Azure 流量管理員中的可靠性
本文包含跨區域災害復原和 Azure 流量管理員 商務持續性支援。
跨區域災害復原和商務持續性
災害復原 (DR)是指從重大影響事件中復原,例如自然災害或不成功的部署 (導致停機和資料遺失)。 無論原因為何,解決災害的最佳辦法是定義完善且經過測試的 DR 方案,以及主動支援 DR 的應用程式設計。 開始思考建立災害復原方案之前,請參閱設計災害復原策略的建議。
Microsoft 在災害復原方面採取共同責任模型。 在共同責任模型中,Microsoft 確保基準基礎結構和平台服務可供使用。 此時,許多 Azure 服務不會自動複寫資料,或從失敗區域回復為交叉複寫到另一個已啟用的區域。 您需要為這些服務制定適合工作負載的災害復原方案。 在 Azure 平台即服務 (PaaS) 供應項目上執行的多數服務,都有提供支援災害復原的功能和指導,您可以使用特定服務功能快速復原,制定災害復原方案。
Azure 流量管理員是 DNS 型的流量負載平衡器,可讓您跨全球 Azure 區域將流量發散到公開應用程式。 流量管理員也可讓您的公用端點維持高可用性和快速回應性。
流量管理員會使用 DNS,根據流量路由方法,將用戶端要求導向適當的服務端點。 流量管理員也監視每個端點的健康情況。 端點可以是裝載於 Azure 內部或外部的任何面向網際網路服務。 流量管理員提供流量路由方法和端點監視選項的範圍,以符合不同的應用程式需求和自動容錯移轉模型。 流量管理員可彈性應變失敗,包括整個 Azure 區域的失敗。
多區域地理位置的災害復原
DNS 是轉移網路流量的其中一個最有效率的機制。 DNS 會有效率是因為 DNS 通常是全球性的,且在資料中心外部。 DNS 也會與任何區域層級或可用性區域 (AZ) 層級的失敗隔絕開來。
設定災害復原架構涉及到兩個技術層面:
使用部署機制在主要和待命環境之間複寫執行個體、資料和組態。 這種類型的災害復原可以透過 Azure Site Recovery 原生方式完成,請參閱透過 Microsoft Azure 合作夥伴設備/服務,例如 Veritas 或 NetApp 的 Azure Site Recovery 文件。
開發解決方案來將網路/ Web 流量從主要站台轉移至待命站台。 此類災害復原可以透過 Azure DNS、Azure 流量管理員 (DNS) 或第三方全域負載平衡器來完成。
本文特別著重於 Azure 流量管理員的災害復原規劃。
中斷偵測、通知和管理
發生損毀時,系統會探查主要端點,而狀態會變更為降級,然後災害復原站台會保持連線。 根據預設,流量管理員會將所有流量傳送至主要 (優先順序最高) 端點。 如果主要端點出現降級,流量管理員會將流量路由至第二個端點,前提是第二個端點的狀況良好。 您可以在流量管理員中設定多個端點,讓這些端點可做為額外的容錯移轉端點,或是做為可分擔各端點負載的負載平衡器。
設定災害復原和中斷偵測
如果您有複雜的架構和能夠執行相同函式的多組資源,您可以設定 Azure 流量管理員 (以 DNS 為基礎) 來檢查您的資源健康情況,並將流量從狀況不好的資源路由到狀況良好的資源。
在下列範例中,主要區域和次要地區都有完整的部署。 此部署包括雲端服務和已同步處理的資料庫。

圖 - 使用 Azure 流量管理員進行自動容錯移轉
不過,只有主要區域會主動處理來自使用者的網路要求。 只有主要區域遇到服務中斷時,次要地區才會變成作用區域。 在此情況下,所有新的網路要求會路由傳送到次要地區。 由於資料庫備份幾乎是瞬間完成、兩個負載平衡器的 IP 狀況都會受到檢查,以及執行個體永遠是啟動且正在執行中,因此此拓撲提供以低 RTO 運作及無須任何手動介入的容錯移轉選項。 次要的容錯移轉區域必須準備好在主要區域失敗後立即開始運作。
此案例非常適合使用 Azure 流量管理員,其內建探查可處理各種類型的健康情況檢查,包括 http / https 和 TCP。 Azure 流量管理員也有規則引擎,可設定為在發生失敗時進行容錯移轉,如下所述。 讓我們使用流量管理員來設想下列解決方案:
- 客戶都有稱為 prod.contoso.com 的區域 #1 端點,且靜態 IP 為 100.168.124.44,以及稱為 dr.contoso.com 的區域 #2 端點,靜態 IP 為 100.168.124.43。
- 這些環境的每一個都透過公眾對應屬性 (例如負載平衡器) 而置於前方。 負載平衡器可以設定為有 DNS 架構的端點或完整網域名稱 (FQDN),如上所示。
- 區域 2 中的所有執行個體幾乎是及時地對區域 1 進行複寫。 此外,機器映像處於最新狀態,而且所有軟體/設定資料皆已修補,並且與區域 1 一致。
- 已預先設定自動調整。
若要使用 Azure 流量管理員來設定容錯移轉:
建立新的 Azure 流量管理員設定檔 使用名稱 contoso123 建立新的 Azure 流量管理員設定檔,並選取 [優先順序] 作為 [路由方式]。 如果您有想與之建立關聯的現有資源群組,則您可以選取現有的資源群組,否則請建立新的資源群組。
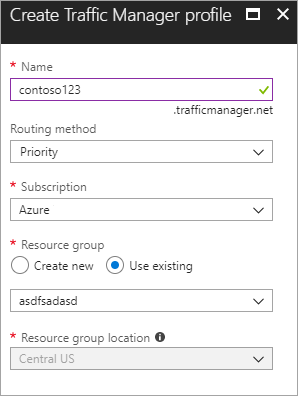
圖 - 建立流量管理員設定檔
在流量管理員設定檔中建立端點
在此步驟中,您會建立指向生產環境和災害復原站台的端點。 在這裡,選擇 [外部端點] 作為 [類型],但如果資源裝載在 Azure 中,則也可以選擇 [Azure 端點]。 如果您選擇 [Azure 端點],則選取 [App Service] 或 Azure 配置的 [公用 IP] 作為 [目標資源]。 優先順序會設為 1,因為其是區域 1 的主要服務。 同樣地,也在流量管理員中建立災害復原端點。

圖 - 建立災害復原端點
設定健康情況檢查和容錯移轉組態
在此步驟中,您會將 DNS TTL 設為 10 秒,這適用於大部分與網際網路對應的遞迴解析程式。 此設定表示沒有 DNS 解析程式可快取資訊超過 10 秒。
針對端點監視設定,路徑目前設定在 / 或根目錄,但是您可以自訂端點設定來評估路徑,例如 prod.contoso.com/index。
下方範例顯示的探查通訊協定是 https。 不過,您也可以選擇 http 或 tcp。 通訊協定的選擇取決於後端應用程式。 探查間隔設定為 10 秒,以便進行快速探查,而重試設定為 3。 如此一來,如果三個連續的間隔顯示為失敗,流量管理員就會容錯移轉至第二個端點。
下列公式會定義自動化故障轉移的總時間:
Time for failover = TTL + Retry * Probing interval在此情況下,值為 10 + 3 * 10 = 40 秒(最大值)。
如果重試設為 1 且 TTL 設定為 10 秒,則容錯移轉時間是 10 + 1 * 10 = 20 秒。
將重試值設為大於 1,可排除因為誤判或網路短暫中斷而造成容錯移轉的機會。

圖 - 設定健康情況檢查和容錯移轉組態
下一步
深入了解 Azure 流量管理員。
深入了解 Azure DNS。