具有小 I/O 的慢速 Spark 階段
如果您有沒有太多 I/O 的慢速階段,這可能是由下列原因所造成:
- 讀取許多小型檔案
- 撰寫許多小型檔案
- 慢 UDF(秒)
- 笛卡兒聯結
- 爆炸聯結
幾乎所有的問題都可以使用 SQL DAG 來識別。
開啟 SQL DAG
若要開啟 SQL DAG,請向上捲動至作業頁面頂端,然後按兩下 [相關聯的 SQL 查詢]:

您現在應該會看到 DAG。 如果沒有,請捲動一點,您應該會看到它:

繼續之前,請先熟悉 DAG,以及花費時間的位置。 DAG 中的某些節點有有用的時間資訊,而其他節點則沒有。 例如,此區塊花費 2.1 分鐘,甚至提供階段標識碼:

此節點要求您開啟它,才能看到它花了 1.4 分鐘:

這些時間是累計的,因此它是所有工作所花費的總時間,而不是時鐘時間。 但它仍然非常有用,因為它們與時鐘時間和成本相互關聯。
熟悉 DAG 中花費時間的位置很有説明。
讀取許多小型檔案
如果您看到其中一個掃描運算子需要很多時間,請開啟它並尋找讀取的檔案數目:
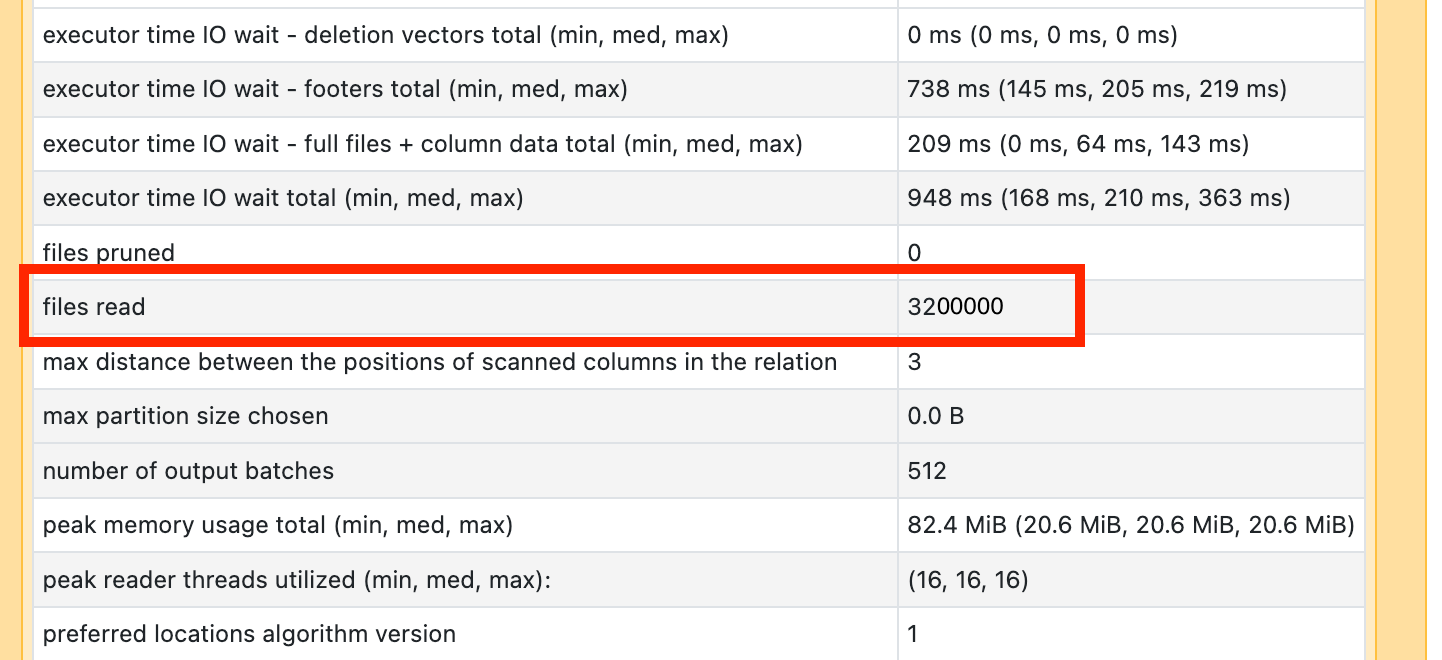
如果您正在讀取數萬個檔案或更多檔案,您可能會有一個小的檔案問題。 您的檔案應該不小於 8MB。 小型檔案問題通常是因為分割太多數據行或高基數數據行所造成。
如果您很幸運,您可能只需要執行 OPTIMIZE。 不管怎樣,您都需要重新考慮檔案 配置。
撰寫許多小型檔案
如果您看到寫入需要很長的時間,請開啟它,並尋找檔案數目,以及寫入的數據量:

如果您正在撰寫數萬個檔案或更多檔案,您可能會有一個小的檔案問題。 您的檔案應該不小於 8MB。 小型檔案問題通常是因為分割太多數據行或高基數數據行所造成。 您必須重新考慮檔案 配置 ,或開啟 優化的寫入。
慢速UDF
如果您知道您有 UDF,或在 DAG 中看到類似這樣的內容,您可能會遭受緩慢的 UDF:

如果您認為您正遭受此問題,請嘗試批注您的 UDF,以查看它如何影響管線的速度。 如果 UDF 確實是花費時間的地方,則您最好的選擇是使用原生函式重寫 UDF。 如果不可能,請考慮執行UDF的階段中的工作數目。 如果它小於叢集上的核心數目,在使用 UDF 之前, repartition() 您的資料框架:
(df
.repartition(num_cores)
.withColumn('new_col', udf(...))
)
UDF 也可能因為記憶體問題而受到影響。 請考慮每個工作可能都必須將分割區中的所有數據載入記憶體中。 如果此數據太大,則情況可能會變得非常緩慢或不穩定。 重新分割也可以藉由讓每個工作更小來解決此問題。
笛卡兒聯結
如果您在 DAG 中看到笛卡兒聯結或巢狀循環聯結,您應該知道這些聯結非常昂貴。 請確定這是您想要的,看看是否有另一種方式。
爆炸聯結或爆炸
如果您看到一些數據列進入節點並出現更多大小,您可能會遭受爆炸聯結或爆炸():

在 Databricks 優化指南中深入瞭解爆炸。