AKS 上 HDInsight 上 Apache Flink® 叢集中的資料表 API 和 SQL
重要
此功能目前為預覽功能。 適用於 Microsoft Azure 預覽版的補充使用規定包含適用於 Beta 版、預覽版或尚未發行至正式運作之 Azure 功能的更合法條款。 如需此特定預覽的相關信息,請參閱 AKS 預覽資訊的 Azure HDInsight。 如需問題或功能建議,請在 AskHDInsight 上提交要求,並提供詳細數據,並遵循我們在 Azure HDInsight 社群上取得更多更新。
Apache Flink 有兩個關係 API - 資料表 API 和 SQL - 用於統一資料流和批次處理。 資料表 API 是一種 Language-integrated Query (LINQ) API,它允許從關係運算子 (例如選取、篩選和直覺式聯結) 組合查詢。 Flink 的 SQL 支援是以實作 SQL 標準的 Apache Calcite 為基礎。
資料表 API 和 SQL 介面可與彼此以及 Flink 的 DataStream API 無縫整合。 您可以輕鬆地在所有 API 和基於它們建置的程式庫之間切換。
Apache Flink SQL
與其他 SQL 引擎一樣,Flink 查詢會在資料表之上運作。 它與傳統資料庫不同,因為 Flink 不會在本機管理待用資料;相反地,它的查詢會持續在外部資料表上運作。
Flink 資料處理管線會以來源資料表開頭,並以接收資料表結尾。 來源資料表會產生查詢執行期間操作的資料列;它們是查詢的 FROM 子句中所參考的資料表。 連接器的類型可以是 HDInsight Kafka、HDInsight HBase、Azure 事件中樞、資料庫、文件系統,或連接器位於 classpath 的任何其他系統。
在 AKS 叢集的 HDInsight 中使用 Flink SQL 用戶端
您可以參考本文,了解如何從 Azure 入口網站上的 安全殼層 使用 CLI。 以下是一些如何開始使用的快速範例。
啟動 SQL 用戶端
./bin/sql-client.sh傳遞初始化 SQL 檔案以與 sql-client 一起執行
./sql-client.sh -i /path/to/init_file.sql在 sql-client 中設定組態
SET execution.runtime-mode = streaming; SET sql-client.execution.result-mode = table; SET sql-client.execution.max-table-result.rows = 10000;
SQL DDL
Flink SQL 支援下列 CREATE 陳述式
- 建立資料表
- CREATE DATABASE
- CREATE CATALOG
以下是使用 jdbc 連接器來定義來源資料表的範例語法,以連線至識別碼、名稱做為 CREATE TABLE 陳述式中資料行的 MSSQL
CREATE TABLE student_information (
id BIGINT,
name STRING,
address STRING,
grade STRING,
PRIMARY KEY (id) NOT ENFORCED
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:sqlserver://servername.database.windows.net;database=dbname;encrypt=true;trustServerCertificate=true;create=false;loginTimeout=30',
'table-name' = 'students',
'username' = 'username',
'password' = 'password'
);
CREATE DATABASE :
CREATE DATABASE students;
CREATE CATALOG:
CREATE CATALOG myhive WITH ('type'='hive');
您可以在這些資料表頂端執行連續查詢
SELECT id,
COUNT(*) as student_count
FROM student_information
GROUP BY grade;
從 來源資料表 寫入至 接收資料表:
INSERT INTO grade_counts
SELECT id,
COUNT(*) as student_count
FROM student_information
GROUP BY grade;
新增相依性
JAR 陳述式可用來將使用者 JAR 新增至 classpath,或從 classpath 中移除使用者 JAR,或在執行階段的 classpath 中顯示新增的 JAR。
Flink SQL 支援下列 JAR 陳述式:
- 新增 JAR
- 顯示 JAR
- 移除 JAR
Flink SQL> ADD JAR '/path/hello.jar';
[INFO] Execute statement succeed.
Flink SQL> ADD JAR 'hdfs:///udf/common-udf.jar';
[INFO] Execute statement succeed.
Flink SQL> SHOW JARS;
+----------------------------+
| jars |
+----------------------------+
| /path/hello.jar |
| hdfs:///udf/common-udf.jar |
+----------------------------+
Flink SQL> REMOVE JAR '/path/hello.jar';
[INFO] The specified jar is removed from session classloader.
AKS 上 HDInsight 上 Apache Flink® 叢集中的 Hive 中繼存放區
目錄會提供中繼資料,例如資料庫、資料表、分割區、檢視和函式,以及存取儲存在資料庫或其他外部系統中之資料所需的資訊。
在 AKS 上的 HDInsight 中,我們支援兩個目錄選項:
GenericInMemoryCatalog
GenericInMemoryCatalog 是目錄的記憶體內部實作。 所有物件僅適用於 SQL 工作階段的存留期。
HiveCatalog
HiveCatalog 有兩個用途: 作為純 Flink 中繼資料的持久儲存體,以及作為讀寫現有 Hive 中繼資料的介面。
注意
AKS 叢集上的 HDInsight 隨附適用於 Apache Flink 的 Hive 中繼存放區整合選項。 在叢集建立期間選取 Hive 中繼存放區
如何建立和註冊 Flink 資料庫至目錄
您可以參考本文,了解如何從 Azure 入口網站上的 安全殼層 使用 CLI 以及開始使用 Flink SQL 用戶端。
啟動
sql-client.sh工作階段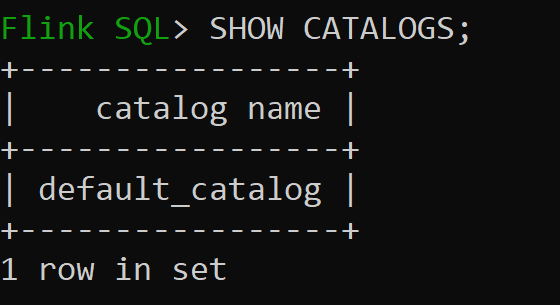
Default_catalog 是預設的記憶體內目錄
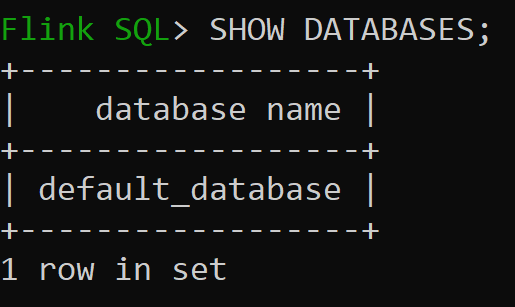
現在讓我們來檢查記憶體內部目錄的預設資料庫
讓我們建立 3.1.2 版的 Hive 目錄,並使用它
CREATE CATALOG myhive WITH ('type'='hive'); USE CATALOG myhive;注意
AKS 上的 HDInsight 支援 Hive 3.1.2 和 Hadoop 3.3.2。
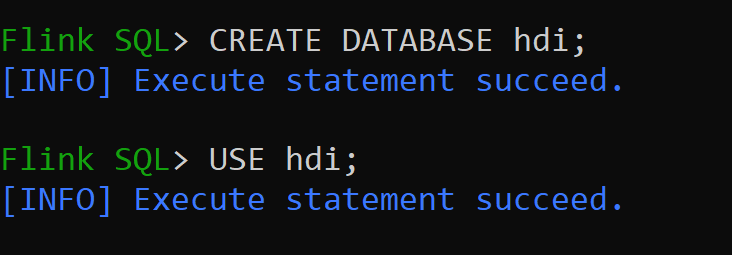
hive-conf-dir已設定為位置/opt/hive-conf讓我們在 Hive 目錄中建立資料庫,並將它設為工作階段的預設值 (除非已變更)。
如何將 Hive 資料表建立及註冊至 Hive 目錄
請遵循 如何建立和註冊 Flink 資料庫至目錄 的指引
讓我們建立不帶分割區的 Hive 連接器類型的 Flink 資料表
CREATE TABLE hive_table(x int, days STRING) WITH ( 'connector' = 'hive', 'sink.partition-commit.delay'='1 s', 'sink.partition-commit.policy.kind'='metastore,success-file');將資料插入 hive_table 中
INSERT INTO hive_table SELECT 2, '10'; INSERT INTO hive_table SELECT 3, '20';從 hive_table 讀取資料
Flink SQL> SELECT * FROM hive_table; 2023-07-24 09:46:22,225 INFO org.apache.hadoop.mapred.FileInputFormat[] - Total input files to process : 3 +----+-------------+--------------------------------+ | op | x | days | +----+-------------+--------------------------------+ | +I | 3 | 20 | | +I | 2 | 10 | | +I | 1 | 5 | +----+-------------+--------------------------------+ Received a total of 3 rows注意
Hive Warehouse Directory 位於 Apache Flink 叢集建立期間所選儲存體帳戶的指定容器中,其位於目錄 hive/warehouse/
讓我們建立有分割區的 Hive 連接器類型的 Flink 資料表
CREATE TABLE partitioned_hive_table(x int, days STRING) PARTITIONED BY (days) WITH ( 'connector' = 'hive', 'sink.partition-commit.delay'='1 s', 'sink.partition-commit.policy.kind'='metastore,success-file');
重要
Apache Flink 中有已知的限制。 無論使用者定義的分割區資料行爲何,都會選擇最後「n」個資料行進行分割。 FLINK-32596 使用 Flink 方言建立 Hive 資料表時,分割索引鍵將會錯誤。
參考
- Apache Flink 資料表 API 和 SQL
- Apache、Apache Flink、Flink 和相關聯的開放原始碼專案名稱為 Apache Software Foundation (ASF) 的 商標。
意見反映
即將推出:我們會在 2024 年淘汰 GitHub 問題,並以全新的意見反應系統取代並作為內容意見反應的渠道。 如需更多資訊,請參閱:https://aka.ms/ContentUserFeedback。
提交及檢視以下的意見反映: