f)
duration = data['tasks'][0]['execution_duration']
if duration > 100000:
status = 'FAILED'
else:
status = 'SUCCESS'
statuses.append(status)
f.close()
self.assertFalse('FAILED' in statuses)
def test_job_run(self):
path = self.test_output_path
statuses = []
for filename in glob.glob(os.path.join(path, '*.json')):
print('Evaluating: ' + filename)
with open(filename) as f:
data = json.load(f)
status = data['state']['result_state']
statuses.append(status)
f.close()
self.assertFalse('FAILED' in statuses)
if __name__ == '__main__':
unittest.main(
testRunner = xmlrunner.XMLTestRunner(
output = f"/Workspace${os.getenv('WORKSPACEBUNDLEPATH')}/Validation/Output/test-results",
),
failfast = False,
buffer = False,
catchbreak = False,
exit = False
)
匯入和報告測試結果
此 Jenkins 管線中的第七個階段 (名為 Import Test Results) 使用 Databricks CLI 將工作區中的測試結果傳送至本機開發電腦。 第八個階段,也就是最後階段,名為 Publish Test Results,使用 junit Jenkins 外掛程式將測試結果發佈至 Jenkins。 這可讓您將與測試結果的狀態相關的報表和儀表板視覺化。 這些階段定義如下:
stage('Import Test Results') {
def DATABRICKS_BUNDLE_WORKSPACE_FILE_PATH
def getPath = "${DBCLIPATH}/databricks bundle validate -t ${BUNDLETARGET} | ${JQPATH}/jq -r .workspace.file_path"
def output = sh(script: getPath, returnStdout: true).trim()
if (output) {
DATABRICKS_BUNDLE_WORKSPACE_FILE_PATH = "${output}"
} else {
error "Failed to capture output or command execution failed: ${getPath}"
}
sh """#!/bin/bash
${DBCLIPATH}/databricks workspace export-dir \
${DATABRICKS_BUNDLE_WORKSPACE_FILE_PATH}/Validation/Output/test-results \
${WORKSPACE}/Validation/Output/test-results \
--overwrite
"""
}
stage('Publish Test Results') {
junit allowEmptyResults: true, testResults: '**/test-results/*.xml', skipPublishingChecks: true
}
將所有程式碼變更推送至第三方存放庫
現在,您應將本機開發電腦上的複製的存放庫內容推送至第三方存放庫。 在推送之前,應先將下列項目新增至複製的存放庫中的 .gitignore 檔案,因為您也許不應將內部 Databricks Asset Bundle 工作檔案、驗證報表、Python 組建檔案和 Python 快取推送到第三方存放庫。 通常,您想要在 Azure Databricks 工作區中重新產生新的驗證報表和最新的 Python Wheel 組建,而不是使用可能過時的驗證報表和 Python Wheel 組建:
.databricks/
.vscode/
Libraries/python/dabdemo/build/
Libraries/python/dabdemo/__pycache__/
Libraries/python/dabdemo/dabdemo.egg-info/
Validation/
執行 Jenkins 管線
您現在已準備好手動執行 Jenkins 管線。 若要這樣做,請從 Jenkins 儀表板:
- 按一下 Jenkins 管線的名稱。
- 在側邊欄上,按一下 [立即組建]。
- 若要查看結果,請按一下最新的管線執行 (例如
#1),然後按一下 [主控台輸出]。
此時,CI/CD 管線已完成整合和部署週期。 藉由自動執行此程序,您可以確保程式碼已透過有效、一致且可重複的程序進行測試和部署。 若要指示第三方 Git 供應商在每次發生特定事件 (例如存放庫提取要求) 時執行 Jenkins,請參閱第三方 Git 供應商的文件。