這很重要
湖底自動縮放可在以下地區使用:eastus,eastus2,centralus,southcentralus,westus,westus2,canadacentral,brazilsouth,northeurope,uksouth,westeurope,australiaeast,centralindia,southeastasia。
Lakebase 自動縮放是 Lakebase 的最新版本,具備自動縮放計算、縮放至零、分支及即時還原功能。 如果你是 Lakebase Provisioned 使用者,請參見 Lakebase Provisioned。
當你建立專案時,Lakebase 會在專案中建立幾個 Postgres 角色:
- 專案擁有者的 Azure Databricks 身份(例如
user@databricks.com)具備一個 Postgres 角色,此角色擁有預設的databricks_postgres資料庫。 - 行政
databricks_superuser職務
這兩個角色在你第一次打開專案時,都會在角色 與資料庫 標籤中看到。
databricks_postgres資料庫是為了讓你在專案建立後立刻連線並試用 Lakebase。
同時也創建了數個系統管理角色。 這些是 Azure Databricks 服務用於管理、監控及資料操作的內部角色。
備註
Postgres 角色控制 資料庫存取 (誰能查詢資料)。 關於專案權限(誰能管理基礎設施),請參見專案權限。 關於如何設定兩者的教學,請參見 「教學:授予專案與資料庫存取權給新使用者」。
建立 Postgres 角色
Lakebase 支援兩種類型的 Postgres 角色用於資料庫存取:
-
Azure Databricks 身分的 OAuth 角色: 你可以使用 Lakebase 使用者介面、
databricks_auth包含 SQL 的擴充功能,或是利用 Python SDK 和 REST API 來建立這些角色。 啟用 Azure Databricks 身份(使用者、服務主體及群組)使用 OAuth 令牌連接。 - Native Postgres 密碼角色: 使用 Lakebase 介面、SQL、Python SDK 和 REST API 來建立這些角色。 使用任何有效的角色名稱並使用密碼驗證。
關於選擇角色類型,請參閱 認證概述。 每個平台都有不同的使用情境設計。
為 Azure Databricks 身分識別建立 OAuth 角色
若要讓 Azure Databricks 身份(使用者、服務主體或群組)使用 OAuth 標記連接,請使用 Lakebase UI、 databricks_auth 包含 SQL 的擴充功能或 REST API 建立 OAuth 角色。
關於取得 OAuth 標記的詳細說明,請參閱 「在使用者對機器流程中取得 OAuth 標記 」及 「在機器對機器流程中取得 OAuth 標記」。
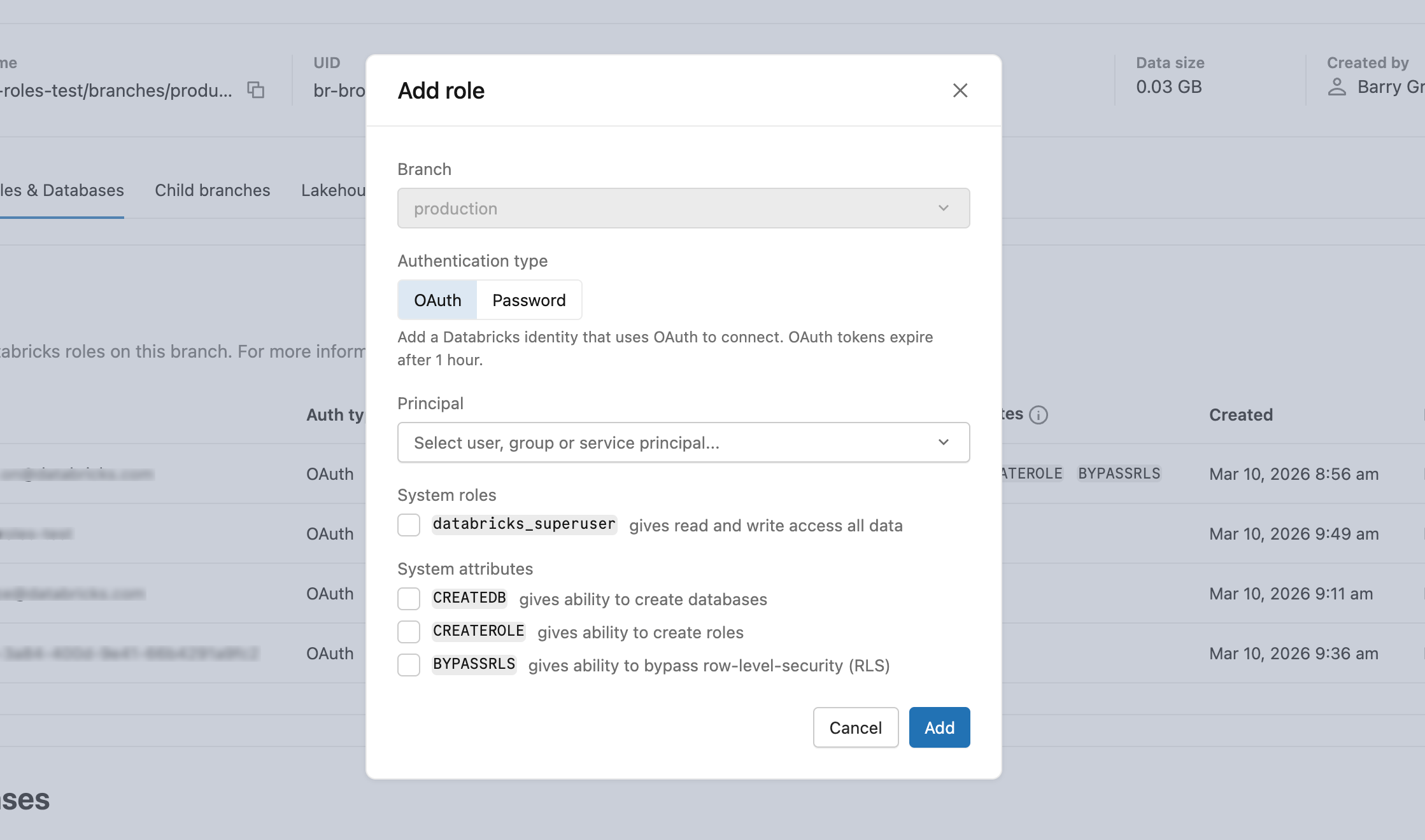
UI
- 在 「角色與資料庫新增>角色>OAuth 標籤」中,選擇使用者、服務主體或群組以授權資料庫存取權。
- 建立角色後,授予適當的資料庫權限。 了解如何管理權限
SQL
先決條件:
- 你必須擁有
CREATECREATE ROLE資料庫的權限 - 你必須以有效的 OAuth 令牌認證為 Azure Databricks 身份
- 原生 Postgres 認證的會話無法建立 OAuth 角色
建立
databricks_auth擴充套件。 每個 Postgres 資料庫都必須有自己的擴充功能。CREATE EXTENSION IF NOT EXISTS databricks_auth;使用這個
databricks_create_role函式來為 Azure Databricks 身份建立一個 Postgres 角色:SELECT databricks_create_role('identity_name', 'identity_type');對於 Azure Databricks 用戶:
SELECT databricks_create_role('myuser@databricks.com', 'USER');針對 Azure Databricks 服務主體:
SELECT databricks_create_role('8c01cfb1-62c9-4a09-88a8-e195f4b01b08', 'SERVICE_PRINCIPAL');針對 Azure Databricks 群組:
SELECT databricks_create_role('My Group Name', 'GROUP');群組名稱依大小寫區分,必須完全符合你在 Azure Databricks 工作區中所顯示的名稱。 當你為群組建立 Postgres 角色時,該 Databricks 群組的任何直接或間接成員(使用者或服務主體)都可以使用他們個人的 OAuth 憑證,將該群組角色認證為 Postgres。 這讓你可以在 Postgres 的群組層級管理權限,而不必為個別使用者維護權限。
授予新建立的角色資料庫權限。
函式僅透過 databricks_create_role() 授權來建立 Postgres 角色。 建立角色後,您必須對使用者需要存取的特定資料庫、結構或資料表授予適當的資料庫權限與權限。 了解如何管理權限
Python SDK
設定 identity_type 為 USER、 SERVICE_PRINCIPAL、 或 GROUP。 分別設定 postgres_role 為身份的電子郵件地址、應用程式 ID(UUID)或群組顯示名稱。 這個值會成為 Postgres 的角色名稱,並且是你在連接字串和 GRANT 語句中使用的名稱。
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.postgres import Role, RoleRoleSpec
w = WorkspaceClient()
operation = w.postgres.create_role(
parent="projects/my-project/branches/production",
role=Role(
spec=RoleRoleSpec(
identity_type="USER",
postgres_role="user@example.com"
)
)
)
role = operation.wait()
print(f"Created role: {role.name}")
建立角色後,授予適當的資料庫權限。 了解如何管理權限
curl (Unix指令)
設定 identity_type 為 USER、 SERVICE_PRINCIPAL、 或 GROUP。 分別設定 postgres_role 為身份的電子郵件地址、應用程式 ID(UUID)或群組顯示名稱。 這個值會成為 Postgres 的角色名稱,並且是你在連接字串和 GRANT 語句中使用的名稱。
curl -X POST "$WORKSPACE/api/2.0/postgres/projects/my-project/branches/production/roles" \
-H "Authorization: Bearer ${DATABRICKS_TOKEN}" \
-H "Content-Type: application/json" \
-d '{
"spec": {
"identity_type": "USER",
"postgres_role": "user@example.com"
}
}' | jq
端點回傳一個長期執行的操作。 輪詢至done轉變為true,然後使用角色的name欄位來進行後續的 API 呼叫。 參見 長時間執行的操作。
建立角色後,授予適當的資料庫權限。 了解如何管理權限
基於群組的認證
當你為 Azure Databricks 群組建立 Postgres 角色時,你就啟用了基於群組的認證功能。 這讓 Azure Databricks 群組的任何成員都能利用群組角色驗證 Postgres,簡化權限管理。
運作方式:
- 為 Databricks 群組建立一個 Postgres 角色。
- 在 Postgres 中授予群組角色資料庫權限。 請參見 管理權限。
- Databricks 群組中任何直接或間接成員(使用者或服務主體)皆可使用其個人 OAuth 令牌連接 Postgres。
- 連線時,成員以群組角色身份認證,並繼承該角色的所有權限。
認證流程:
當群組成員連線時,他們會指定群組的 Postgres 角色名稱作為使用者名稱,並以自己的 OAuth 令牌作為密碼:
export PGPASSWORD='<OAuth token of a group member>'
export GROUP_ROLE_NAME='<pg-case-sensitive-group-role-name>'
psql -h $HOSTNAME -p 5432 -d databricks_postgres -U $GROUP_ROLE_NAME
關鍵考量:
- 群組成員驗證: 群組成員資格僅在認證時驗證。 若成員在建立連線後被移除 Azure Databricks 群組,該連線仍保持有效。 移除成員的新連線嘗試會被拒絕。
- 工作空間範圍範圍: 只有分配到與專案相同的 Azure Databricks 工作空間的群組才支援群組驗證。 想了解如何將群組指派到工作區,請參閱 管理群組。
-
大小寫敏感性: 在
databricks_create_role()中使用的群組名稱必須與你的 Azure Databricks 工作區中所顯示的群組名稱完全一致,包括大小寫。 - 權限管理: 在 Postgres 中管理群組層級的權限比管理個別使用者權限更有效率。 當你授予群組角色權限時,所有現有及未來的群組成員都會自動繼承這些權限。
- 身份重命名: 如果使用者的電子郵件或群組顯示名稱在 Azure Databricks 中更改,認證和現有資料庫授權都會失效。 丟棄舊角色,建立一個更新名稱的新角色,並更新連線字串和授權。
備註
角色名稱不得超過 63 個字元,且部分名稱不被允許使用。 了解更多: 管理職務
建立一個原生的 Postgres 密碼角色
密碼連線可在專案或運算層級停用。 請參見 「封鎖密碼連線」。
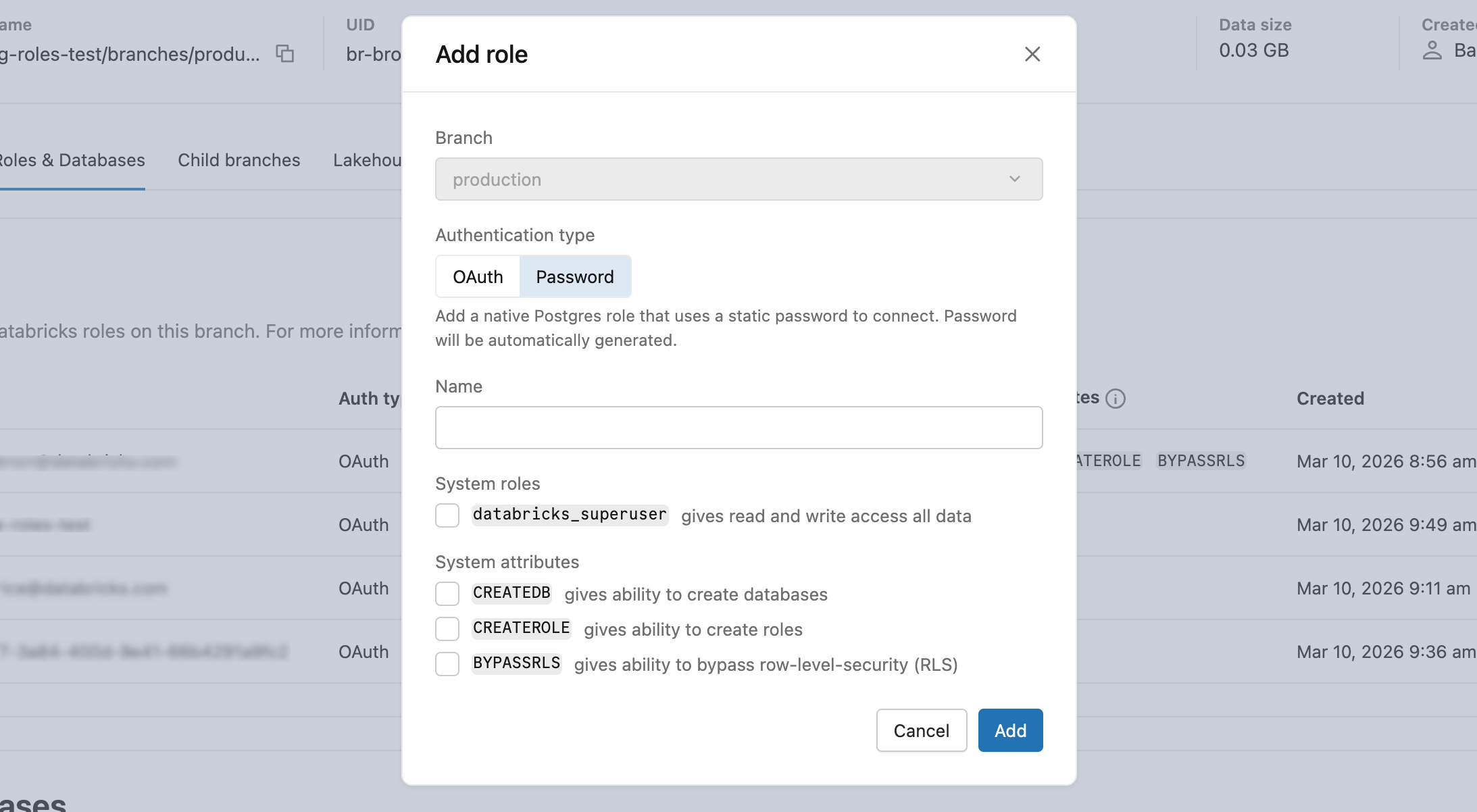
UI
- 在 角色與資料庫>新增角色>密碼 標籤中,輸入角色名稱並可選擇授予
databricks_superuser或系統屬性(CREATEDB,CREATEROLE,BYPASSRLS)。 - 複製產生的密碼並安全地提供給使用者。 此段之後未再播出。
SQL
CREATE ROLE role_name WITH LOGIN PASSWORD 'your_secure_password';
密碼應至少包含12個字元,並混合小寫、大寫、數字和符號等字元。 使用者自訂密碼會在建立時驗證,以確保 60 位元熵。
Python SDK
以省略 identity_type 建立密碼角色。 API 會在回應中回傳產生的密碼。
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.postgres import Role, RoleRoleSpec
w = WorkspaceClient()
operation = w.postgres.create_role(
parent="projects/my-project/branches/production",
role=Role(
spec=RoleRoleSpec(
postgres_role="my-app-role"
)
)
)
role = operation.wait()
print(f"Created role: {role.name}")
curl (Unix指令)
若要建立密碼角色,請省略 identity_type。 端點回傳一個長期執行的操作。 重複檢查直到 done 等於 true。
curl -X POST "$WORKSPACE/api/2.0/postgres/projects/my-project/branches/production/roles" \
-H "Authorization: Bearer ${DATABRICKS_TOKEN}" \
-H "Content-Type: application/json" \
-d '{
"spec": {
"postgres_role": "my-app-role"
}
}' | jq
查看 Postgres 角色
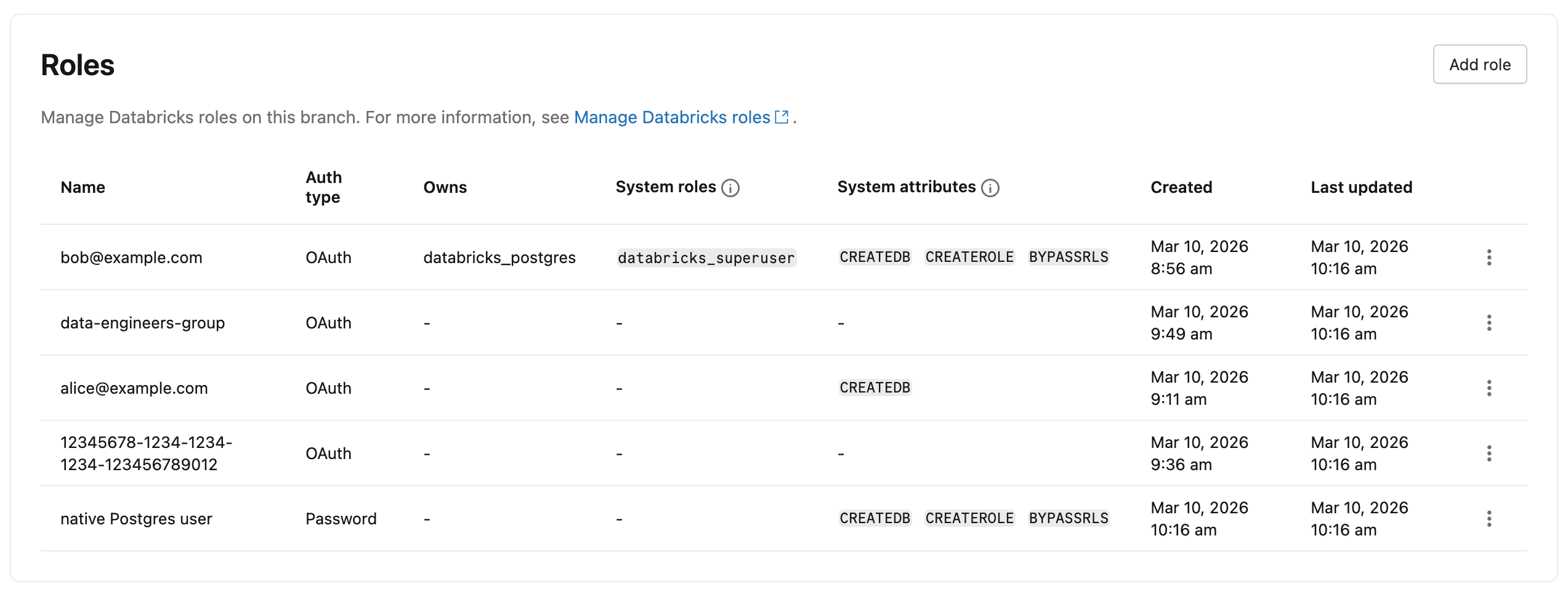
UI
要查看專案中所有 Postgres 角色,請前往 Lakebase App 中分支機構的「 角色與資料庫」 分頁。 分支中建立的所有角色(系統 角色除外)都會列出。 Auth type 欄位顯示每個角色使用 OAuth 或密碼驗證。
PostgreSQL
查看所有角色的命令:\du
您可以使用任何 Postgres 用戶端(例如 )的元指令或 Lakebase SQL 編輯器,查看所有 Postgres 角色,包括\dupsql:
\du
List of roles
Role name | Attributes
-----------------------------+------------------------------------------------------------
cloud_admin | Superuser, Create role, Create DB, Replication, Bypass RLS
my.user@databricks.com | Create role, Create DB, Bypass RLS
databricks_control_plane | Superuser
databricks_gateway |
databricks_monitor |
databricks_reader_12345 | Create role, Create DB, Replication, Bypass RLS
databricks_replicator | Replication
databricks_superuser | Create role, Create DB, Cannot login, Bypass RLS
databricks_writer_12345 | Create role, Create DB, Replication, Bypass RLS
Python SDK
列出所有職務:
from databricks.sdk import WorkspaceClient
w = WorkspaceClient()
roles = w.postgres.list_roles(parent="projects/my-project/branches/production")
for role in roles:
print(f"{role.status.postgres_role} ({role.status.identity_type or 'PASSWORD'}): {role.name}")
找一個特定職位:
role = w.postgres.get_role(
name="projects/my-project/branches/production/roles/rol-xxxx-xxxxxxxxxx"
)
print(role)
curl (Unix指令)
列出所有職務:
curl -X GET "$WORKSPACE/api/2.0/postgres/projects/my-project/branches/production/roles" \
-H "Authorization: Bearer ${DATABRICKS_TOKEN}" | jq
找一個特定職位:
curl -X GET "$WORKSPACE/api/2.0/postgres/projects/my-project/branches/production/roles/rol-xxxx-xxxxxxxxxx" \
-H "Authorization: Bearer ${DATABRICKS_TOKEN}" | jq
回應包含 name 更新與刪除呼叫所需的欄位(例如 rol-xxxx-xxxxxxxxxx)。
更新角色
要在 UI 中更新角色屬性,請從角色選單中的「角色與資料庫」分頁選擇「編輯角色」。
使用 API 更新角色的系統角色或屬性。 使用 update_mask 查詢參數指定要更改的欄位;只有遮罩欄位會被修改。
備註
要取得角色的資源名稱用於更新與刪除呼叫,請使用 list roles 端點。 角色資源名稱使用系統產生的識別碼(例如 rol-xxxx-xxxxxxxxxx),而非 postgres_role 建立時提供的值。
curl -X PATCH "$WORKSPACE/api/2.0/postgres/projects/my-project/branches/production/roles/rol-xxxx-xxxxxxxxxx?update_mask=spec.membership_roles%2Cspec.attributes.createdb" \
-H "Authorization: Bearer ${DATABRICKS_TOKEN}" \
-H "Content-Type: application/json" \
-d '{
"name": "projects/my-project/branches/production/roles/rol-xxxx-xxxxxxxxxx",
"spec": {
"membership_roles": ["DATABRICKS_SUPERUSER"],
"attributes": { "createdb": true }
}
}' | jq
要移除 databricks_superuser,傳遞一個空陣列: "membership_roles": []。
刪除一個PostgreSQL角色
你可以同時放棄 Databricks 的身份型角色和 Postgres 的原生密碼角色。
UI
刪除角色是永久性的行為,無法撤銷。 若要刪除擁有資料庫的角色,您必須指定要將該角色擁有的物件重新指派給哪個角色。 否則,必須先手動刪除資料庫,然後才能刪除擁有該資料庫的角色。
要刪除任何 Postgres 角色,請使用 UI:
- 請在 Lakebase 應用程式中進入你分行的 「角色與資料庫」 標籤。
- 從角色選單選擇 刪除角色 並確認刪除。
PostgreSQL
你可以用標準 Postgres 指令放棄任何 Postgres 角色。 詳情請參閱 PostgreSQL 關於角色丟棄的文件。
放棄一個角色:
DROP ROLE role_name;
在 Azure Databricks 身份基礎角色被移除後,該身份在建立新角色之前,無法再使用 OAuth 憑證向 Postgres 進行認證。
Python SDK
from databricks.sdk import WorkspaceClient
w = WorkspaceClient()
operation = w.postgres.delete_role(
name="projects/my-project/branches/production/roles/rol-xxxx-xxxxxxxxxx"
)
operation.wait()
curl (Unix指令)
curl -X DELETE "$WORKSPACE/api/2.0/postgres/projects/my-project/branches/production/roles/rol-xxxx-xxxxxxxxxx" \
-H "Authorization: Bearer ${DATABRICKS_TOKEN}" | jq
預先建立的角色
專案建立後,Azure Databricks 會自動建立 Postgres 角色,用於專案管理和啟動。
| Role | Description | 繼承的權限 |
|---|---|---|
<project_owner_role> |
專案創建者的 Azure Databricks 身份(例如, my.user@databricks.com)。 這個角色擁有預設 databricks_postgres 資料庫,並能登入並管理專案。 |
會員 databricks_superuser |
databricks_superuser |
內部管理角色。 用於配置和管理整個專案的存取權限。 此角色享有廣泛的特權。 | 繼承自 pg_read_all_data、 pg_write_all_data和 pg_monitor。 |
了解更多關於這些角色的具體能力與權限: 預先建立的角色能力
Azure Databricks 所建立的系統角色
Azure Databricks 建立以下內部服務所需的系統角色。 你可以透過 \du發出psql指令來查看這些角色。
| Role | 目標 |
|---|---|
cloud_admin |
用於雲端基礎架構管理的超級使用者角色 |
databricks_control_plane |
內部 Databricks 元件用於管理操作的超級使用者角色 |
databricks_monitor |
由內部計量收集服務使用 |
databricks_replicator |
用於資料庫複製操作 |
databricks_writer_<dbid> |
在每個資料庫中用來建立和管理同步處理資料表的角色 |
databricks_reader_<dbid> |
用來讀取 Unity 目錄中註冊資料表的每個資料庫角色 |
databricks_gateway |
用於管理數據服務的內部連接 |
若要了解角色、權限和角色成員資格在 Postgres 中的運作方式,請使用 Postgres 文件中的下列資源: