快速入門:使用 Azure Databricks 部署受控 Apache Spark 叢集
Azure Managed Instance for Apache Cassandra 可為受控開放原始碼 Apache Cassandra 資料中心提供自動化部署與規模調整作業。 這項功能可以加快混合式案例的執行並減少常態維護需求。
本快速入門示範如何使用 Azure 入口網站,在 Azure Managed Instance for Apache Cassandra 叢集的 Azure 虛擬網路內建立完全受控的 Apache Spark 叢集。 您可以在 Azure Databricks 中建立 Spark 叢集。 稍後,您可建立筆記本或將其附加至叢集、從不同的資料來源讀取資料,以及分析深入解析。
您還可以深入了解如何在 Azure 虛擬網路中部署 Azure Databricks (虛擬網路插入) 的詳細指示。
必要條件
如果您沒有 Azure 訂用帳戶,請在開始前建立免費帳戶。
建立 Azure Databricks 叢集
請遵循下列步驟,在具有 Azure Managed Instance for Apache Cassandra 的虛擬網路中建立 Azure Databricks 叢集:
登入 Azure 入口網站。
在左側功能窗格中,找到 [資源群組]。 瀏覽至受控執行個體部署所在虛擬網路隸屬的資源群組。
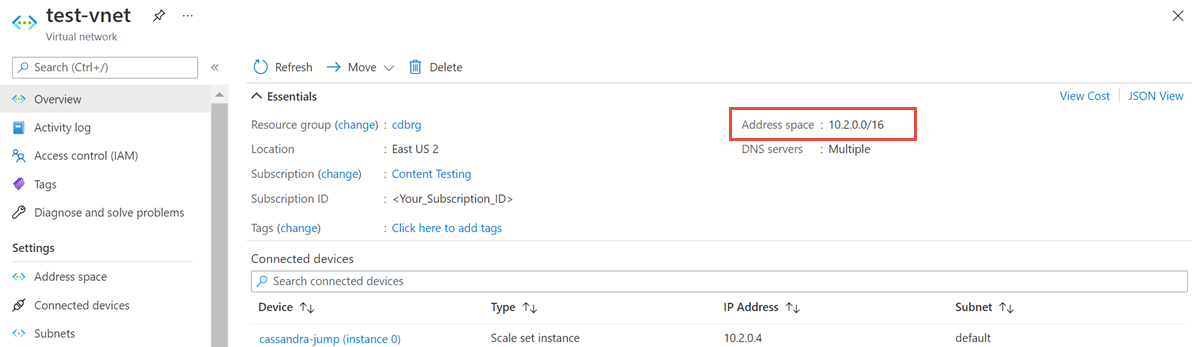
開啟 [虛擬網路] 資源,並記下 [位址空間]:
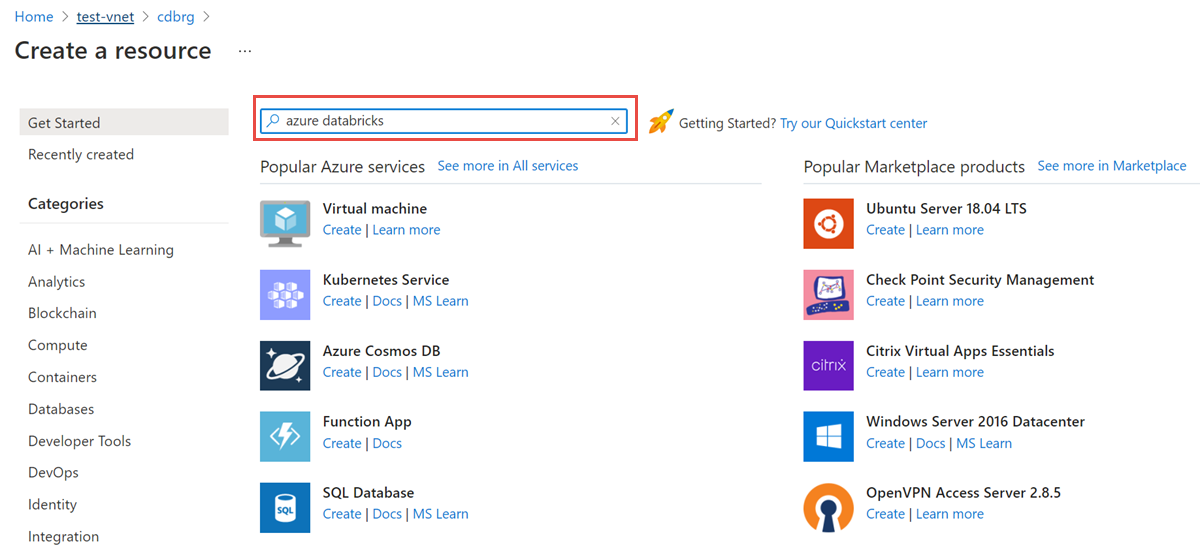
從資源群組中選取 [新增],並在搜尋欄位中搜尋 Azure Databricks:
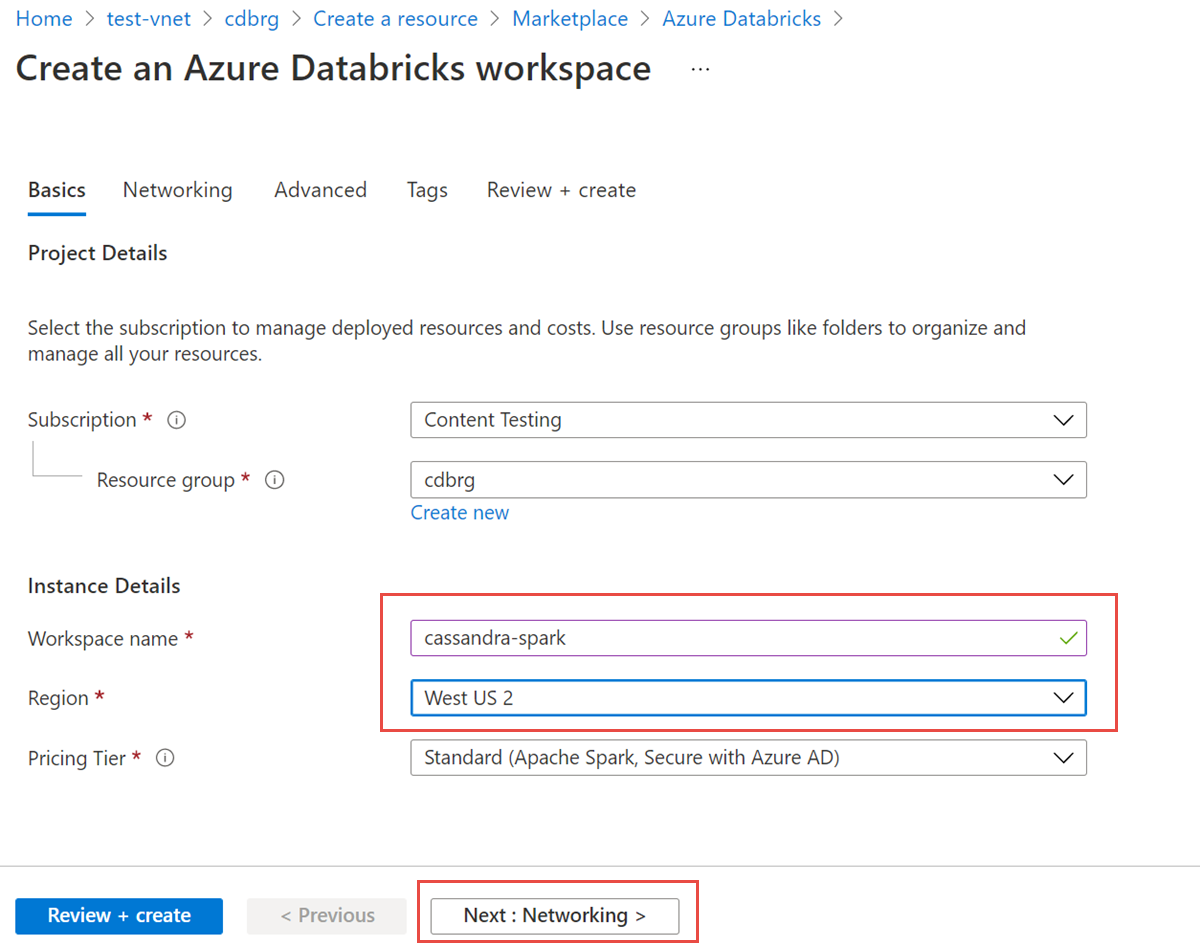
選取 [建立] 以建立 Azure Databricks 帳戶:
![此螢幕快照顯示已選取 [建立] 按鈕的 Azure Databricks 供應專案。](media/deploy-cluster-databricks/databricks-create.png)
輸入下列值:
- [工作區名稱]:提供您 Databricks 工作區的名稱。
- [區域]:請務必選取與您虛擬網路相同的區域。
- [定價層]:選擇 [標準]、[進階] 或 [試用]。 如需這些定價層的詳細資訊,請參閱 Databricks 定價頁面。
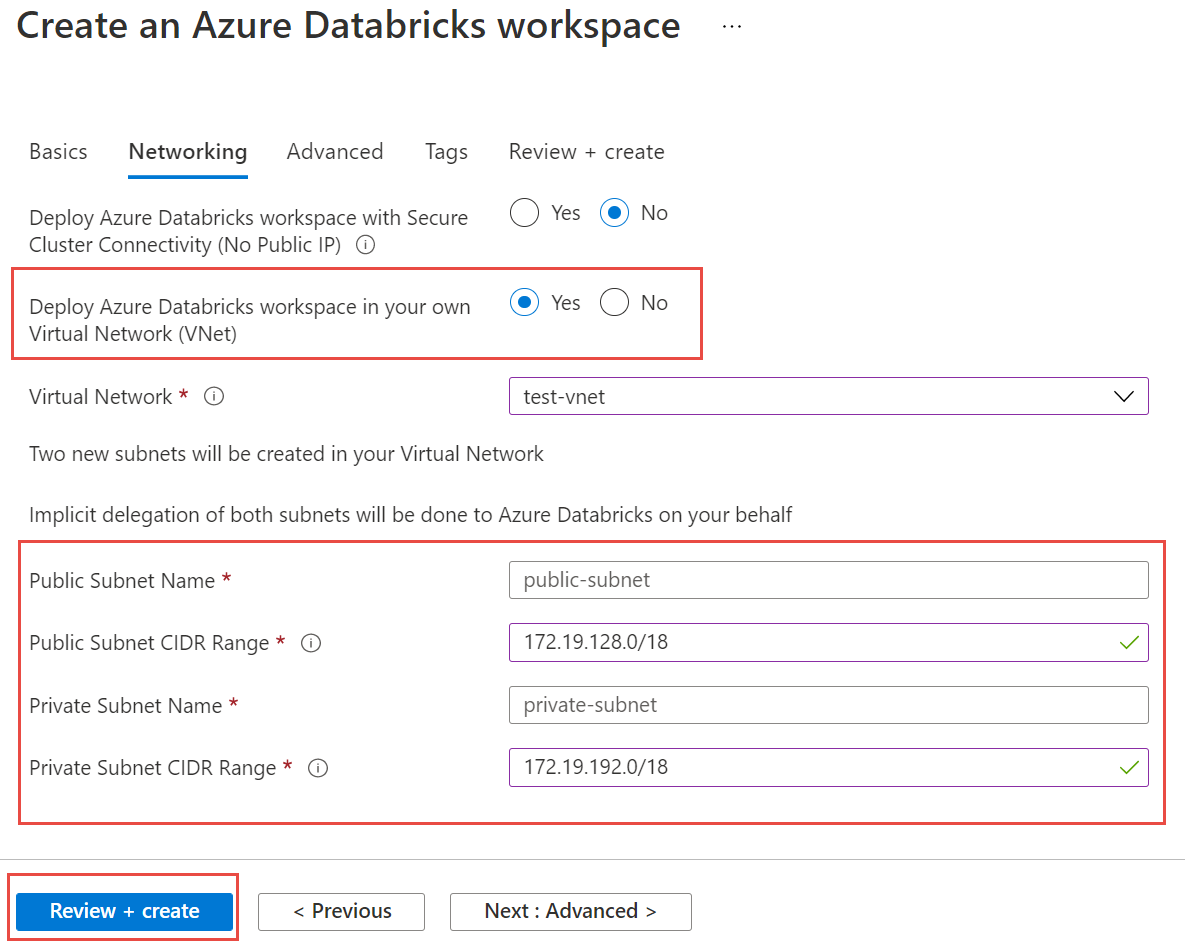
接下來,選取 [網路] 索引標籤,然後輸入下列詳細資料:
- [在虛擬網路 (VNet) 中部署 Azure Databricks 工作區]:選取 [是]。
- [虛擬網路]:從下拉式清單中,選擇受控執行個體所在的虛擬網路。
- [公用子網路名稱]:輸入公用子網路的名稱。
- [公用子網路 CIDR 範圍]:輸入公用子網路的 IP 範圍。
- [私人子網路名稱]:輸入私人子網路的名稱。
- [私人子網路 CIDR 範圍]:輸入私人子網路的 IP 範圍。
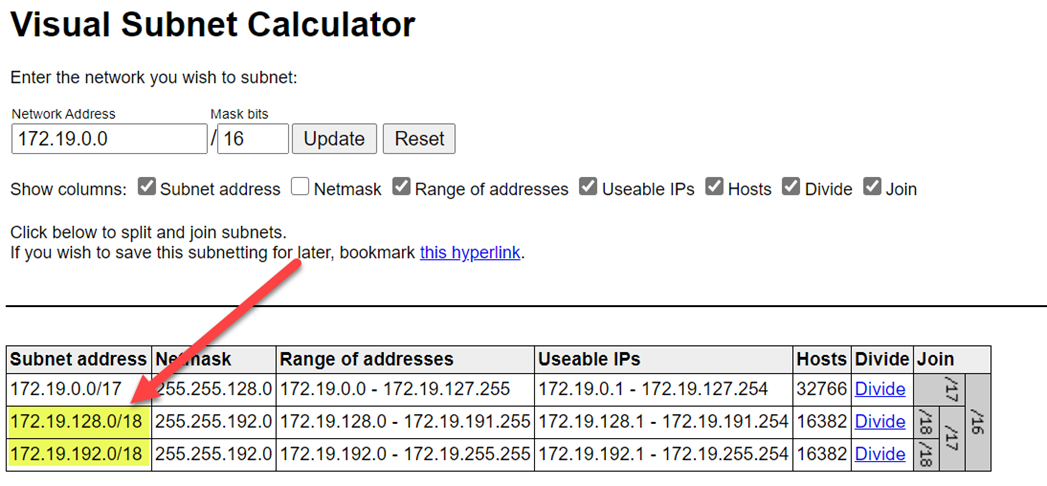
若要避免範圍衝突,請確定您選取了較高的範圍。 如有必要,請使用視覺化子網路計算機來分割範圍:
下列螢幕擷取畫面顯示網路窗格中的範例詳細資料:
選取 [檢閱並建立],然後選取 [建立] 以部署工作區。
建立工作區之後啟動工作區。
系統會將您重新導向至 Azure Databricks 入口網站。 在入口網站中,選取 [新增叢集]。
在 [新增叢集] 窗格中,對於下列欄位以外的所有欄位,請接受預設值:
- [叢集名稱]:輸入叢集的名稱。
- [Databricks Runtime 版本]:建議選取 Databricks Runtime 7.5 版或更高版本,以支援 Spark 3.x。
![此螢幕快照顯示 [新增叢集] 對話框,並已選取 Databricks 運行時間版本。](../reusable-content/ce-skilling/azure/media/cosmos-db/databricks-runtime.png)
展開 [進階選項],然後新增下列組態。 請務必取代節點 IP 和認證:
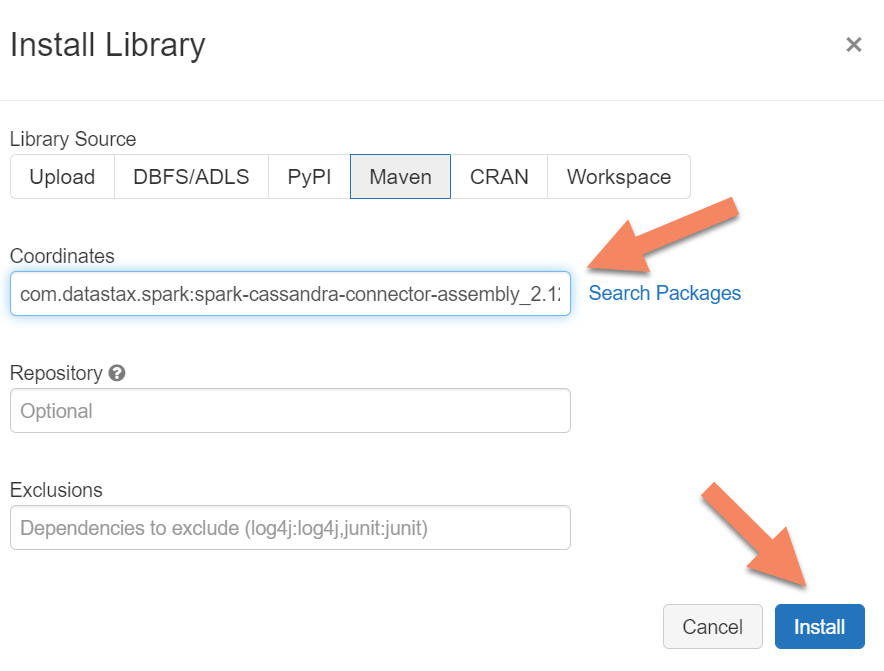
spark.cassandra.connection.host <node1 IP>,<node 2 IP>, <node IP> spark.cassandra.auth.password cassandra spark.cassandra.connection.port 9042 spark.cassandra.auth.username cassandra spark.cassandra.connection.ssl.enabled true將 Apache Spark Cassandra 連接器程式庫新增至您的叢集,以連線至原生和 Azure Cosmos DB Cassandra 端點。 在您的叢集中,選取 [程式庫] > [安裝新的] > [Maven],然後在 Maven 座標中新增
com.datastax.spark:spark-cassandra-connector-assembly_2.12:3.0.0。
清除資源
如果您不打算繼續使用這個受控執行個體叢集,請使用下列步驟將其刪除:
- 從 Azure 入口網站的左側功能表中,選取 [資源群組]。
- 在該清單中,選取您在本快速入門中建立的資源群組。
- 在資源群組 [概觀] 窗格中,選取 [刪除資源群組]。
- 在下個視窗中輸入要刪除的資源群組名稱,然後選取 [刪除]。
下一步
在本快速入門中,您已了解如何在 Azure Managed Instance for Apache Cassandra 叢集的 Azure 虛擬網路內建立完全受控的 Apache Spark 叢集。 接下來,您可以了解如何管理叢集和資料中心資源: