訓練
認證
Microsoft Certified: Azure Data Engineer Associate - Certifications
展現對常見資料工程工作的了解,以使用多種 Azure 服務在 Microsoft Azure 上實作和管理資料工程工作負載。
在本快速入門中,您會使用 Azure 入口網站 在 Azure HDInsight 中建立 Apache Spark 叢集。 接著,您會建立 Jupyter Notebook,並用它來對 Apache Hive 數據表執行 Spark SQL 查詢。 Azure HDInsight 是企業受控、全方位、開放原始碼的分析服務。 適用於 HDInsight 的 Apache Spark 架構可使用記憶體內部處理來快速數據分析和叢集運算。 Jupyter Notebook 可讓您與數據互動、將程式代碼與 Markdown 文字結合,以及執行簡單的視覺效果。
如需可用組態的深入說明,請參閱 在 HDInsight 中設定叢集。 如需有關使用入口網站建立叢集的詳細資訊,請參閱 在入口網站中建立叢集。
如果您同時使用多個叢集,您可能想要建立虛擬網路;如果您使用 Spark 叢集,可能也想要使用 Hive Warehouse 連線 or。 如需詳細資訊,請參閱規劃 Azure HDInsight 的虛擬網路,以及整合 Apache Spark 和 Apache Hive 與 Hive Warehouse 連線 or。
重要
無論您是否使用 HDInsight 叢集,HDInsight 叢集的計費會按分鐘計算。 當您完成使用叢集之後,請務必刪除叢集。 如需詳細資訊,請參閱 本文的清除資源 一節。
具有有效訂用帳戶的 Azure 帳戶。 免費建立帳戶。
您可以使用 Azure 入口網站 來建立使用 Azure 儲存體 Blob 作為叢集記憶體的 HDInsight 叢集。 如需使用 Data Lake 儲存體 Gen2 的詳細資訊,請參閱快速入門:在 HDInsight 中設定叢集。
登入 Azure 入口網站。
從頂部功能表選取 [+建立資源]。
選取 [分析>Azure HDInsight ] 以移至 [ 建立 HDInsight 叢集 ] 頁面。
從 [ 基本] 索引 標籤,提供下列資訊:
| 屬性 | 描述 |
|---|---|
| 訂用帳戶 | 從下拉式清單中,選取用於此叢集的 Azure 訂用帳戶。 |
| 資源群組 | 從下拉式清單中選取現有資源群組,或選取 [新建]。 |
| 叢集名稱 | 輸入全域唯一名稱。 |
| 區域 | 從下拉式清單中,選取叢集建立所在的區域。 |
| 可用性區域 | 選擇性 - 指定要在其中部署叢集的可用性區域 |
| 叢集類型 | 選取叢集類型以開啟清單。 從清單中選取 [Spark]。 |
| 叢集版本 | 一旦選取叢集類型,此欄位就會自動填入預設版本。 |
| 叢集登入使用者名稱 | 輸入叢集登入用戶名稱。 預設名稱為 admin。您稍後會在快速入門中使用此帳戶登入 Jupyter Notebook。 |
| 叢集登入密碼 | 輸入叢集登入密碼。 |
| 安全殼層 (SSH) 使用者名稱 | 輸入 SSH 使用者名稱。 本快速入門所使用的SSH用戶名稱是 sshuser。 根據預設,此帳戶會共用與叢集登入使用者名稱帳戶相同的密碼。 |
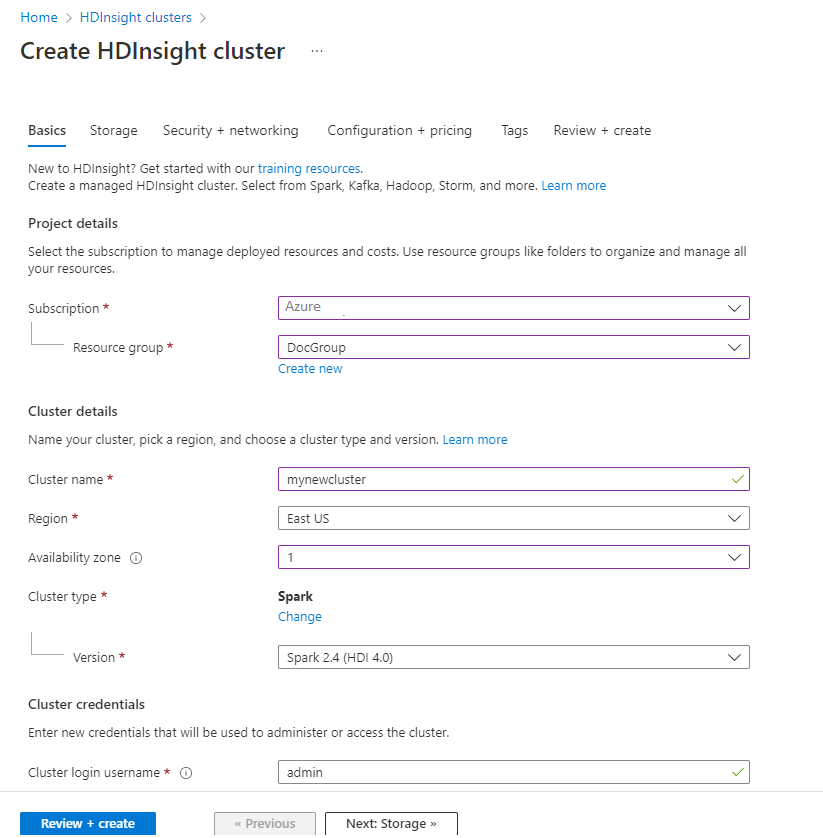
選取 [下一步]:儲存體 >> 以繼續 儲存體 頁面。
在 [儲存體] 下方,提供下列值:
| 屬性 | 說明 |
|---|---|
| 主要儲存體類型 | 使用預設值 Azure 儲存體。 |
| 選取方法 | 使用預設值 [從列表中選取]。 |
| 主要儲存體帳戶 | 使用自動填入的值。 |
| 容器 | 使用自動填入的值。 |
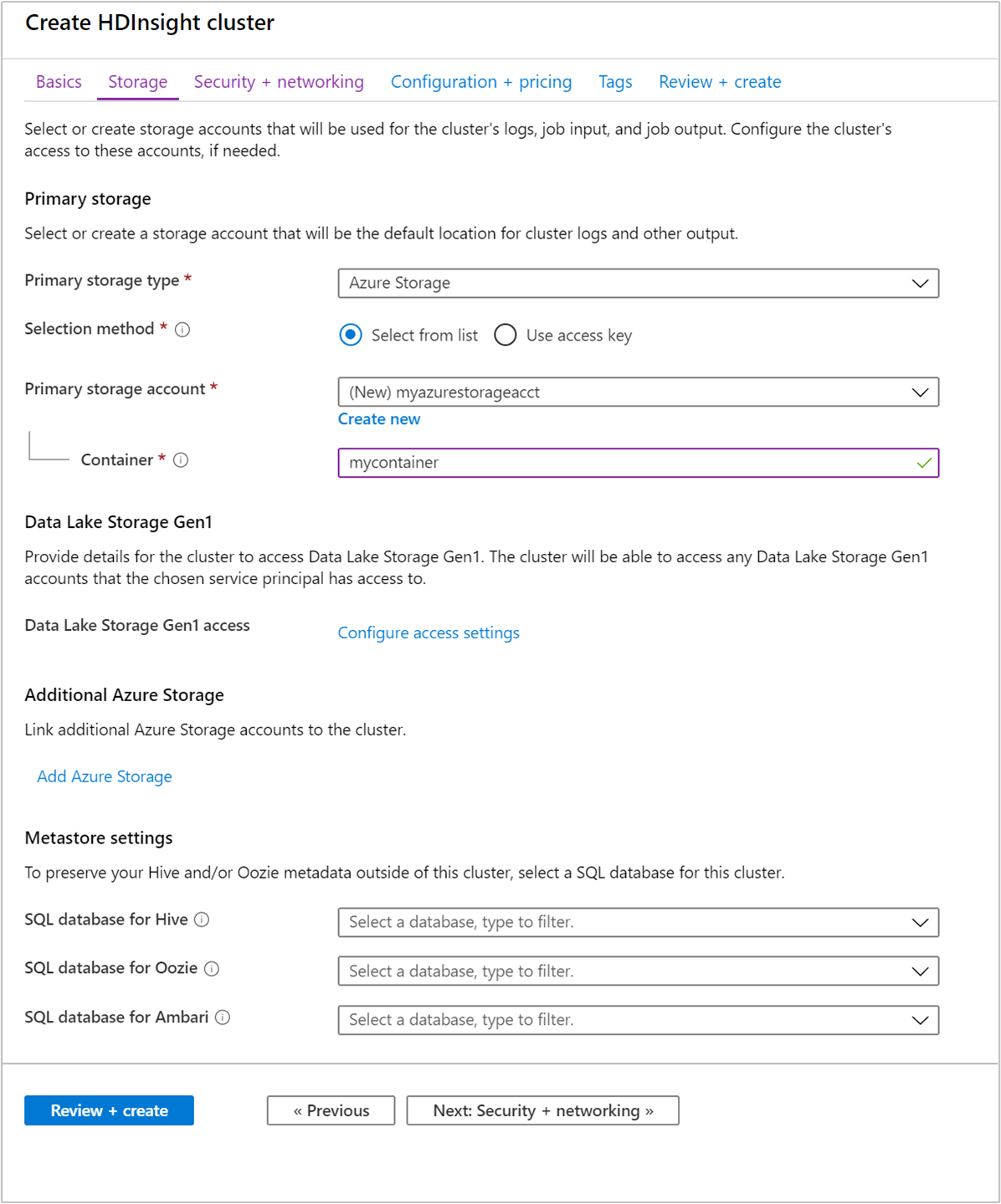
選取 [檢閱 + 建立] 以繼續執行。
在 [檢閱 + 建立] 下,選取 [建立]。 大約需要 20 分鐘的時間來建立叢集。 您必須先建立叢集,才能繼續前往下一個工作階段。
如果您遇到建立 HDInsight 叢集的問題,可能是您沒有適當的許可權可以這麼做。 如需詳細資訊,請參閱 訪問控制需求。
Jupyter Notebook 是支援各種程式設計語言的互動式筆記本環境。 筆記本可讓您與數據互動、將程式代碼與 Markdown 文字結合,以及執行簡單的視覺效果。
從網頁瀏覽器瀏覽至 https://CLUSTERNAME.azurehdinsight.net/jupyter,其中 CLUSTERNAME 是叢集的名稱。 出現提示時,輸入叢集的叢集登入認證。
選取 [新增>PySpark] 以建立筆記本。
系統會建立並開啟名為 Untitled(Untitled.pynb) 的新筆記本。
SQL (結構化查詢語言 (SQL)) 是查詢和定義資料的最常用且廣泛使用的語言。 Spark SQL 函式是 Apache Spark 的擴充功能,可使用熟悉的 SQL 語法來處理結構化數據。
確認核心已就緒。 當您在筆記本中的核心名稱旁邊看到空心圓圈時,核心便已準備就緒。 實心圓表示核心忙碌中。

當您第一次啟動筆記本時,核心會在背景中執行一些工作。 等候核心準備就緒。
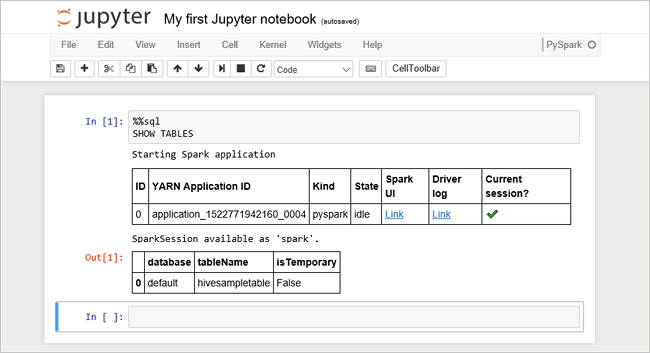
將下列程式代碼貼到空白儲存格中,然後按 SHIFT + ENTER 以執行程式代碼。 命令會列出叢集上的 Hive 資料表:
%%sql
SHOW TABLES
當您搭配 HDInsight 叢集使用 Jupyter Notebook 時,會取得 sqlContext 預設,可用來使用 Spark SQL 執行 Hive 查詢。 %%sql 告知 Jupyter Notebook 使用預設 sqlContext 來執行 Hive 查詢。 查詢會從Hive數據表 (hivesampletable) 擷取前10個數據列,該數據表預設隨附於所有HDInsight叢集。 取得結果大約需要 30 秒的時間。 輸出如下所示:
 是快速入門。“ border=”true“::
是快速入門。“ border=”true“::
每次您在 Jupyter 中執行查詢時,網頁瀏覽器視窗標題都會顯示 [忙碌] 狀態以及筆記本標題。 您也會在右上角的 PySpark 文字旁看到一個實心圓。
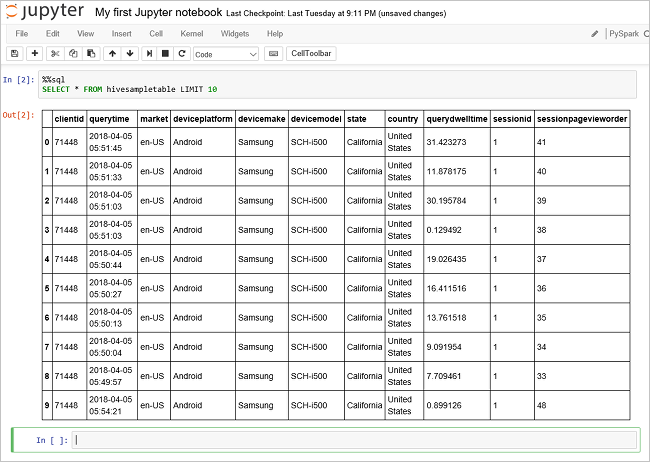
執行另一個查詢以查看 中的數據 hivesampletable。
%%sql
SELECT * FROM hivesampletable LIMIT 10
畫面應該重新整理以顯示查詢輸出。
 Insight“ border=”true“:::
Insight“ border=”true“:::
從筆記本上的 [ 檔案 ] 功能表中,選取 [關閉] 和 [ 停止]。 關閉筆記本會釋放叢集資源。
HDInsight 會將您的資料儲存在 Azure 儲存體 或 Azure Data Lake 儲存體 中,因此您可以在未使用叢集時安全地刪除叢集。 您也需支付 HDInsight 叢集的費用 (即使未使用該叢集)。 由於叢集費用是儲存體費用的許多倍,所以刪除未使用的叢集符合經濟效益。 如果您打算立即處理後續步驟中列出的教學課程,您可能會想要保留叢集。
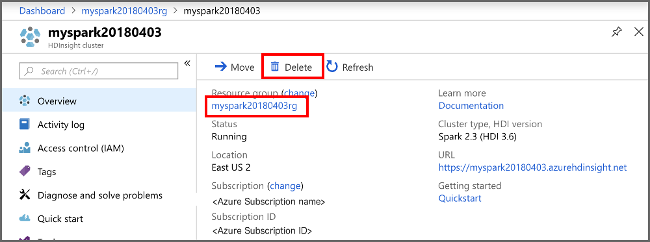
切換回 Azure 入口網站,然後選取 [刪除]。
 sight cluster“ border=”true“:::
sight cluster“ border=”true“:::
您也可以選取資源群組名稱來開啟資源群組頁面,然後選取 [刪除資源群組]。 刪除資源群組時,會同時刪除 HDInsight 叢集及預設儲存體帳戶。
在本快速入門中,您已瞭解如何在 HDInsight 中建立 Apache Spark 叢集,並執行基本的 Spark SQL 查詢。 前進到下一個教學課程,瞭解如何使用 HDInsight 叢集在範例數據上執行互動式查詢。
訓練
認證
Microsoft Certified: Azure Data Engineer Associate - Certifications
展現對常見資料工程工作的了解,以使用多種 Azure 服務在 Microsoft Azure 上實作和管理資料工程工作負載。
文件
教學課程:使用 Apache Spark 來載入資料和執行查詢 - Azure HDInsight
教學課程 - 了解如何在 Azure HDInsight 中的 Spark 叢集上載入資料和執行互動式查詢。
使用 Hadoop、Spark 和 Kafka 在 HDInsight 中設定叢集
從瀏覽器、Azure 傳統 CLI、Azure PowerShell、REST 或 SDK 為 HDInsight 設定 Hadoop、Kafka、Spark 或 HBase 叢集。
在 Azure HDInsight 中,開始建立叢集之前要考慮幾點。