HorovodRunner:使用 Horovod 分散式深度學習
重要
Horovod 和 HorovodRunner 現在已被取代,而且不會在 Databricks Runtime 16.0 ML 和更新版本中預安裝。 針對分散式深度學習,Databricks 建議使用 TorchDistributor 搭配 PyTorch 進行分散式定型,或使用 tf.distribute.Strategy TensorFlow 進行分散式定型的 API。
瞭解如何使用 HorovodRunner 執行機器學習模型的分散式定型,以在 Azure Databricks 上啟動 Horovod 定型作業作為 Spark 作業。
何謂 HorovodRunner?
HorovodRunner 是一般 API,可使用 Horovod 架構在 Azure Databricks 上執行分散式深度學習工作負載。 藉由整合 Horovod 與 Spark 的 屏障模式,Azure Databricks 能夠針對 Spark 上長時間執行的深度學習訓練作業提供更高的穩定性。 HorovodRunner 採用 Python 方法,其中包含具有 Horovod 攔截的深度學習訓練程式代碼。 HorovodRunner 會挑選驅動程式上的 方法,並將其散發給Spark背景工作角色。 Horovod MPI 作業會內嵌為使用屏障執行模式的Spark作業。 第一個執行程式會使用 BarrierTaskContext 收集所有工作執行程式的IP位址,並使用觸發 Horovod 作業 mpirun。 每個 Python MPI 進程都會載入挑選的使用者程式、還原串行化並加以執行。
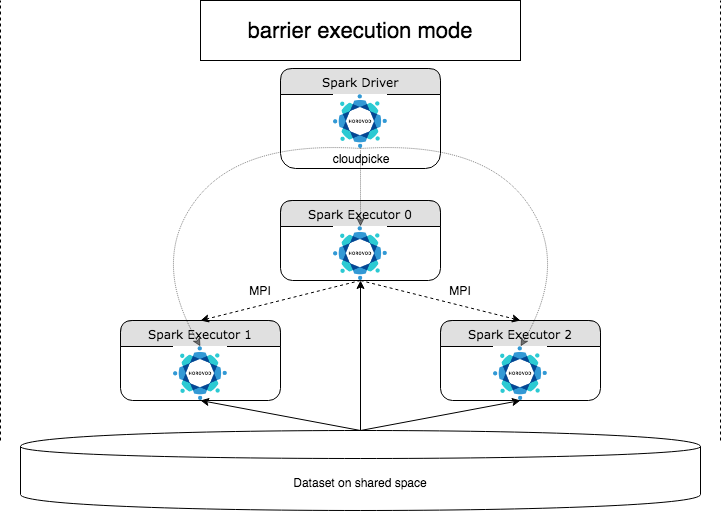
使用 HorovodRunner 的分散式訓練
HorovodRunner 可讓您啟動 Horovod 訓練作業作為 Spark 作業。 HorovodRunner API 支援數據表中顯示的方法。 如需詳細資訊,請參閱 HorovodRunner API 檔。
| 方法和簽章 | 描述 |
|---|---|
init(self, np) |
建立 HorovodRunner 的實例。 |
run(self, main, **kwargs) |
執行叫用 main(**kwargs)的 Horovod 訓練作業。 main 函式和關鍵詞自變數會使用 cloudpickle 串行化,並散發給叢集背景工作角色。 |
使用 HorovodRunner 開發分散式訓練計劃的一般方法是:
- 建立
HorovodRunner以節點數目初始化的實例。 - 根據 Horovod 使用方式中所述的方法定義 Horovod 定型方法,請務必在方法內新增任何匯入語句。
- 將定型方法傳遞至
HorovodRunner實例。
例如:
hr = HorovodRunner(np=2)
def train():
import tensorflow as tf
hvd.init()
hr.run(train)
若要只在 n 驅動程式上使用子進程執行 HorovodRunner,請使用 hr = HorovodRunner(np=-n)。 例如,如果驅動程式節點上有 4 個 GPU,您可以選擇 n 最多 4。 如需 參數 np的詳細資訊,請參閱 HorovodRunner API 檔。 如需如何為每個子進程釘選一個 GPU 的詳細資訊,請參閱 Horovod 使用指南。
常見的錯誤是找不到或挑選 TensorFlow 物件。 當連結庫匯入語句未散發至其他執行程式時,就會發生這種情況。 若要避免此問題,請在 Horovod 定型方法頂端,以及 Horovod 定型方法中呼叫的任何其他使用者定義函式內,包含所有 import 語句(例如import tensorflow as tf, )。
使用 Horovod 時程表錄製 Horovod 訓練
Horovod 能夠記錄其活動的時程表,稱為 Horovod 時程表。
重要
Horovod 時間軸會對效能產生重大影響。 啟用 Horovod 時間軸時,初始 3 輸送量可能會減少約 40%。 若要加速 HorovodRunner 作業,請勿使用 Horovod Timeline。
在訓練進行時,您無法檢視 Horovod 時間軸。
若要記錄 Horovod 時程表,請將 HOROVOD_TIMELINE 環境變數設定為您要儲存時程表檔案的位置。 Databricks 建議在共享記憶體上使用位置,以便輕鬆地擷取時程表檔案。 例如,您可以使用 DBFS 本機檔案 API ,如下所示:
timeline_dir = "/dbfs/ml/horovod-timeline/%s" % uuid.uuid4()
os.makedirs(timeline_dir)
os.environ['HOROVOD_TIMELINE'] = timeline_dir + "/horovod_timeline.json"
hr = HorovodRunner(np=4)
hr.run(run_training_horovod, params=params)
然後,將時程表特定的程式代碼新增至定型函式的開頭和結尾。 下列範例筆記本包含範例程序代碼,可用來作為檢視定型進度的因應措施。
Horovod 時間軸範例筆記本
若要下載時程表檔案,請使用 Databricks CLI,然後使用 Chrome 瀏覽器 chrome://tracing 的設施來檢視它。 例如:
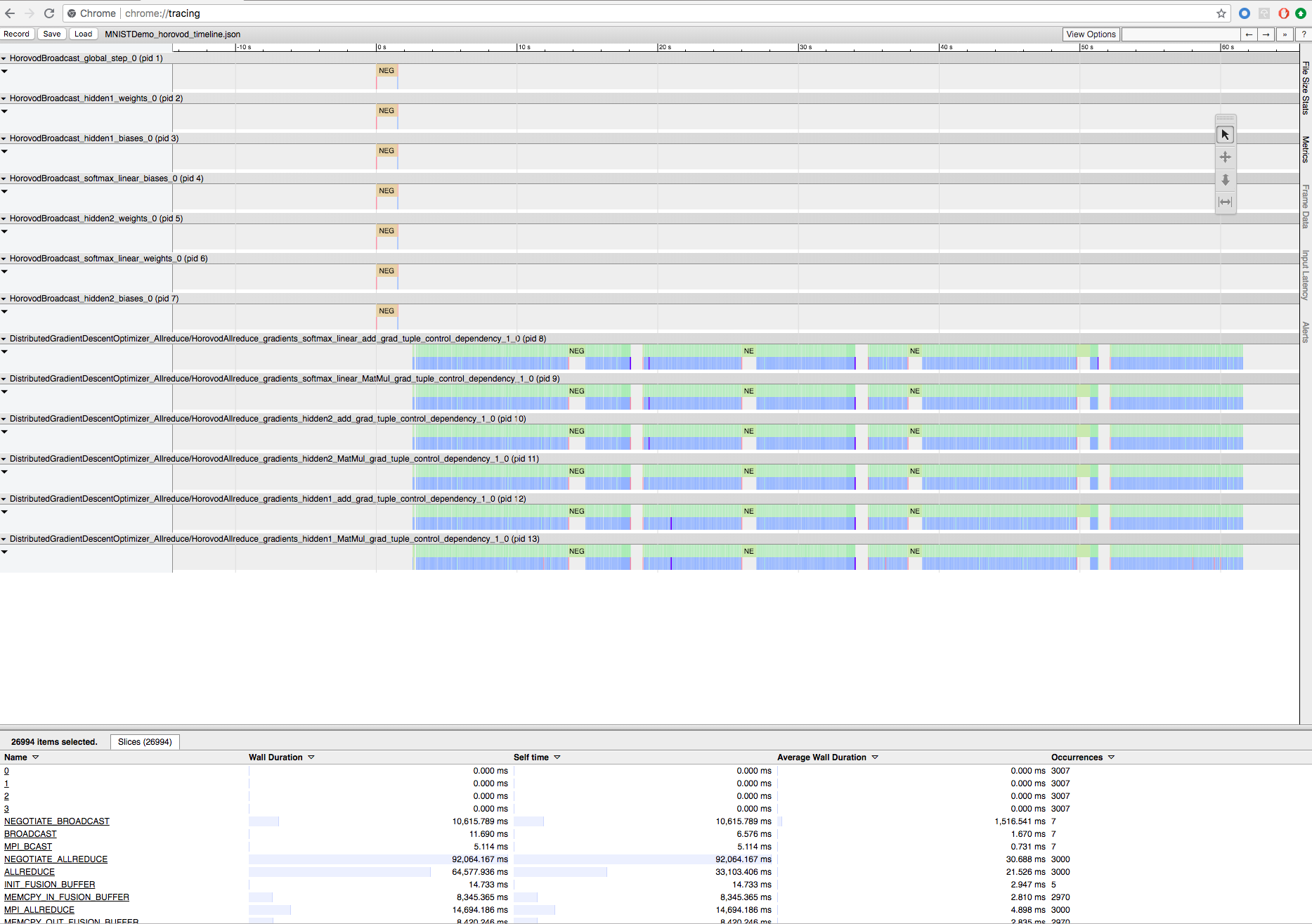
開發工作流程
這些是將單一節點深度學習程式代碼遷移至分散式定型的一般步驟。 範例 :使用 HorovodRunner 遷移至分散式深度學習,本節將說明這些步驟。
- 準備單一節點程序代碼: 使用 TensorFlow、Keras 或 PyTorch 準備及測試單一節點程式代碼。
- 遷移至 Horovod:遵循 Horovod 使用量中的指示,使用 Horovod 移轉程式代碼,並在驅動程式上進行測試:
- 新增
hvd.init()以初始化 Horovod。 - 使用釘選此進程
config.gpu_options.visible_device_list要使用的伺服器 GPU。 透過每個進程一個 GPU 的一般設定,這可以設定為本機排名。 在此情況下,伺服器上的第一個進程將會配置第一個 GPU,第二個進程將會配置第二個 GPU 等等。 - 包含數據集的分區。 執行分散式定型時,此數據集運算元非常有用,因為它可讓每個背景工作角色讀取唯一的子集。
- 依背景工作角色數目調整學習率。 同步分散式定型中的有效批次大小會依背景工作角色數目進行調整。 增加學習速率可補償批次大小增加。
- 將優化工具包裝在 中
hvd.DistributedOptimizer。 分散式優化器會將漸層計算委派給原始優化器、使用allreduce或allgather的平均漸層,然後套用平均漸層。 - 新增
hvd.BroadcastGlobalVariablesHook(0)以將初始變數狀態從排名 0 廣播到所有其他進程。 當訓練是以隨機權數開始或從檢查點還原時,確保所有背景工作角色的一致初始化是必要的。 或者,如果您未使用MonitoredTrainingSession,您可以在全域變數初始化之後執行hvd.broadcast_global_variables作業。 - 修改您的程式代碼,只儲存背景工作角色 0 上的檢查點,以防止其他背景工作角色損毀。
- 新增
- 遷移至 HorovodRunner: HorovodRunner 會叫用 Python 函式來執行 Horovod 訓練作業。 您必須將主要定型程序包裝成單一 Python 函式。 然後,您可以在本機模式和分散式模式中測試 HorovodRunner。
更新深度學習連結庫
注意
本文包含從屬一詞的參考,這是 Azure Databricks 不使用的詞彙。 從軟體中移除該字詞時,我們也會將其從本文中移除。
如果您升級或降級 TensorFlow、Keras 或 PyTorch,您必須重新安裝 Horovod,才能針對新安裝的連結庫進行編譯。 例如,如果您想要升級 TensorFlow,Databricks 建議從 TensorFlow 安裝指示 使用 init 腳本,並將下列 TensorFlow 特定 Horovod 安裝程式代碼附加至它的結尾。 請參閱 Horovod 安裝指示 ,以使用不同的組合,例如升級或降級 PyTorch 和其他連結庫。
add-apt-repository -y ppa:ubuntu-toolchain-r/test
apt update
# Using the same compiler that TensorFlow was built to compile Horovod
apt install g++-7 -y
update-alternatives --install /usr/bin/gcc gcc /usr/bin/gcc-7 60 --slave /usr/bin/g++ g++ /usr/bin/g++-7
HOROVOD_GPU_ALLREDUCE=NCCL HOROVOD_CUDA_HOME=/usr/local/cuda pip install horovod==0.18.1 --force-reinstall --no-deps --no-cache-dir
範例:使用 HorovodRunner 遷移至分散式深度學習
下列範例會根據 MNIST 數據集,示範如何使用 HorovodRunner 將單一節點深度學習程式遷移至分散式深度學習。
限制
- 使用工作區檔案時,如果
np設定為大於 1 且筆記本會從其他相對檔案匯入,HorovodRunner 將無法運作。 請考慮使用 horovod.spark 而不是HorovodRunner。 - 如果您遇到類似
WARNING: Open MPI accepted a TCP connection from what appears to be a another Open MPI process but cannot find a corresponding process entry for that peer的錯誤,這表示叢集中節點之間的網路通訊發生問題。 若要解決此錯誤,請在定型程式代碼中新增下列代碼段,以使用主要網路介面。
import os
os.environ["OMPI_MCA_btl_tcp_if_include"]="eth0"
os.environ["NCCL_SOCKET_IFNAME"]="eth0"
意見反映
即將推出:我們會在 2024 年淘汰 GitHub 問題,並以全新的意見反應系統取代並作為內容意見反應的渠道。 如需更多資訊,請參閱:https://aka.ms/ContentUserFeedback。
提交及檢視以下的意見反映: