HDInsight on AKS 中的 Apache Flink® 組態管理
注意
AKS 上的 Azure HDInsight 將於 2025 年 1 月 31 日退場。 請於 2025 年 1 月 31 日之前,將工作負載移轉至 Microsoft Fabric 或對等的 Azure 產品,以免工作負載突然終止。 訂用帳戶中剩餘的叢集將會停止,並會從主機移除。
在淘汰日期之前,只有基本支援可用。
重要
此功能目前為預覽功能。 Microsoft Azure 預覽版增補使用規定包含適用於 Azure 功能 (搶鮮版 (Beta)、預覽版,或尚未正式發行的版本) 的更多法律條款。 若需此特定預覽版的相關資訊,請參閱 Azure HDInsight on AKS 預覽版資訊。 如有問題或功能建議,請在 AskHDInsight 上提交要求並附上詳細資料,並且在 Azure HDInsight 社群上追蹤我們以獲得更多更新資訊。
HDInsight on AKS 提供 Apache Flink 的一組預設組態,適用於大部分屬性和一些以一般應用程式設定檔為基礎的設定。 不過,如果您需要調整 Flink 組態屬性,以改善具有狀態使用方式、平行處理原則或記憶體設定之特定應用程式的效能,您可以使用 AKS 上的 HDInsight 叢集中的 [Flink 作業] 區段來變更 Flink 作業組態。
移至 [設定] > [Flink 作業] > 按一下 [更新]。
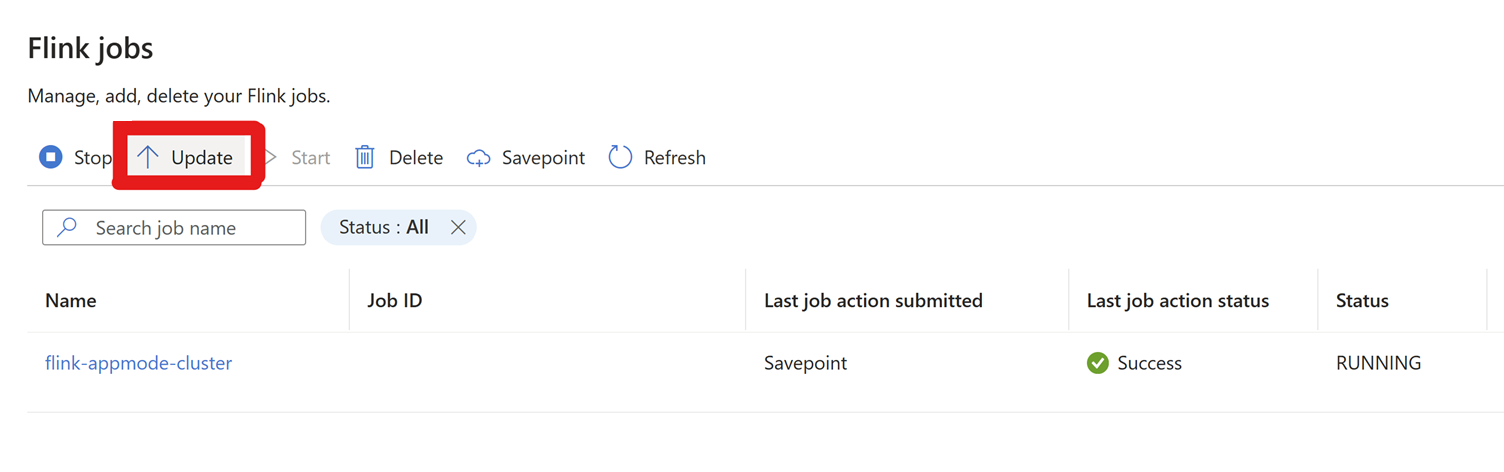
按一下 [+ 新增資料列] 以編輯組態。
檢查點間隔在此會於叢集層級變更。
按兩下 [確定] 更新變更,然後 [儲存]。
儲存之後,新的組態會在幾分鐘內更新 (~5 分鐘)。
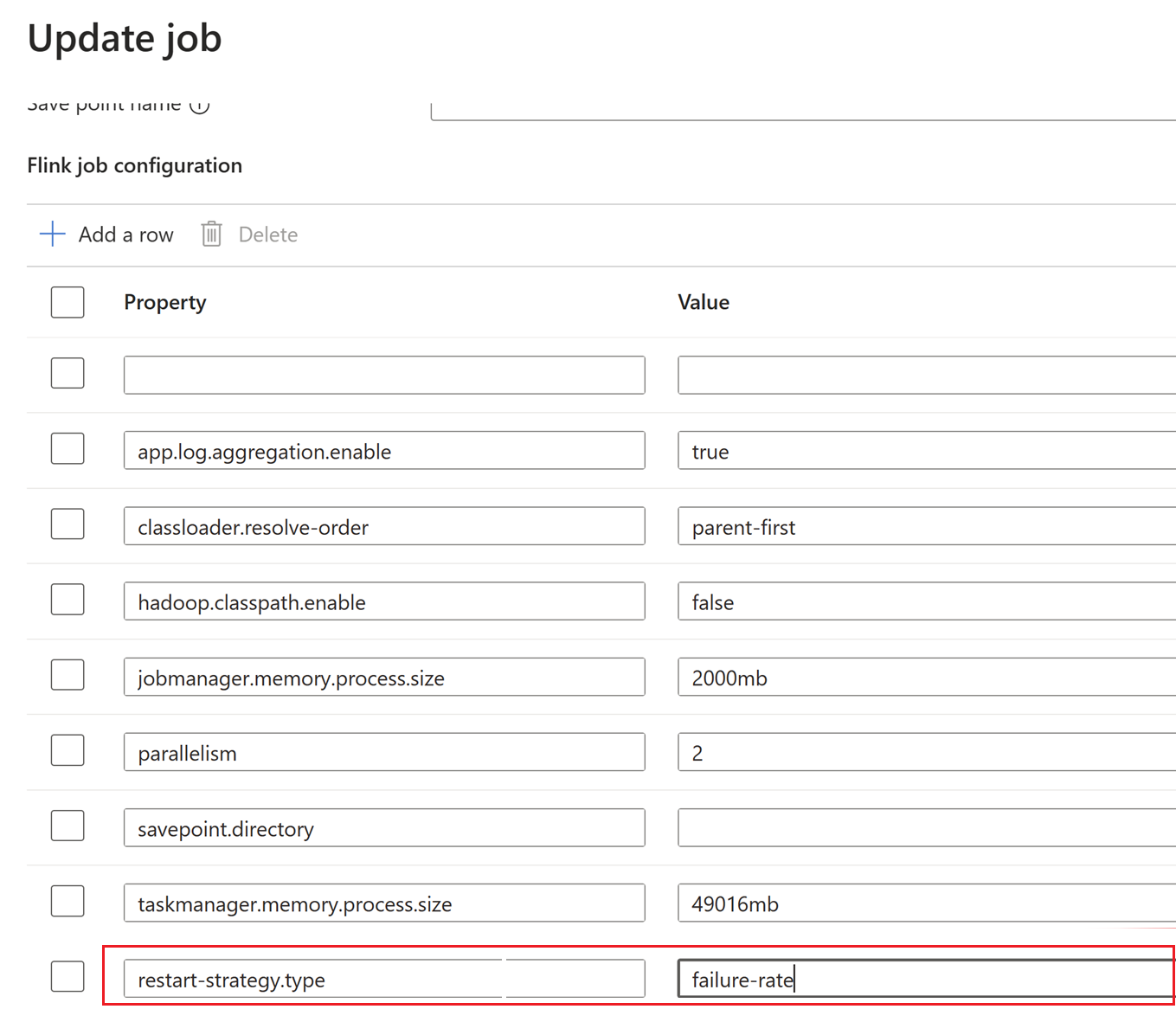
組態,可使用組態管理設定來更新。
processMemory size:處理記憶體大小或作業管理員和工作管理員的預設設定,是使用者在叢集建立期間所設定的記憶體。
您可以使用下列組態屬性來設定此大小。 若要變更工作管理員處理記憶體,請使用此設定。
taskmanager.memory.process.size : <value>範例:
taskmanager.memory.process.size : 2000mb針對作業管理員
jobmanager.memory.process.size : <value>注意
可將處理記憶體上限設定為等於
jobmanager/taskmanager設定的記憶體。


檢查點間隔
檢查點間隔會決定 Flink 觸發檢查點的頻率。 以毫秒為單位定義,且可使用下列組態屬性來設定
execution.checkpoint.interval: <value>
預設為 60,000 毫秒 (1 分鐘),此值可以視需球變更。
狀態後端
狀態後端會決定 Flink 如何管理和保存應用程式的狀態。 這會影響檢查點的儲存方式。 您可以使用下列屬性來設定「狀態後端」:
state.backend: <value>
根據預設,HDInsight on AKS 中的 Apache Flink 叢集會使用 Rocks DB。
檢查點儲存路徑
我們預設允許持續性檢查點,方法是將檢查點儲存在使用者所設定的 abfs 記憶體中。 即使作業失敗,因為會保存檢查點,所以可以輕鬆地開始使用最新的檢查點。
state.checkpoints.dir: <path> 將 <path> 取代為儲存檢查點所需的路徑。
根據預設,會儲存在使用者所設定的儲存體帳戶 (ABFS) 中。 只要 Flink Pod 可以存取這個值,就可以變更為所需的任何路徑。
同時檢查點上限
您可以設定下列屬性來限制同時檢查點數目上限:checkpoint.max-concurrent-checkpoints: <value>
以所需的同時檢查點數目上限取代 <value>。 例如,1 會一次允許一個檢查點。
保留檢查點上限
您可以設定下列屬性來限制保留檢查點數目上限:state.checkpoints.num-retained: <value> 以所需的最大數目取代 <value>。 根據預設,保留最多五個檢查點。
儲存點儲存路徑
我們預設允許持續性儲存點,方法是將儲存點儲存在 abfs 記憶體中 (根據使用者設定)。 如果使用者想要停止並稍後使用特定儲存點啟動作業,他們可以設定此位置。
state.checkpoints.dir:<path> 將 <path> 取代為儲存點所需的路徑。
根據預設,會儲存在使用者所設定的儲存體帳戶中。 (我們支援 ABFS)。 只要 Flink Pod 可以存取這個值,就可以變更為所需的任何路徑。
工作管理高可用性
在 HDInsight on AKS 中,Flink 會使用 Kubernetes 作為後端。 即使作業管理員因為任何已知/未知的問題而失敗,Pod 會在幾秒鐘內重新啟動。 因此,即使作業因為此問題而重新啟動,作業仍會從最新的檢查點復原。
常見問題集
為什麼兩者之間的作業會失敗? 即使作業突然失敗,如果檢查點持續發生,則作業預設會從最新的檢查點重新啟動。
在兩者之間變更作業策略嗎? 有一些使用案例,因為某些作業層級錯誤,需要在生產環境中修改作業。 在此期間,使用者可以停止工作,這會自動取得儲存點,並儲存在儲存點位置。
按一下
savepoint並等候savepoint完成。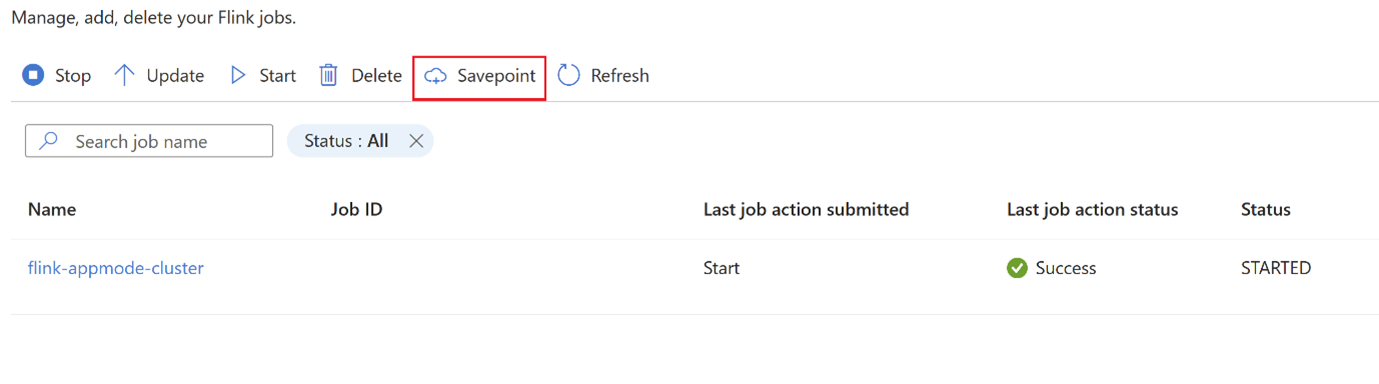
儲存點完成之後,按一下 [開始],而 [啟動作業] 索引標籤隨即出現。 從下拉式清單中選取儲存點名稱。 視需要編輯任何組態。 然後按一下 [確定]。
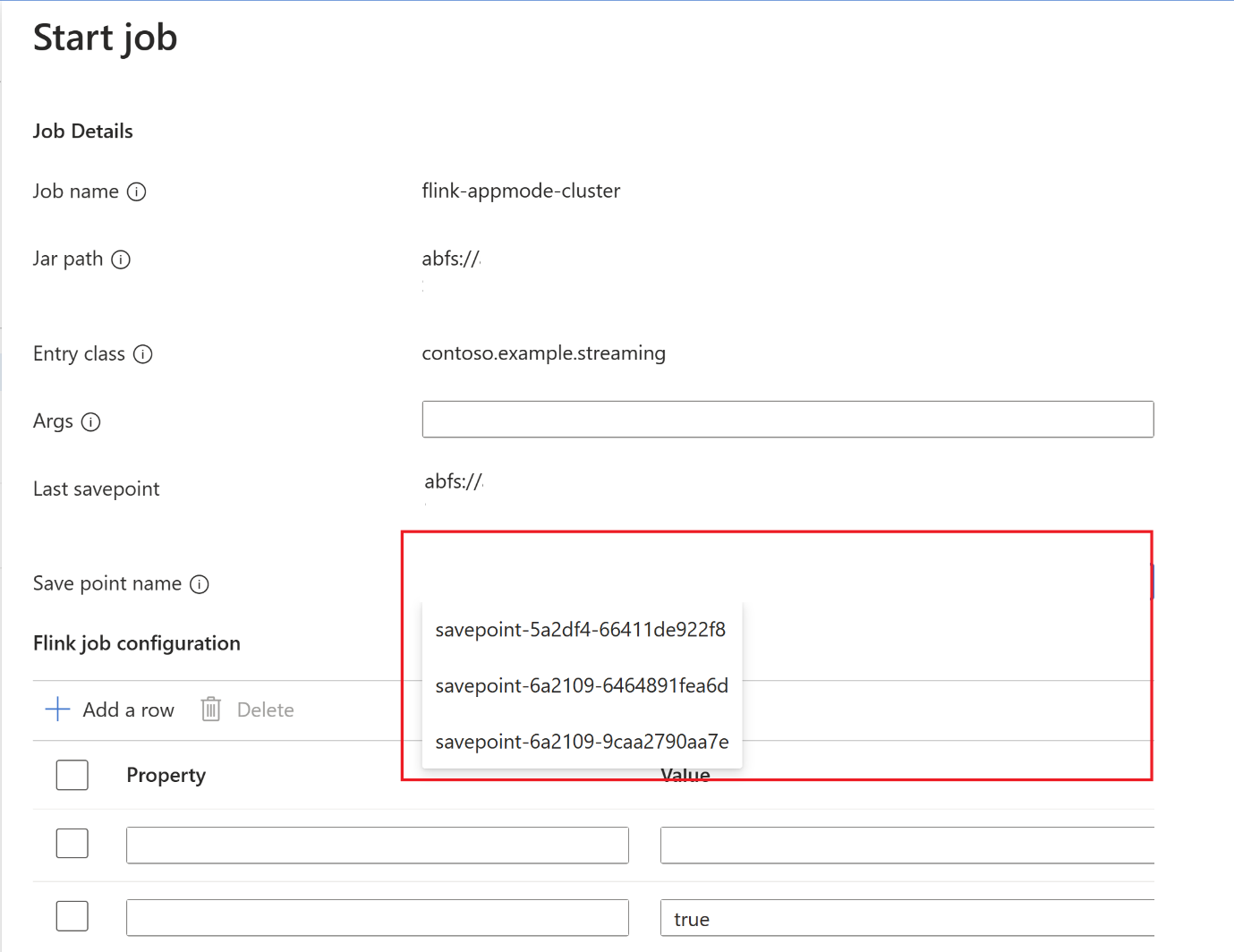


由於儲存點是在作業中提供,因此 Flink 知道從何處開始處理資料。
參考
- Apache Flink 設定
- Apache、Apache Kafka、Kafka、Apache Flink、Flink 和相關聯的開放原始碼專案名稱是 Apache Software Foundation (ASF) 的商標。