使用元件搭配 Azure Machine Learning 工作室來建立和執行機器學習管線

在本文中,您將了解如何使用 Azure Machine Learning 工作室和元件來建立及執行機器學習管線。 您可以不使用元件來建立管線,但元件提供更好的彈性和重複使用量。 Azure Machine Learning 管線可在 YAML 中進行定義並從 CLI 執行、以 Python 撰寫,或使用拖放 UI 在 Azure Machine Learning 工作室設計工具中撰寫。 本文件著重於 Azure Machine Learning 工作室設計工具 UI。
必要條件
如果您沒有 Azure 訂用帳戶,請在開始前建立免費帳戶。 試用免費或付費版本的 Azure Machine Learning。
Azure Machine Learning 工作區建立工作區資源。
複製範例存放庫:
git clone https://github.com/Azure/azureml-examples --depth 1 cd azureml-examples/cli/jobs/pipelines-with-components/
注意
設計工具支援兩種類型的元件:傳統預先建置的元件 (v1) 和自訂元件 (v2)。 這兩種類型的元件互不相容。
傳統預先建置元件主要提供用於資料處理和傳統機器學習工作 (例如迴歸和分類) 的預先建置元件。 傳統預建元件會繼續受到支援,但不會新增任何新的元件。 此外,傳統預建 (v1) 元件部署不支援受控的在線端點 (v2)。
自訂元件可讓您包裝自己的程式碼作為元件。 支援跨工作區共用元件,及跨工作室、CLI v2 和 SDK v2 介面的無縫製作。
對於新專案,我們強烈建議您使用與 AzureML V2 相容的自訂元件,並且會持續接收新的更新。
本文適用於自訂元件。
在您的工作區中註冊元件
若要在 UI 中使用元件建置管線,您必須首先將元件註冊到工作區。 您可以使用 UI、CLI 或 SDK 將元件註冊至工作區,以便可以共用和重複使用工作區內的元件。 註冊的元件支援自動版本設定,因此您可以更新元件,但請確保需要較舊版本的管線仍能繼續運作。
下列範例會使用 UI 來註冊元件,元件來源檔案是在azureml-examples存放庫的 cli/jobs/pipelines-with-components/basics/1b_e2e_registered_components 目錄中。 您必須先將存放庫複製到本機。
- 在 Azure Machine Learning 工作區中,瀏覽至 [元件] 頁面,然後選取 [新增元件] (兩個樣式頁面其中之一隨即出現)。


這個範例會在目錄中使用 train.yml。 YAML 檔案會定義名稱、類型、介面,包括此元件的輸入和輸出、程式碼、環境和命令。 此元件 train.py 的程式碼位於 ./train_src 資料夾底下,其描述此元件的執行邏輯。 若要深入了解元件結構描述,請參閱命令元件 YAML 結構描述參考。
注意
在 UI 中註冊元件時,元件 YAML 檔案中定義的 code 只能指向 YAML 檔案找到或子資料夾的目前資料夾,這表示您無法將 ../ 指定給 code,因為 UI 無法辨識父代目錄。
additional_includes 只能指向目前或子資料夾。
目前,UI 僅支援以 command 類型註冊元件。
- 從 [資料夾] 選取 [上傳],然後選取要上傳的
1b_e2e_registered_components資料夾。 從下拉式清單中選取train.yml。

選取底部的 [下一步],您可以確認此元件的詳細資料。 確認之後,請選取 [建立] 以完成註冊程序。
重複上述步驟,使用
score.yml和eval.yml註冊 Score 和 Eval 元件。在成功註冊三個元件之後,您可以在工作室 UI 中看到您的元件。
![螢幕擷取畫面顯示 [元件] 頁面中的已註冊元件。](media/how-to-create-component-pipelines-ui/component-page.png?view=azureml-api-2#lightbox)
使用已註冊的元件建立管線
在設計工具中建立新的管線。 請記得選取 [自訂] 選項。
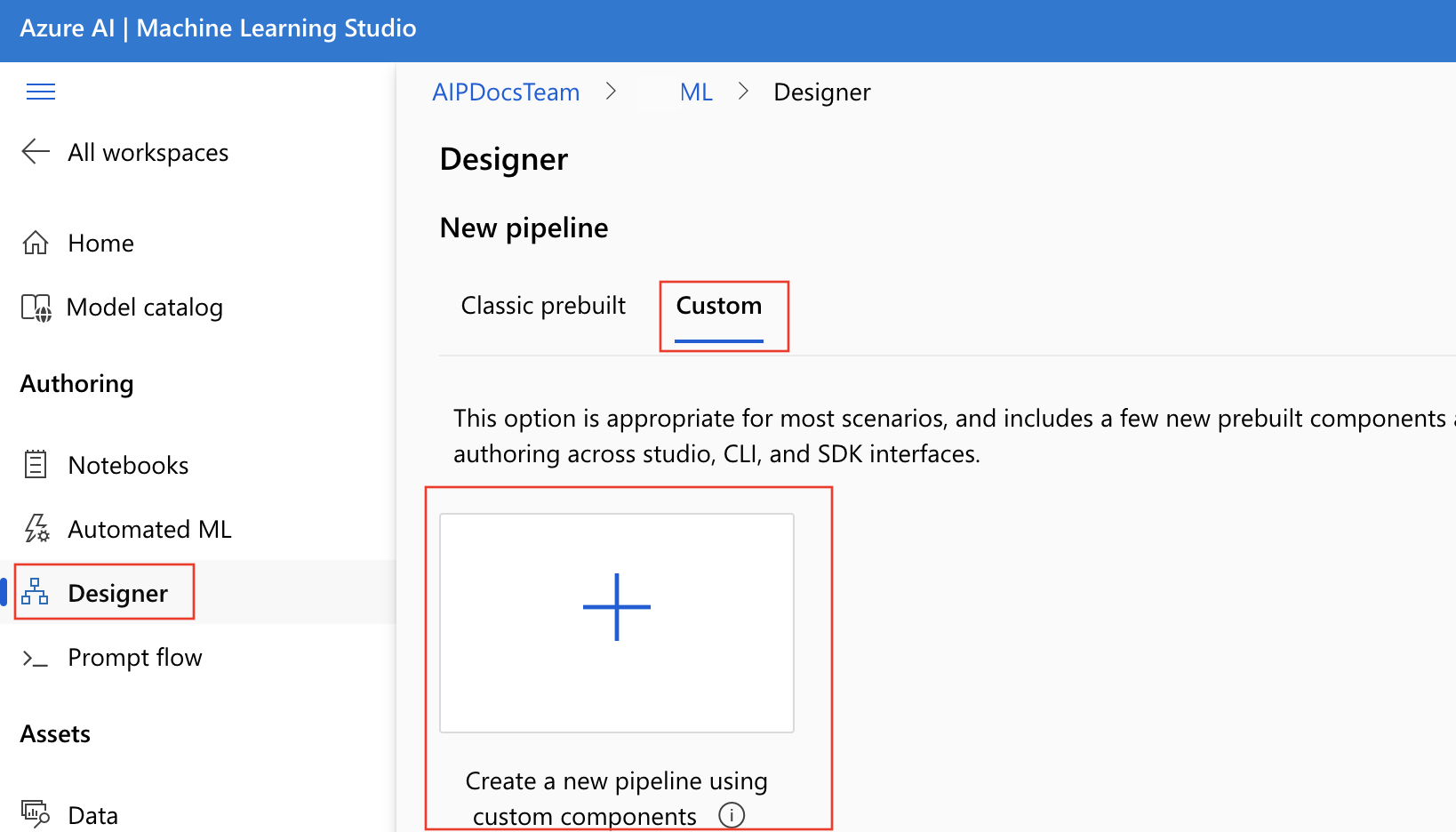
選取自動產生名稱旁的鉛筆圖示,為管線指定有意義的名稱。
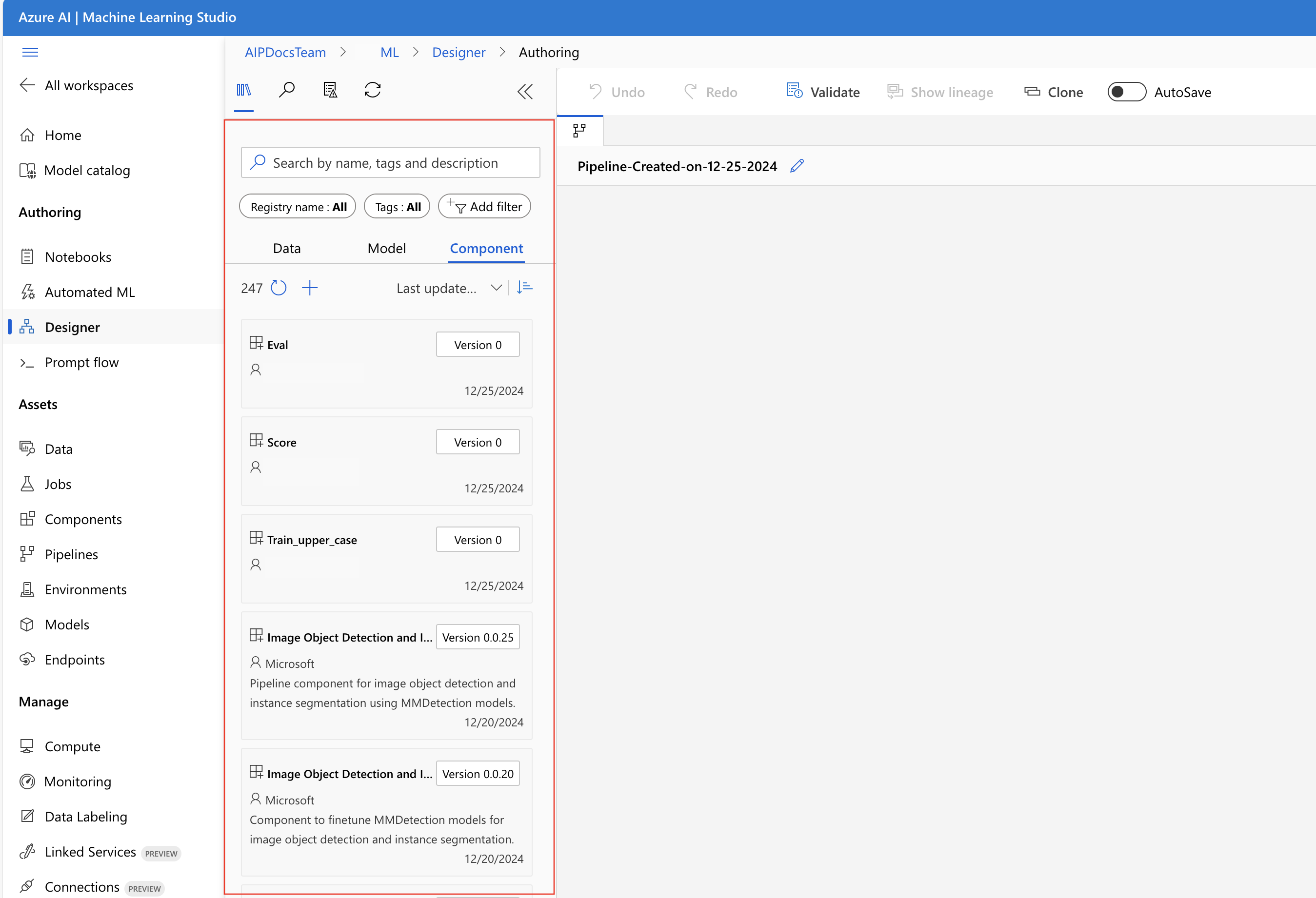
在設計工具資產庫中,您可以看到 [資料]、[模型] 和 [元件] 索引標籤。 切換至 [元件] 索引標籤,您可以看到上一節註冊的元件。 如果元件太多,您可以使用元件名稱進行搜尋。
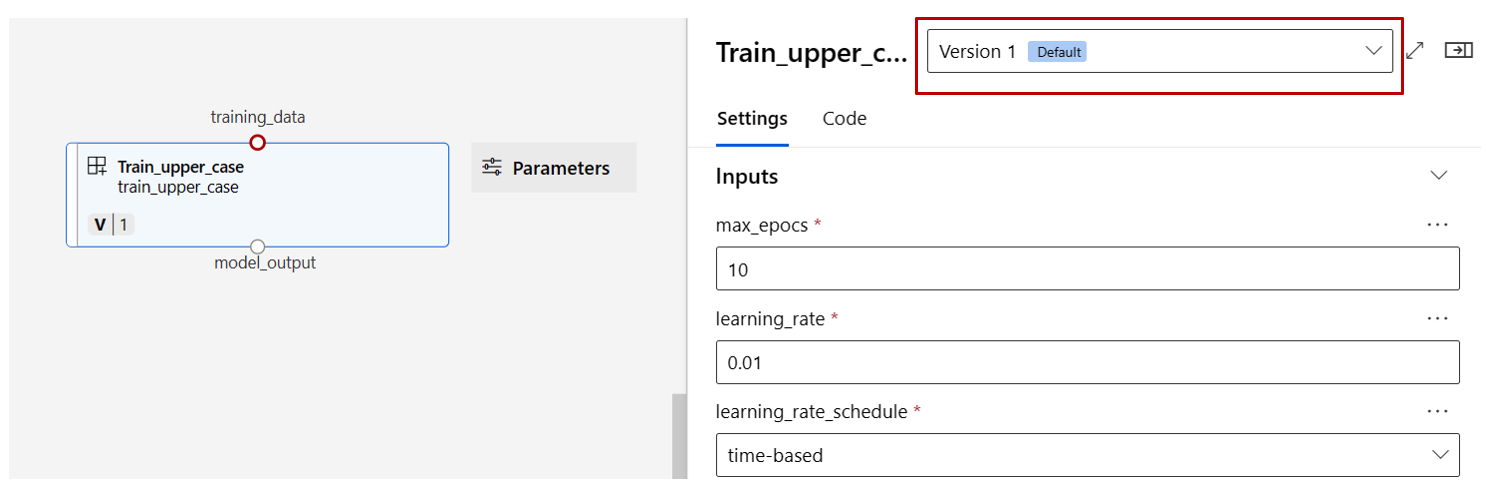
尋找在上一節中註冊的 train、score 和 eval 元件,然後拖放到畫布上。 根據預設,其會使用元件的預設版本,而且您可以在元件右窗格中將其變更為特定版本。 按兩下元件,即可叫用元件右窗格。
在此範例中,我們將會使用此路徑底下的範例資料。 選取設計工具資產庫中的新增圖示 -> 資料索引標籤、設定 Type = Folder(uri_folder),然後遵循精靈以註冊資料,將資料註冊到工作區。 資料類型必須是 uri_folder,才能與定型元件定義一致。

然後將資料拖放到畫布中。 現在您的管線外觀應該如以下的螢幕擷取畫面所示。

藉由在畫布中拖曳連線來連線資料和元件。
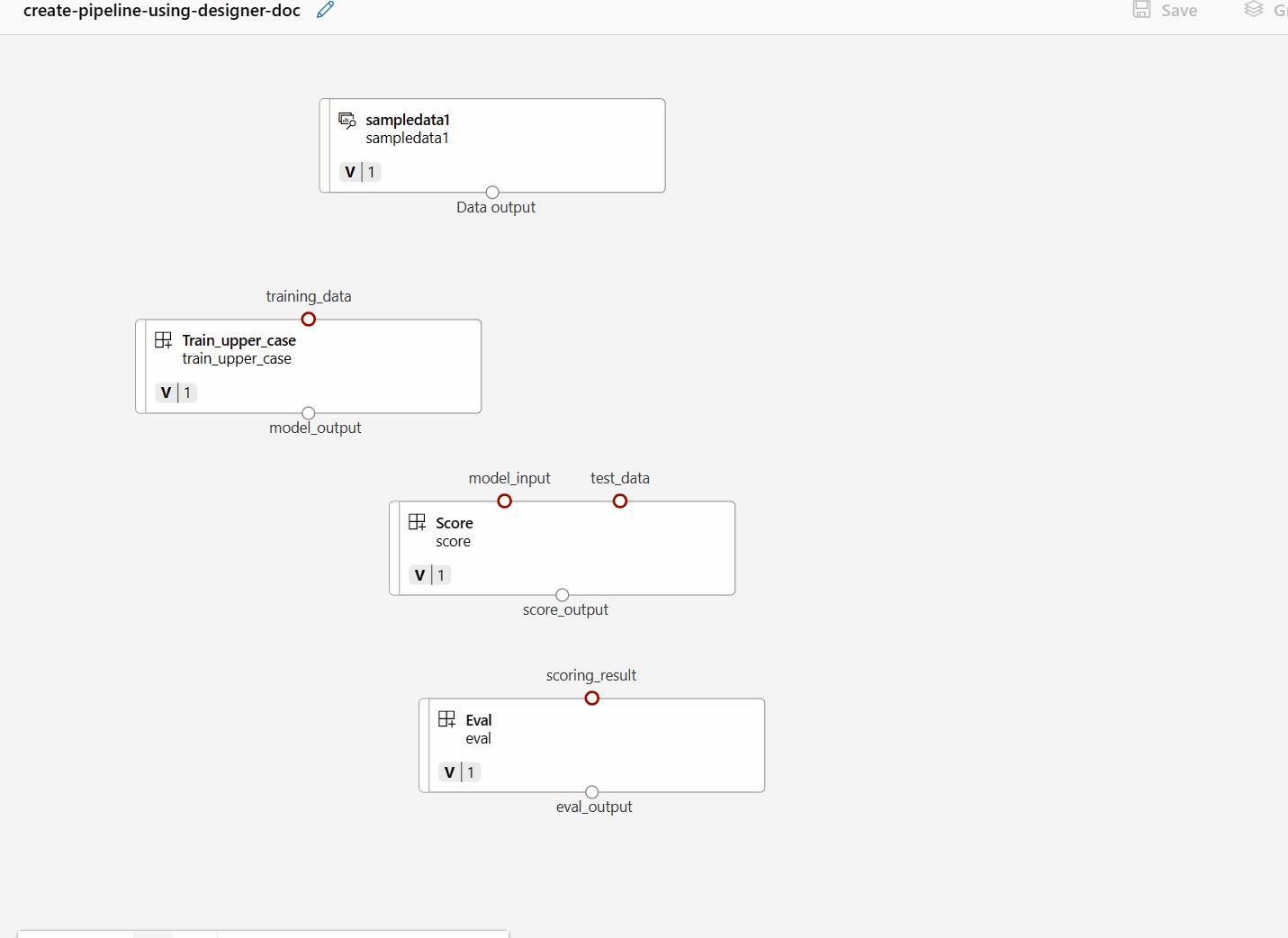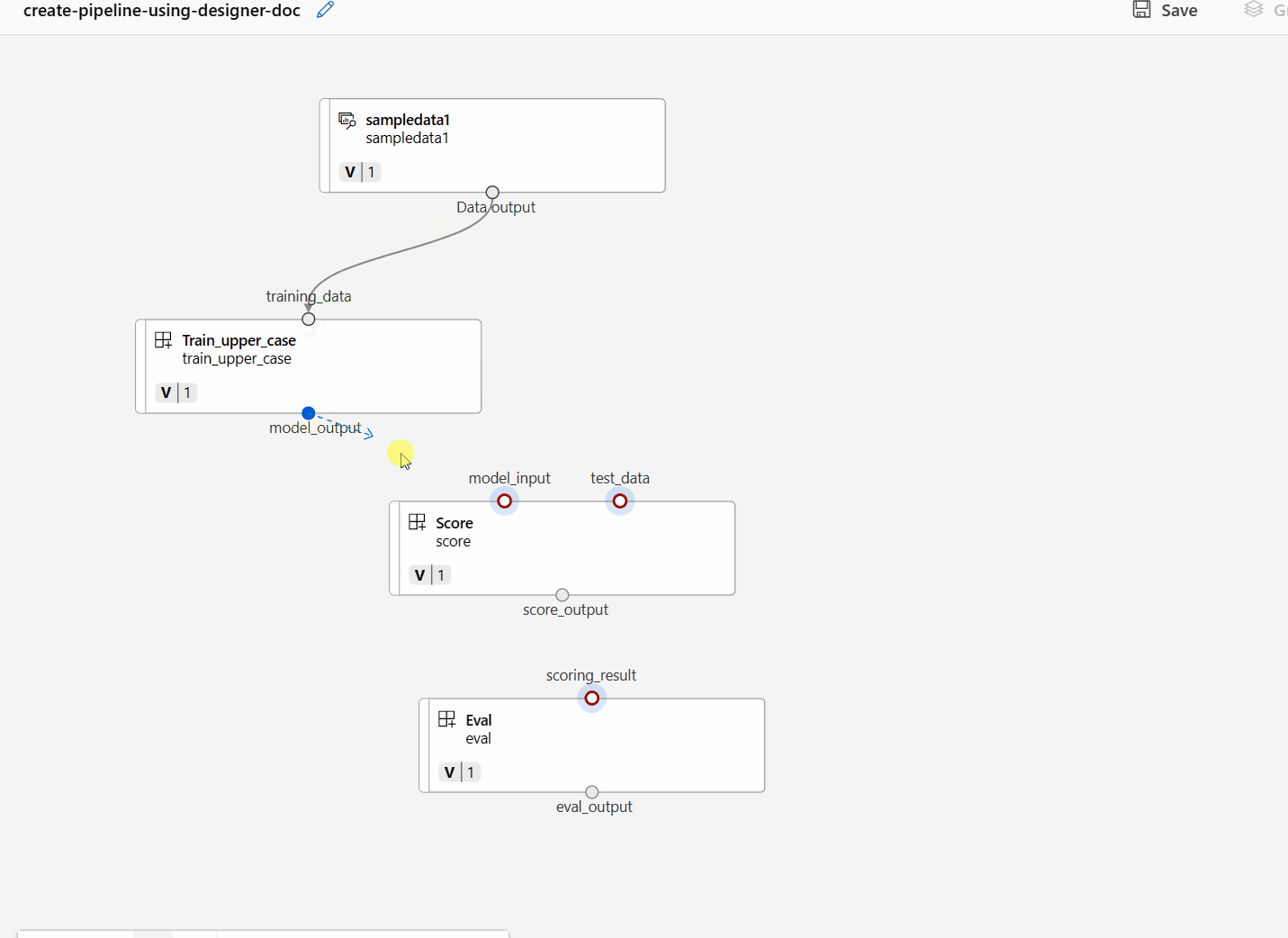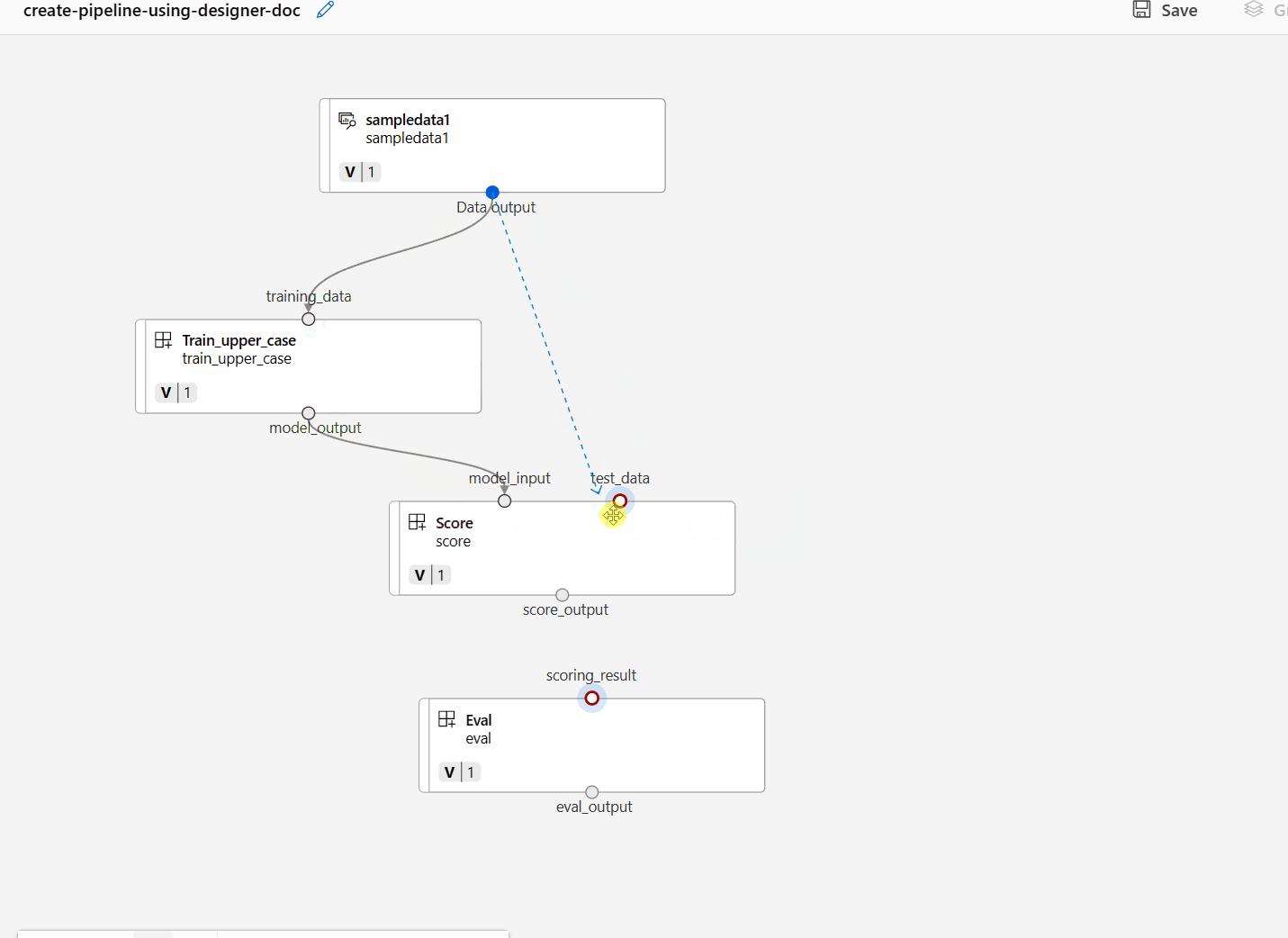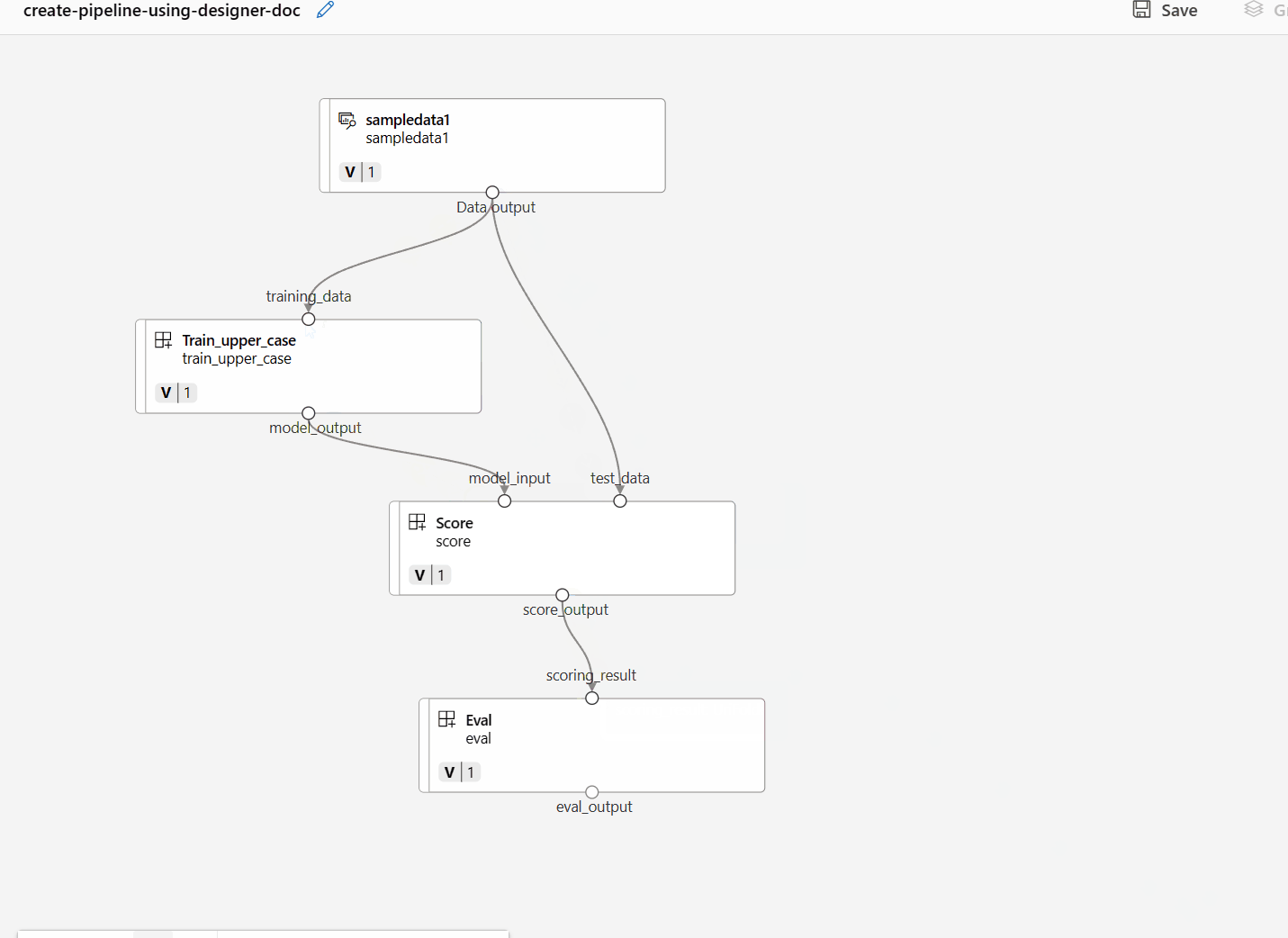
按兩下一個元件,您會看到可在其中設定元件的右窗格。
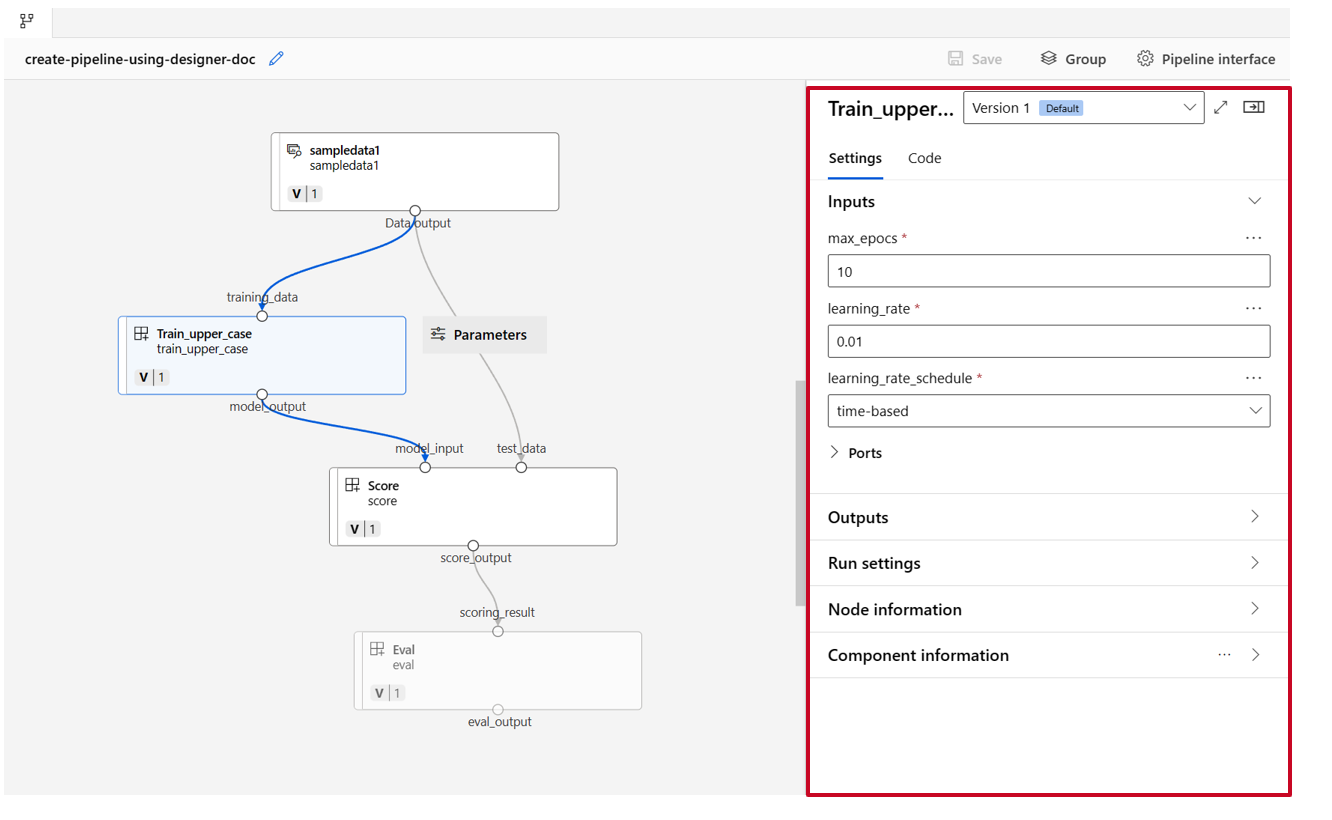
對於具有基本類型輸入 (例如數字、整數、字串和布林值) 的元件,您可以在 [輸入] 區段底下的元件詳細窗格中變更這類輸入的值。
您也可以在右窗格中變更輸出設定 (儲存元件輸出的位置) 和執行設定 (要執行此元件的計算目標)。
現在讓我們將 train 元件的 max_epocs 輸入升階為管線層級輸入。 如此一來,您就可以在提交管線之前,每次將不同的值指派給這個輸入。
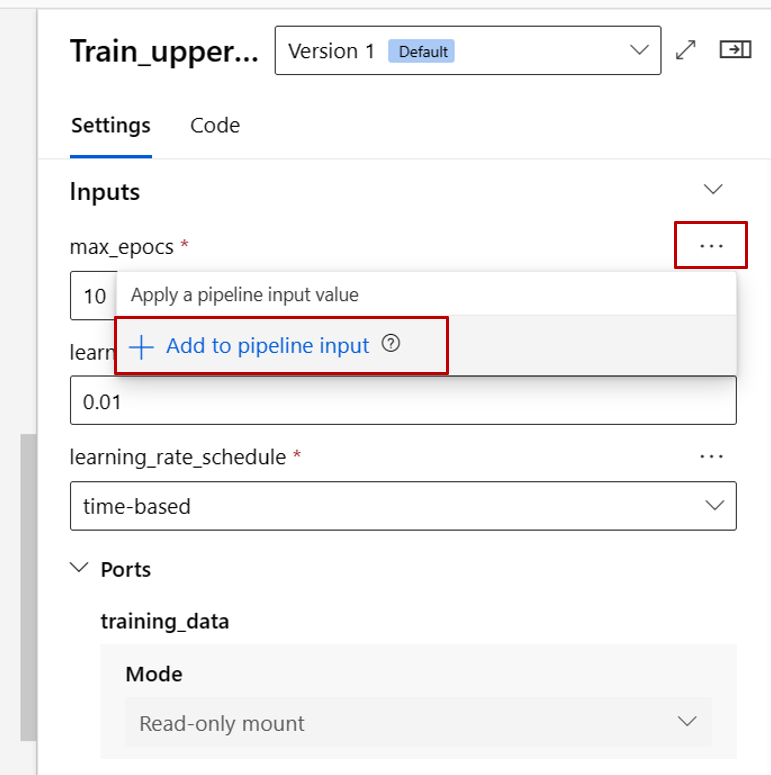









注意
自訂元件和設計工具傳統預先建置元件無法一起使用。
提交管線
選取右上角的 [設定與提交] 以提交管線。
![顯示 [設定] 和 [提交] 按鈕的螢幕擷取畫面。](media/how-to-create-component-pipelines-ui/configure-submit.png?view=azureml-api-2)
接著您會看到逐步精靈,請遵循精靈來提交管線作業。

在 [基本] 步驟中,您可以設定實驗、作業顯示名稱、作業描述等。
在 [輸入與輸出] 步驟中,您可以設定升階為管線層級的輸入/輸出。 在上一個步驟中,我們已將 train 元件的 max_epocs 升階為管線輸入,因此您應該可以在此處看到值並將其指派至 max_epocs。
在 [執行階段設定] 中,您可以設定管線的預設資料存放區和預設計算。 這是管線中所有元件的預設資料存放區/計算。 但是請注意,如果您明確為元件設定不同的計算或資料存放區,則系統會遵守元件層級設定。 否則,會使用管線預設值。
[檢閱 + 提交] 步驟是提交之前檢閱所有設定的最後一個步驟。 如果您曾經提交管線,精靈會記住您上次的設定。
提交管線作業之後,頂端會有一則訊息,其中包含作業詳細資料的連結。 您可以選取此連結來檢閱作業詳細資料。

在管線作業中指定身分識別
提交管線作業時,您可以指定身分識別來存取 Run settings 下的資料。 預設身分識別是 AMLToken,這表示不使用任何身分識別,同時我們支援 UserIdentity 和 Managed。 針對 UserIdentity,作業提交者的身分識別是用來存取輸入資料,並將結果寫入輸出資料夾。 如果您指定 Managed,系統將會使用受控識別來存取輸入資料,並將結果寫入輸出資料夾。

下一步
- 使用 GitHub 上的這些 Jupyter Notebook 來進一步探索機器學習管線
- 了解如何使用 CLI 第 2 版來使用元件建立管線。
- 了解如何使用 SDK v2 利用元件來建立管線