在 Azure Databricks 作業中使用 Databricks SQL
您可以在 Azure Databricks 作業中使用 SQL 工作類型,讓您建立、排程、操作和監視包含 Databricks SQL 物件的工作流程,例如查詢、舊版儀錶板和警示。 例如,您的工作流程可以擷取數據、準備數據、使用 Databricks SQL 查詢執行分析,然後在舊版儀錶板中顯示結果。
本文提供範例工作流程,可建立顯示 GitHub 參與計量的舊版儀錶板。 在這裡範例中,您將:
- 使用 Python 腳本和 GitHub REST API 內嵌 GitHub 數據。
- 使用 Delta Live Tables 管線轉換 GitHub 數據。
- 觸發 Databricks SQL 查詢,對備妥的數據執行分析。
- 在舊版儀錶板中顯示分析。
開始之前
您需要下列項目才能完成本逐步解說:
- GitHub 個人存取令牌。 此令牌必須具有存放 庫 許可權。
- 無伺服器 SQL 倉儲或 Pro SQL 倉儲。 請參閱 SQL 倉儲類型。
- Databricks 秘密範圍。 秘密範圍是用來安全地儲存 GitHub 令牌。 請參閱 步驟 1:將 GitHub 令牌儲存在秘密中。
步驟 1:將 GitHub 令牌儲存在秘密中
Databricks 建議使用秘密範圍安全地儲存和管理秘密,而不是硬式編碼認證,例如作業中的 GitHub 個人存取令牌。 下列 Databricks CLI 命令是建立秘密範圍並將 GitHub 令牌儲存在該範圍中的秘密的範例:
databricks secrets create-scope <scope-name>
databricks secrets put-secret <scope-name> <token-key> --string-value <token>
- 將 取代
<scope-name為用來儲存令牌的 Azure Databricks 秘密範圍名稱。 - 將取代
<token-key>為要指派給令牌的金鑰名稱。 - 將取代
<token>為 GitHub 個人存取令牌的值。
步驟 2:建立腳本以擷取 GitHub 數據
下列 Python 腳本會使用 GitHub REST API,從 GitHub 存放庫擷取認可和貢獻的數據。 輸入自變數會指定 GitHub 存放庫。 記錄會儲存至另一個輸入自變數所指定的 DBFS 位置。
此範例會使用 DBFS 來儲存 Python 腳本,但您也可以使用 Databricks Git 資料夾 或 工作區檔案 來儲存和管理腳本。
將此文稿儲存到本機磁碟上的位置:
import json import requests import sys api_url = "https://api.github.com" def get_commits(owner, repo, token, path): page = 1 request_url = f"{api_url}/repos/{owner}/{repo}/commits" more = True get_response(request_url, f"{path}/commits", token) def get_contributors(owner, repo, token, path): page = 1 request_url = f"{api_url}/repos/{owner}/{repo}/contributors" more = True get_response(request_url, f"{path}/contributors", token) def get_response(request_url, path, token): page = 1 more = True while more: response = requests.get(request_url, params={'page': page}, headers={'Authorization': "token " + token}) if response.text != "[]": write(path + "/records-" + str(page) + ".json", response.text) page += 1 else: more = False def write(filename, contents): dbutils.fs.put(filename, contents) def main(): args = sys.argv[1:] if len(args) < 6: print("Usage: github-api.py owner repo request output-dir secret-scope secret-key") sys.exit(1) owner = sys.argv[1] repo = sys.argv[2] request = sys.argv[3] output_path = sys.argv[4] secret_scope = sys.argv[5] secret_key = sys.argv[6] token = dbutils.secrets.get(scope=secret_scope, key=secret_key) if (request == "commits"): get_commits(owner, repo, token, output_path) elif (request == "contributors"): get_contributors(owner, repo, token, output_path) if __name__ == "__main__": main()將腳稿上傳至 DBFS:
- 移至您的 Azure Databricks 登陸頁面,然後按下
 提要欄位中的 [目錄]。
提要欄位中的 [目錄]。 - 按兩下 [ 瀏覽 DBFS]。
- 在 DBFS 檔案瀏覽器中,按兩下 [ 上傳]。 [ 將數據上傳至 DBFS ] 對話框隨即出現。
- 在 DBFS 中輸入路徑以儲存腳本、按兩下 [卸除要上傳的檔案],或按兩下以瀏覽,然後選取 Python 腳本。
- 按一下完成。
- 移至您的 Azure Databricks 登陸頁面,然後按下
步驟 3:建立 Delta Live Tables 管線來處理 GitHub 數據
在本節中,您會建立 Delta Live Tables 管線,將原始 GitHub 數據轉換成 Databricks SQL 查詢可以分析的數據表。 若要建立管線,請執行下列步驟:
在提要欄中,按兩下
 [新增 ],然後從功能表中選取 [筆記本 ]。 [ 建立筆記本 ] 對話框隨即出現。
[新增 ],然後從功能表中選取 [筆記本 ]。 [ 建立筆記本 ] 對話框隨即出現。在 [默認語言] 中,輸入名稱,然後選取 [Python]。 您可以將 [叢集 ] 設定為預設值。 Delta Live Tables 運行時間會在叢集執行管線之前建立叢集。
按一下 [建立]。
複製 Python 程式代碼範例,並將其貼到新的筆記本中。 您可以將範例程式代碼新增至筆記本或多個儲存格的單一儲存格。
import dlt from pyspark.sql.functions import * def parse(df): return (df .withColumn("author_date", to_timestamp(col("commit.author.date"))) .withColumn("author_email", col("commit.author.email")) .withColumn("author_name", col("commit.author.name")) .withColumn("comment_count", col("commit.comment_count")) .withColumn("committer_date", to_timestamp(col("commit.committer.date"))) .withColumn("committer_email", col("commit.committer.email")) .withColumn("committer_name", col("commit.committer.name")) .withColumn("message", col("commit.message")) .withColumn("sha", col("commit.tree.sha")) .withColumn("tree_url", col("commit.tree.url")) .withColumn("url", col("commit.url")) .withColumn("verification_payload", col("commit.verification.payload")) .withColumn("verification_reason", col("commit.verification.reason")) .withColumn("verification_signature", col("commit.verification.signature")) .withColumn("verification_verified", col("commit.verification.signature").cast("string")) .drop("commit") ) @dlt.table( comment="Raw GitHub commits" ) def github_commits_raw(): df = spark.read.json(spark.conf.get("commits-path")) return parse(df.select("commit")) @dlt.table( comment="Info on the author of a commit" ) def commits_by_author(): return ( dlt.read("github_commits_raw") .withColumnRenamed("author_date", "date") .withColumnRenamed("author_email", "email") .withColumnRenamed("author_name", "name") .select("sha", "date", "email", "name") ) @dlt.table( comment="GitHub repository contributors" ) def github_contributors_raw(): return( spark.readStream.format("cloudFiles") .option("cloudFiles.format", "json") .load(spark.conf.get("contribs-path")) )在提要欄位中,按兩下
 [工作流程],按兩下 [差異實時數據表] 索引卷標,然後按兩下 [ 建立管線]。
[工作流程],按兩下 [差異實時數據表] 索引卷標,然後按兩下 [ 建立管線]。為管線指定名稱,例如
Transform GitHub data。在 [ Notebook 連結庫 ] 字段中,輸入筆記本的路徑,或按下
 以選取筆記本。
以選取筆記本。按兩下 [ 新增組態]。 在
Key文字盒中, 輸入commits-path。 在Value文本框中,輸入將寫入 GitHub 記錄的 DBFS 路徑。 這可以是您選擇的任何路徑,而且是在建立工作流程時設定第一個 Python 工作時所使用的相同路徑。再次按兩下 [ 新增組態 ]。 在
Key文字盒中, 輸入contribs-path。 在Value文本框中,輸入將寫入 GitHub 記錄的 DBFS 路徑。 這可以是您選擇的任何路徑,而且是在建立工作流程時設定第二個 Python 工作時所使用的相同路徑。在 [ 目標] 欄位中,輸入目標資料庫, 例如
github_tables。 設定目標資料庫會將輸出數據發佈至中繼存放區,而且是分析管線所產生數據的下游查詢的必要專案。按一下 [檔案] 。
步驟 4:建立工作流程來內嵌和轉換 GitHub 數據
使用 Databricks SQL 分析 GitHub 資料並將其可視化之前,您需要內嵌和準備數據。 若要建立工作流程以完成這些工作,請執行下列步驟:
建立 Azure Databricks 作業並新增第一個工作
移至您的 Azure Databricks 登陸頁面,並執行下列其中一項:
- 在提要欄位中,按兩下 [工作流程],然後按下 。

- 在提要欄位中,按兩下 [新增 ],然後從功能表中選取 [作業 ]。
- 在提要欄位中,按兩下
在 [工作] 索引標籤上出現的 [工作] 對話框中,以您的作業名稱取代 [新增工作名稱...],例如 。
GitHub analysis workflow。在 [ 工作名稱] 中,輸入工作的名稱,例如
get_commits。在 [ 類型] 中,選取 [Python 腳本]。
在 [來源] 中,選取 [DBFS / S3]。
在 [路徑] 中,輸入 DBFS 中腳本的路徑。
在 [ 參數] 中,輸入 Python 腳本的下列自變數:
["<owner>","<repo>","commits","<DBFS-output-dir>","<scope-name>","<github-token-key>"]- 將取代
<owner>為存放庫擁有者的名稱。 例如,若要從存放庫擷github.com/databrickslabs/overwatch取記錄,請輸入databrickslabs。 <repo>取代為存放庫名稱,例如overwatch。- 將 取代
<DBFS-output-dir>為 DBFS 中的路徑,以儲存從 GitHub 擷取的記錄。 - 將取代
<scope-name>為您建立以儲存 GitHub 令牌的秘密範圍名稱。 - 將取代
<github-token-key>為您指派給 GitHub 令牌的金鑰名稱。
- 將取代
按兩下 [ 儲存工作]。
新增另一個工作
按兩下
 您剛才建立的工作下方。
您剛才建立的工作下方。在 [ 工作名稱] 中,輸入工作的名稱,例如
get_contributors。在 [類型] 中 ,選取 [Python 腳本] 工作類型。
在 [來源] 中,選取 [DBFS / S3]。
在 [路徑] 中,輸入 DBFS 中腳本的路徑。
在 [ 參數] 中,輸入 Python 腳本的下列自變數:
["<owner>","<repo>","contributors","<DBFS-output-dir>","<scope-name>","<github-token-key>"]- 將取代
<owner>為存放庫擁有者的名稱。 例如,若要從存放庫擷github.com/databrickslabs/overwatch取記錄,請輸入databrickslabs。 <repo>取代為存放庫名稱,例如overwatch。- 將 取代
<DBFS-output-dir>為 DBFS 中的路徑,以儲存從 GitHub 擷取的記錄。 - 將取代
<scope-name>為您建立以儲存 GitHub 令牌的秘密範圍名稱。 - 將取代
<github-token-key>為您指派給 GitHub 令牌的金鑰名稱。
- 將取代
按兩下 [ 儲存工作]。
新增工作以轉換數據
- 按兩下 您剛才建立的工作下方。
- 在 [ 工作名稱] 中,輸入工作的名稱,例如
transform_github_data。 - 在 [類型] 中,選取 [ 差異實時數據表] 管線 ,然後輸入工作的名稱。
- 在 [管線] 中,選取在步驟 3:建立 Delta Live Tables 管線中 建立的管線,以處理 GitHub 數據。
- 按一下 [建立]。
步驟 5:執行數據轉換工作流程
按兩下 ![[立即執行] 按鈕](../../../_static/images/workflows/jobs/run-now-button.png) 即可執行工作流程。 若要檢視執行的詳細數據,請按下作業執行檢視中執行之 [開始時間] 資料行中的連結。 按兩下每個工作以檢視工作執行的詳細數據。
即可執行工作流程。 若要檢視執行的詳細數據,請按下作業執行檢視中執行之 [開始時間] 資料行中的連結。 按兩下每個工作以檢視工作執行的詳細數據。
步驟 6:(選擇性) 若要在工作流程執行完成之後檢視輸出數據,請執行下列步驟:
- 在 [執行詳細數據] 檢視中,按兩下 [Delta Live Tables] 工作。
- 在 [工作執行詳細數據] 面板中,按兩下 [管線] 底下的管線名稱。 [ 管線詳細數據] 頁面隨即顯示。
commits_by_author選取管線 DAG 中的數據表。- 在 [commits_by_author] 面板中,按兩下 [中繼存放區] 旁的數據表名稱。 [目錄總管] 頁面隨即開啟。
在目錄總管中,您可以檢視數據表架構、範例數據,以及其他數據的詳細數據。 請遵循相同的步驟來檢視數據表的數據 github_contributors_raw 。
步驟 7:移除 GitHub 數據
在真實世界中,您可能會持續擷取和處理數據。 由於此範例會下載並處理整個數據集,因此您必須移除已下載的 GitHub 數據,以避免重新執行工作流程時發生錯誤。 若要移除下載的數據,請執行下列步驟:
建立新的筆記本,並在第一個數據格中輸入下列命令:
dbutils.fs.rm("<commits-path", True) dbutils.fs.rm("<contributors-path", True)將和
<contributors-path>取代<commits-path>為您在建立 Python 工作時所設定的 DBFS 路徑。按兩下
 並選取[ 執行儲存格]。
並選取[ 執行儲存格]。
您也可以將此筆記本新增為工作流程中的工作。
步驟 8:建立 Databricks SQL 查詢
執行工作流程並建立必要的數據表之後,請建立查詢來分析備妥的數據。 若要建立範例查詢和視覺效果,請執行下列步驟:
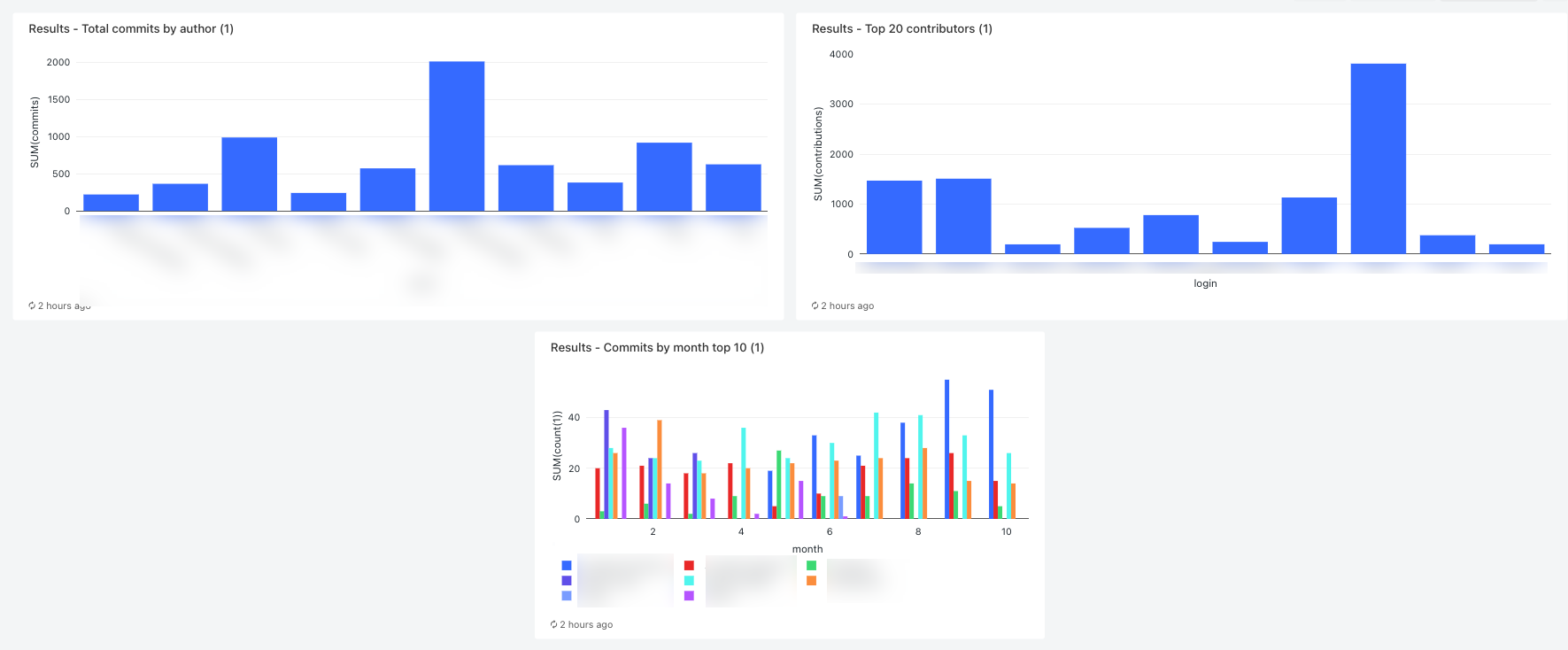
依月份顯示前10名參與者
按兩下提要欄中 Databricks 標誌
 下方的圖示,然後選取 [ SQL]。
下方的圖示,然後選取 [ SQL]。按兩下 [建立查詢 ] 以開啟 Databricks SQL 查詢編輯器。
請確定目錄已設定為 hive_metastore。 按兩下 [hive_metastore旁的預設值,並將資料庫設定為您在 Delta Live Tables 管線中設定的目標值。
在 [ 新增查詢] 索引標籤中,輸入下列查詢:
SELECT date_part('YEAR', date) AS year, date_part('MONTH', date) AS month, name, count(1) FROM commits_by_author WHERE name IN ( SELECT name FROM commits_by_author GROUP BY name ORDER BY count(name) DESC LIMIT 10 ) AND date_part('YEAR', date) >= 2022 GROUP BY name, year, month ORDER BY year, month, name點選 「新增查詢」 索引標籤,然後重新命名查詢,例如
Commits by month top 10 contributors。根據預設,結果會顯示為資料表。 若要變更數據可視化的方式,例如使用條形圖,請在 [ 結果 ] 面板中按兩下
 並按兩下 [ 編輯]。
並按兩下 [ 編輯]。在 [ 視覺效果類型] 中,選取 [ 列]。
在 [X] 數據行中,選取 [月份]。
在 Y 資料列中,選取 count(1) 。
在 [ 群組依據] 中,選取 [名稱]。
按一下 [檔案] 。
顯示前20名參與者
按兩下 [+ > 建立新查詢 ],並確定目錄已設定為 [hive_metastore]。 按兩下 [hive_metastore旁的預設值,並將資料庫設定為您在 Delta Live Tables 管線中設定的目標值。
輸入下列查詢:
SELECT login, cast(contributions AS INTEGER) FROM github_contributors_raw ORDER BY contributions DESC LIMIT 20點選 「新增查詢」 索引標籤,然後重新命名查詢,例如
Top 20 contributors。若要從預設數據表變更視覺效果,請在 [結果] 面板中,按兩下
並按兩下 [編輯]。在 [ 視覺效果類型] 中,選取 [ 列]。
在 [X] 數據行中,選取 [登入]。
在 Y 數據行中,選取 [ 貢獻]。
按一下 [檔案] 。
顯示作者的認可總數
按兩下 [+ > 建立新查詢 ],並確定目錄已設定為 [hive_metastore]。 按兩下 [hive_metastore旁的預設值,並將資料庫設定為您在 Delta Live Tables 管線中設定的目標值。
輸入下列查詢:
SELECT name, count(1) commits FROM commits_by_author GROUP BY name ORDER BY commits DESC LIMIT 10點選 「新增查詢」 索引標籤,然後重新命名查詢,例如
Total commits by author。若要從預設數據表變更視覺效果,請在 [結果] 面板中,按兩下
並按兩下 [編輯]。在 [ 視覺效果類型] 中,選取 [ 列]。
在 [X] 資料行中,選取 [名稱]。
在 Y 數據行中,選取 [ 認可]。
按一下 [檔案] 。
步驟 9:建立儀錶板
- 在提要欄位中,按兩下 [
 儀錶板]
儀錶板] - 按兩下 [ 建立儀錶板]。
- 輸入儀表板的名稱,例如
GitHub analysis。 - 針對在步驟 8:建立 Databricks SQL 查詢中建立的每個查詢和視覺效果,按兩下 [新增>視覺效果],然後選取每個視覺效果。
步驟 10:將 SQL 工作新增至工作流程
若要將新的查詢工作新增至您在建立 Azure Databricks 作業中 建立的工作流程,並新增第一個工作,請針對您在步驟 8:建立 Databricks SQL 查詢中 建立的每個查詢:
- 按兩下 提要欄位中的 [工作流程 ]。
- 在 [ 名稱] 資料行中,按兩下作業名稱。
- 按兩下 [工作] 索引標籤。
- 按兩下 最後一項工作下方。
- 輸入工作的名稱、在 [類型] 中選取 [SQL],然後在 [SQL 工作] 中選取 [查詢]。
- 在 SQL 查詢中選取查詢。
- 在 SQL 倉儲中,選取無伺服器 SQL 倉儲或 Pro SQL 倉儲來執行工作。
- 按一下 [建立]。
步驟 11:新增儀錶板工作
- 按兩下 最後一項工作下方。
- 輸入工作的名稱,在 [類型] 中選取 [SQL],然後在 [SQL 工作] 中選取 [舊版儀錶板]。
- 選取在步驟 9:建立儀錶板中 建立的儀錶板。
- 在 SQL 倉儲中,選取無伺服器 SQL 倉儲或 Pro SQL 倉儲來執行工作。
- 按一下 [建立]。
步驟 12:執行完整的工作流程
若要執行工作流程,請按下 。 若要檢視執行的詳細數據,請按下作業執行檢視中執行之 [開始時間] 資料行中的連結。
步驟 13:檢視結果
若要在執行完成時檢視結果,請按下最終儀錶板工作,然後按下右側面板中 SQL 儀錶板下的儀錶板名稱。
意見反映
即將推出:我們會在 2024 年淘汰 GitHub 問題,並以全新的意見反應系統取代並作為內容意見反應的渠道。 如需更多資訊,請參閱:https://aka.ms/ContentUserFeedback。
提交及檢視以下的意見反映: