使用適用於 Eclipse 的 Azure 工具組建立 HDInsight 叢集的 Apache Spark 應用程式
使用適用於 Eclipse 的 Azure 工具組中的 HDInsight 工具,直接從 Eclipse IDE 開發以 Scala 撰寫的 Apache Spark 應用程式,並將其提交至 Azure HDInsight Spark 叢集。 您可以透過幾種不同的方式使用 HDInsight 工具外掛程式:
- 在 HDInsight Spark 叢集上開發和提交 Scala Spark 應用程式。
- 若要存取您的 Azure HDInsight Spark 叢集資源。
- 在本機開發和執行 Scala Spark 應用程式。
必要條件
HDInsight 上的 Apache Spark 叢集。 如需指示,請參閱在 Azure HDInsight 中建立 Apache Spark 叢集。
Eclipse IDE。 本文使用適用於 Java 開發人員的 Eclipse IDE。
安裝必要的外掛程式
安裝 Azure Toolkit for Eclipse
如需安裝指示,請參閱 安裝適用於 Eclipse 的 Azure 工具組。
安裝 Scala 外掛程式
當您開啟 Eclipse 時,HDInsight 工具會自動偵測您是否已安裝 Scala 外掛程式。 選取 [ 確定 ] 以繼續,然後依照指示從 Eclipse Marketplace 安裝外掛程式。 安裝完成之後,請重新啟動IDE。

確認外掛程式
流覽至 [說明>Eclipse Marketplace...]。
選取 [已安裝] 索引標籤。
您應該至少會看到:
- 適用於 Eclipse <的 Azure 工具組版本>。
- Scala IDE <版本>。
登入您的 Azure 訂用帳戶
啟動 Eclipse IDE。
瀏覽至視窗>顯示檢視>其他...>Sign In...
從 [顯示檢視] 對話框,流覽至 [Azure Azure>總管],然後選取 [開啟]。

從 Azure Explorer,以滑鼠右鍵按兩下 Azure 節點,然後選取 [ 登入]。
在 [ Azure 登入 ] 對話方塊中,選擇驗證方法、選取 [登入],然後完成登入程式。

登入之後,[ 您的訂用帳戶 ] 對話框會列出與認證相關聯的所有 Azure 訂用帳戶。 按 [選取 ] 關閉對話框。

從 Azure Explorer 瀏覽至 Azure>HDInsight,以查看訂用帳戶底下的 HDInsight Spark 叢集。

您可以進一步展開叢集名稱節點,以查看與叢集相關聯的資源(例如記憶體帳戶)。

連結叢集
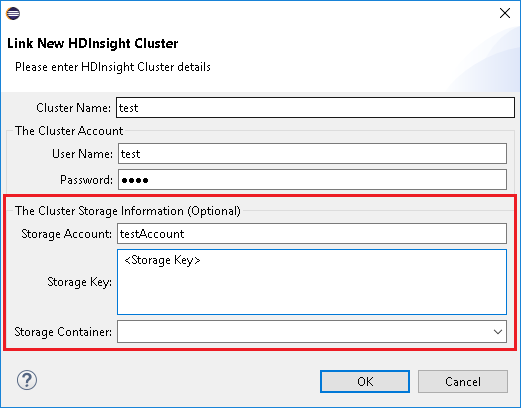
您可以使用Ambari受控使用者名稱連結一般叢集。 同樣地,針對已加入網域的 HDInsight 叢集,您可以使用網域和使用者名稱連結,例如 user1@contoso.com。
從 [Azure 總管] 中,以滑鼠右鍵按兩下 [HDInsight],然後選取 [ 鏈接叢集]。

輸入 [叢集名稱]、 [用戶名稱] 和 [密碼],然後選取 [ 確定]。 或者,輸入 儲存體 帳戶,儲存體 金鑰,然後選取 儲存體 [容器] 以在左側樹視圖中運作

注意
如果叢集同時登入 Azure 訂用帳戶和連結叢集,我們會使用連結的記憶體密鑰、使用者名稱和密碼。

只有鍵盤使用者,當目前的焦點位於 儲存體 鍵時,您必須使用 Ctrl+TAB 將焦點放在對話框中的下一個字段。
您可以在 HDInsight 底下看到連結的叢集。 現在您可以將應用程式提交至此連結的叢集。

您也可以從 Azure Explorer 取消連結叢集。

設定 HDInsight Spark 叢集的 Spark Scala 專案
從 Eclipse IDE 工作區中,選取 [檔案>新>專案...]。
在 [新增專案精靈] 中,選取 [HDInsight 上的 HDInsight 專案>Spark] [Scala]。 然後選取下一步。

在 [ 新增 HDInsight Scala 專案 ] 對話框中,提供下列值,然後選取 [ 下一步]:
- 輸入專案的 [名稱] 。
- 在 JRE 區域中,確定 [使用執行環境 JRE ] 設定為 JavaSE-1.7 或更新版本。
- 在 [Spark 連結庫 ] 區域中,您可以選擇 [ 使用 Maven 設定 Spark SDK ] 選項。 此工具整合了適用於 Spark SDK 和 Scala SDK 的適當版本。 您也可以手動選擇 [ 新增 Spark SDK] 選項、下載並手動新增 Spark SDK。
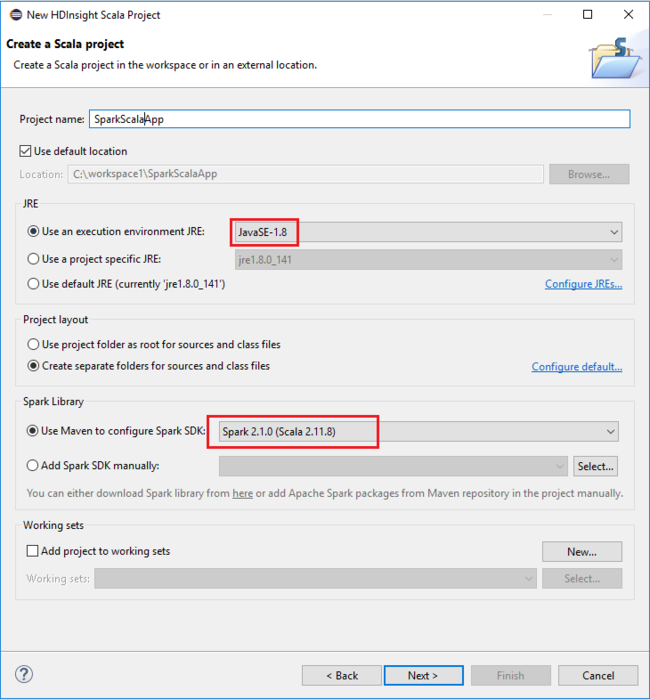
在下一個對話框中,檢閱詳細數據,然後選取 [ 完成]。
建立 HDInsight Spark 叢集的 Scala 應用程式
從 [套件總管] 展開您稍早建立的專案。 以滑鼠右鍵按兩下 src,選取 [新增>其他...]。
在 [選取精靈] 對話框中,選取 [Scala Wizards>Scala 物件]。 然後選取下一步。

在 [ 建立新檔案 ] 對話框中,輸入對象的名稱,然後選取 [ 完成]。 文本編輯器隨即開啟。

在文字編輯器中,以下列程序代碼取代目前的內容:
import org.apache.spark.SparkConf import org.apache.spark.SparkContext object MyClusterApp{ def main (arg: Array[String]): Unit = { val conf = new SparkConf().setAppName("MyClusterApp") val sc = new SparkContext(conf) val rdd = sc.textFile("wasbs:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv") //find the rows that have only one digit in the seventh column in the CSV val rdd1 = rdd.filter(s => s.split(",")(6).length() == 1) rdd1.saveAsTextFile("wasbs:///HVACOut") } }在 HDInsight Spark 叢集上執行應用程式:
a. 在 [套件總管] 中,以滑鼠右鍵按兩下專案名稱,然後選取 [ 將Spark 應用程式提交至 HDInsight]。
b. 在 [ Spark 提交 ] 對話框中,提供下列值,然後選取 [ 提交]:
針對 [ 叢集名稱],選取您要在其中執行應用程式的 HDInsight Spark 叢集。
從 Eclipse 項目中選取成品,或從硬碟中選取一個成品。 預設值取決於您以滑鼠右鍵按兩下 [套件總管] 的專案。
在 [ 主要類別名稱 ] 下拉式清單中,提交精靈會顯示專案中的所有物件名稱。 選取或輸入您想要執行的其中一個。 如果您從硬碟選取成品,則必須手動輸入主要類別名稱。
由於此範例中的應用程式程式代碼不需要任何命令行自變數或參考 JAR 或檔案,因此您可以將其餘的文字框保留空白。
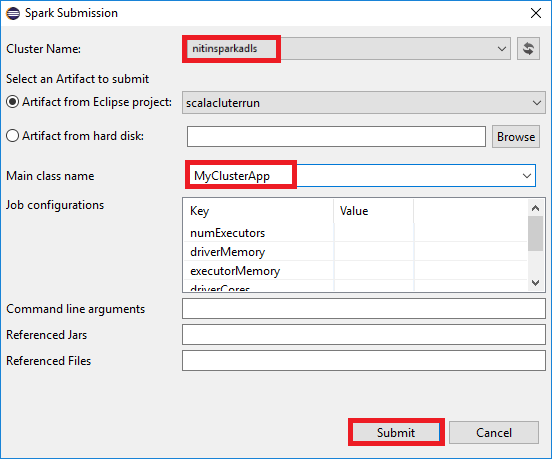
[Spark 提交] 索引標籤應該會開始顯示進度。 您可以選擇[Spark 提交] 視窗中的紅色按鈕來停止應用程式。 您也可以選取地球圖示來檢視此特定應用程式執行的記錄(以影像中的藍色方塊表示)。

在 Azure Toolkit for Eclipse 中使用 HDInsight 工具存取和管理 HDInsight Spark 叢集
您可以使用 HDInsight 工具來執行各種作業,包括存取作業輸出。
存取作業檢視
在 Azure Explorer 中,展開 [HDInsight],然後展開 [Spark 叢集名稱],然後選取 [作業]。

選取 [ 作業] 節點。 如果 Java 版本低於 1.8,HDInsight 工具會自動提醒您安裝 E(fx)clipse 外掛程式。 選取 [ 確定 ] 以繼續,然後遵循精靈從 Eclipse Marketplace 安裝它,然後重新啟動 Eclipse。

從 [作業 ] 節點開啟 [作業檢視]。 在右窗格中,[ Spark 作業檢視 ] 索引卷標會顯示叢集上執行的所有應用程式。 選取您想要查看詳細資料的應用程式名稱。

然後,您可以採取下列任何動作:
將滑鼠停留在作業圖形上。 它會顯示執行中作業的基本資訊。 選取作業圖表,您可以看到每個作業產生的階段和資訊。

選取 [記錄] 索引標籤以檢視常用記錄,包括驅動程式 Stderr、Driver Stdout 和目錄資訊。

選取視窗頂端的超連結,以開啟 Spark 歷程記錄 UI 和 Apache Hadoop YARN UI(應用層級)。
存取叢集的記憶體容器
在 Azure Explorer 中 ,展開 HDInsight 根節點,以查看可用的 HDInsight Spark 叢集清單。
展開叢集名稱,以查看記憶體帳戶和叢集的預設記憶體容器。

選取與叢集相關聯的記憶體容器名稱。 在右窗格中,按兩下 HVACOut 資料夾。 開啟其中 一個元件 檔案,以查看應用程式的輸出。
存取 Spark 歷程記錄伺服器
在 Azure 檔案總管中,以滑鼠右鍵按兩下 Spark 叢集名稱,然後選取 [ 開啟 Spark 歷程記錄 UI]。 出現提示時,請輸入叢集的管理員認證。 您在布建叢集時指定了這些專案。
在 Spark 歷程記錄伺服器儀錶板中,您可以使用應用程式名稱來尋找您剛完成執行的應用程式。 在上述程式代碼中,您會使用
val conf = new SparkConf().setAppName("MyClusterApp")來設定應用程式名稱。 因此,您的Spark應用程式名稱為 MyClusterApp。
啟動 Apache Ambari 入口網站
在 Azure 檔案總管中,以滑鼠右鍵按下您的 Spark 叢集名稱,然後選取 [開啟叢集管理入口網站] [Ambari]。
出現提示時,請輸入叢集的管理員認證。 您在布建叢集時指定了這些專案。
管理 Azure 訂用帳戶
根據預設,適用於 Eclipse 的 Azure 工具組中的 HDInsight 工具會列出您所有 Azure 訂用帳戶中的 Spark 叢集。 如有必要,您可以指定要存取叢集的訂用帳戶。
在 Azure Explorer 中,以滑鼠右鍵按兩下 Azure 根節點,然後選取 [ 管理訂用帳戶]。
在對話框中,清除您不想存取之訂用帳戶的複選框,然後選取 [ 關閉]。 如果您想要註銷 Azure 訂用帳戶,也可以選取 [註銷 ]。
在本機執行 Spark Scala 應用程式
您可以使用適用於 Eclipse 的 Azure 工具組中的 HDInsight 工具,在工作站本機上執行 Spark Scala 應用程式。 一般而言,這些應用程式不需要存取叢集資源,例如記憶體容器,而且您可以在本機執行及測試它們。
必要條件
當您在 Windows 電腦上執行本機 Spark Scala 應用程式時,可能會收到例外狀況,如 SPARK-2356 中所述。 發生此例外狀況的原因是 Windows 中遺漏WinUtils.exe 。
若要解決此錯誤,您需要Winutils.exe C:\WinUtils\bin 之類的位置,然後將環境變數HADOOP_HOME,並將變數的值設定為 C\WinUtils。
執行本機 Spark Scala 應用程式
啟動 Eclipse 並建立專案。 在 [ 新增專案 ] 對話框中,進行下列選擇,然後選取 [ 下一步]。
在 [新增專案精靈] 中,選取 HDInsight 本機執行範例 (Scala) 上的 HDInsight 專案>Spark。 然後選取下一步。

若要提供專案詳細數據,請遵循先前一節 中針對 HDInsight Spark 叢集設定 Spark Scala 專案的步驟 3 到 6。
範本會在 src 資料夾下新增範例程式代碼 (LogQuery),您可以在電腦上本機執行。

以滑鼠右鍵按兩下 [LogQuery.scala],然後選取 [執行為>1 Scala 應用程式]。 類似這樣的輸出會出現在 [ 主控台] 索引標籤上:

僅限讀者角色
當使用者將作業提交至具有唯讀角色許可權的叢集時,需要Ambari認證。
從操作功能表連結叢集
使用僅限讀取者角色帳戶登入。
從 Azure Explorer 展開 [HDInsight ] 以檢視訂用帳戶中的 HDInsight 叢集。 標示 為「角色:讀取者」的 叢集只有讀者專用角色許可權。

以滑鼠右鍵按兩下具有唯讀角色許可權的叢集。 從操作功能表選取 [ 連結此叢集 ] 以連結叢集。 輸入Ambari使用者名稱和密碼。

如果叢集已成功連結,則會重新整理 HDInsight。 叢集的階段將會連結。

展開 [作業] 節點來連結叢集
按兩下 [作業] 節點、[叢集作業存取遭拒] 視窗彈出視窗。
按兩下 [ 連結此叢集] 連結叢集 。

從 Spark 提交視窗連結叢集
建立 HDInsight 專案。
以滑鼠右鍵按兩下套件。 然後選取 [ 將Spark 應用程式提交至 HDInsight]。

選取具有叢集名稱唯讀角色許可權的叢集。 警告訊息顯示出來。您可以按下 [ 連結此叢集] 連結叢集 。

檢視 儲存體 帳戶
針對具有唯讀角色許可權的叢集,按兩下 [儲存體 帳戶] 節點,儲存體 [拒絕存取] 視窗彈出視窗。

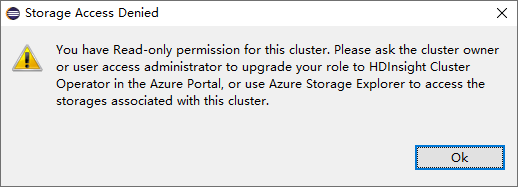
針對連結的叢集,按兩下 [儲存體 帳戶] 節點,儲存體 [拒絕存取] 視窗彈出視窗。

已知問題
使用 連結 A 叢集時,建議您提供記憶體認證。
提交作業有兩種模式。 如果提供記憶體認證,則會使用批次模式來提交作業。 否則,將會使用互動式模式。 如果叢集忙碌中,您可能會收到下列錯誤。


另請參閱
案例
- Apache Spark 和 BI:在 HDInsight 中搭配 BI 工具使用 Spark 執行互動式資料分析
- Apache Spark 和機器學習服務:使用 HDInsight 中的 Spark,使用 HVAC 資料來分析建築物溫度
- Apache Spark 和機器學習服務:在 HDInsight 中使用 Spark 預測食品檢查結果
- 在 HDInsight 中使用 Apache Spark 進行網站記錄分析
建立和執行應用程式
工具和延伸模組
- 使用適用於 IntelliJ 的 Azure 工具組來建立和提交 Spark Scala 應用程式
- 使用適用於 IntelliJ 的 Azure 工具組,透過 VPN 從遠端偵錯 Apache Spark 應用程式
- 使用適用於 IntelliJ 的 Azure 工具組,透過 SSH 從遠端偵錯 Apache Spark 應用程式
- 在 HDInsight 上搭配使用 Apache Zeppelin Notebook 和 Apache Spark 叢集
- 在適用於 HDInsight 的 Apache Spark 叢集中可供 Jupyter Notebook 使用的核心
- 搭配 Jupyter Notebook 使用外部套件
- 在電腦上安裝 Jupyter 並連接到 HDInsight Spark 叢集