本文描述 Azure 串流分析中的相容性層級選項。
串流分析是受控服務,會定期更新功能和持續改善效能。 服務的大部分執行階段更新都會自動提供給終端使用者,與相容性層級無關。 不過,如果新功能造成現有工作行為變更,或是在執行中工作中取用資料的方式變更,則會在新的相容性層級下引進這項變更。 您可以保留較低的相容性層級設定,讓現有的串流分析工作保持執行中狀態,而未進行主要變更。 當您準備好執行最新執行階段行為時,可以提高相容性層級來加入宣告。
選擇相容性層級
相容性層級可控制串流分析作業的執行階段行為。
Azure 串流分析目前支援三個相容性層級:
- 1.2 - 具有最近改善的最新行為
- 1.1 - 先前的行為
- 1.0 - 數年前,在 Azure 串流分析正式發行期間引進的原始相容性層級。
當您建立新的串流分析工作時,最佳做法是使用最新的相容性層級來建立串流分析工作。 根據最新的行為來開始您的工作設計,以避免日後新增的變更和複雜度。
設定相容性層級
您可以在 Azure 入口網站中或使用建立工作 REST API 呼叫來設定串流分析工作的相容性層級。
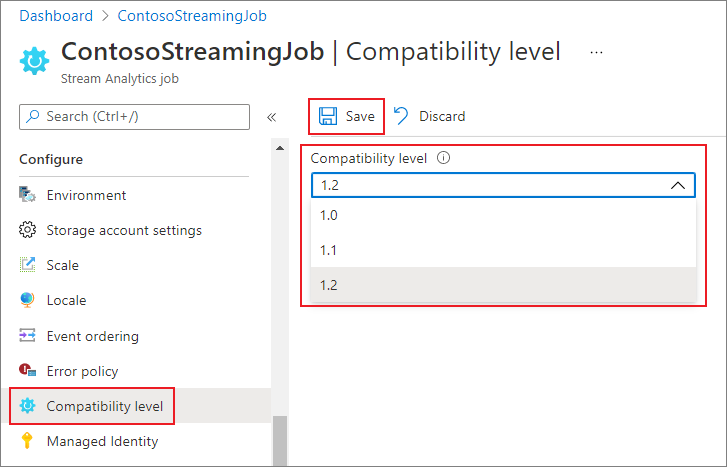
若要更新 Azure 入口網站中工作的相容性層級:
- 使用 Azure 入口網站找到您的串流分析工作。
- 先「停止」工作,再上傳相容性層級。 如果您的工作處於執行中狀態,則無法更新相容性層級。
- 在 [設定] 標題下,選取 [相容性層級]。
- 選擇您想要的相容性層級值。
- 選取頁面底部的 [儲存]。
當您更新相容性層級時,T 編譯器會以對應至所選取相容性層級的語法來驗證工作。
相容性層級 1.2
相容性層級 1.2 中引進下列主要變更:
AMQP 傳訊通訊協定
1.2 層級:Azure 串流分析使用進階訊息佇列通訊協定 (AMQP) 訊息通訊協定來寫入至服務匯流排佇列和主題。 透過開放式標準通訊協定,AMQP 可讓您打造一個跨平台的混合式應用程式。
GeoSpatial 函式
先前的層級:Azure 串流分析已使用地理位置計算。
1.2 層級:Azure 串流分析可讓您計算幾何投影的地理座標。 地理空間函數的簽章未變更。 不過,其語意稍有不同,允許比之前更為精確的計算。
Azure 串流分析支援地理空間參考資料索引。 包含地理空間元素的參考資料可以編制索引,以加快聯結計算的速度。
更新的地理空間函數可完整表達已知文字 (WKT) 地理空間格式。 您可以指定先前未受 GeoJson 支援的其他地理空間元件。
如需詳細資訊,請參閱 Azure 串流分析中地理空間功能的更新 – 雲端和 IoT Edge。
具有多個分割區的輸入的來源平行查詢執行
先前的層級:Azure 串流分析查詢需要使用 PARTITION BY 子句,跨輸入來源分割區來平行處理查詢。
1.2 層級:如果查詢邏輯可以跨輸入來源分割區平行處理,則 Azure 串流分析會建立個別的查詢執行個體,並平行執行計算。
原生大量 API 與 Azure Cosmos DB 輸出整合
先前的層級:upsert 行為是「插入或合併」。
1.2 層級:原生大量 API 與 Azure Cosmos DB 輸出的整合可最大化輸送量,並有效率地處理節流要求。 如需詳細資訊,請參閱 Azure 串流分析輸出至 Azure Cosmos DB 頁面。
upsert 行為是「插入或取代」。
寫入至 SQL 輸出時的 DateTimeOffset
先前層級:DateTimeOffset 類型已調整為UTC。
1.2 層級:不再調整 DateTimeOffset。
寫入至 SQL 輸出的時為 Long
先前的層級:根據目標類型來截斷值。
1.2 層級:根據輸出錯誤原則來處理不符合目標類型的值。
寫入 SQL 輸出時的記錄和陣列序列化
先前的層級:記錄已寫入為 "Record",而陣列會寫入為 "Array"。
1.2 層級:以 JSON 格式序列化記錄和陣列。
嚴格驗證函數前置詞
先前的層級:未嚴格驗證函數前置詞。
1.2 層級:Azure 串流分析具有嚴格的函數前置詞驗證。 將前置詞新增至內建函數會導致錯誤。 例如,不支援 myprefix.ABS(…)。
將前置詞新增至內建彙總也會導致錯誤。 例如,不支援 myprefix.SUM(…)。
針對任何使用者定義的函數使用前置詞 "system" 會導致錯誤。
不允許將 Array 和 Object 作為 Azure Cosmos DB 輸出配接器中的索引鍵屬性
先前的層級:支援 Array 和 Object 類型作為索引鍵屬性。
1.2 層級:不再支援 Array 和 Object 類型作為索引鍵屬性。
以 JSON、AVRO 和 PARQUET 還原序列化布林型別
先前層級:串流分析會將布林值還原序列化為 BIGINT 型別 - false 對應至 0,而 true 對應至 1。 如果您明確將事件轉換成 BIT,輸出只會以 JSON、AVRO 和 PARQUET 建立布林值。
例如,從 input1 讀取 JSON { "value": true } 之類的 SELECT value INTO output1 FROM input1 傳遞查詢會寫入 output1 JSON 值 { "value": 1 }。
1.2 層級:串流分析會將布林值還原序列化為 BIT 型別。 False 對應至 0,而 true 對應至 1。 從 input1 讀取 JSON { "value": true } 之類的 SELECT value INTO output1 FROM input1 傳遞查詢會寫入 output1 JSON 值 { "value": true }。 您可以將值轉換成查詢中的 BIT 型別,以確保它們在支援布林型別的格式輸出中顯示為 true 和 false。
相容性層級 1.1
相容性層級 1.1 中引入了下列重大變更:
服務匯流排 XML 格式
1.0 層級:Azure 串流分析已使用 DataContractSerializer,因此訊息內容包括 XML 標籤。 例如:
@\u0006string\b3http://schemas.microsoft.com/2003/10/Serialization/\u0001{ "SensorId":"1", "Temperature":64\}\u0001
1.1 層級:訊息內容直接包含串流,而沒有其他標籤。 例如:{ "SensorId":"1", "Temperature":64}
欄位名稱保持大小寫區分
1.0 層級:由 Azure 串流分析引擎處理時,欄位名稱已變更為小寫。
1.1 層級:欄位名稱是由 Azure 串流分析引擎所處理時可保持區分大小寫。
注意
使用 Edge 環境所裝載的串流分析作業尚無法使用保持大小寫區分的功能。 因此,如果您的作業裝載在 Edge 上,所有欄位名稱都會轉換為小寫。
FloatNaNDeserializationDisabled
1.0 層級:CREATE TABLE 命令並未在「浮點數 (FLOAT)」資料行型別中篩選具 NaN (不是數字 (Not-a-Number。例如,Infinity, -Infinity) 的事件,因其不符合這些數字的記載範圍。
1.1 層級:CREATE TABLE 可讓您指定強式結構描述。 串流分析引擎會驗證資料是否符合此結構描述。 使用此模型,命令可以篩選具有 NaN 值的事件。
停用在 JSON 輸入時將 datetime 字串自動轉換成 DateTime 類型
1.0 層級:JSON 剖析器會在輸入時將具有日期/時間/區域資訊的字串值自動轉換成 DATETIME 類型,因此值會立即失去其原始格式和時區資訊。 因為這是在輸入時完成,所以即使查詢中未使用該欄位,還是會將其轉換成 UTC DateTime。
1.1 層級:不會將具有日期/時間/區域資訊的字串值自動轉換成 DATETIME 類型。 因此,會保留時區資訊和原始格式。 不過,如果在查詢中使用 NVARCHAR(MAX) 欄位作為 DATETIME 運算式 (例如,DATEADD 函數) 的一部分,則會將其轉換成 DATETIME 類型來執行計算,而且會遺失其原始形式。