移除每個資料表中的重複資料以進行資料統整
統整過程中的重複資料刪除規則步驟會從來源資料表中找到並移除客戶的重複記錄,讓每個客戶都在各個資料表中僅以單一資料列來表示。 每個資料表都使用規則個別刪除重複資料,以識別指定客戶的記錄。
規則會依順序進行處理。 對資料表中所有的記錄執行過所有規則之後,有共同資料列的相符群組會合併成單一相符群組。
定義重復資料刪除規則
良好的規則會找出唯一的客戶。 考慮您的資料。 根據電子郵件等欄位識別客戶可能就已足夠。 不過,如果您想要區分有共同電子郵件的客戶,則可以選擇讓規則使用兩個條件,根據電子郵件 + 名字進行比對。 有關詳細資訊,請參閱 重複數據刪除最佳實踐。
在重複資料刪除規則頁面上,選取資料表,然後選取新增規則來定義重複資料刪除規則。
提示
如果您已在資料來源層級擴充資料表來改善統整結果,請選取頁面上方的使用擴充資料表。 如需詳細資訊,請參閱資料來源擴充。
![重複資料刪除規則頁面的螢幕擷取畫面,其中反白顯示資料表並顯示 [新增規則]](media/m3_duplicates_showmore.png)
在 新增規則 窗格上輸入下列資訊:
選取欄位:對於檢查重複資料的資料表,在其可用的欄位清單中選擇。 選擇對每個客戶很可能是唯一的欄位。 例如,電子郵件地址,或姓名、城市和電話號碼的組合。
歸一化:選擇 列的歸一化選項 。 正規化只會影響比對步驟,而不會變更資料。
- 數位:將表示數位的 Unicode 符號轉換為簡單數位。
- 符號:刪除符號和特殊字元,例如!”#$%&'()*+,-./:;<=>?@[]^_'{|}~. 例如,Head&Shoulder 變成 HeadShoulder。
- 文字轉換為小寫:將大寫字元轉換為小寫。 "ALL CAPS and Title Case" 變成 "all caps and title case"。
- 類型(電話、姓名、位址、組織):標準化姓名、職務、電話號碼和位址。
- Unicode 轉 ASCII:將 Unicode 字元轉換為等效的 ASCII 字母。 例如,重音 ề 轉換為 e 字元。
- 空白字元:刪除所有空白。 Hello World變成HelloWorld。
- 別名對應:允許您上傳字串對的自定義清單,以指示應始終被視為完全匹配的字串。
- 自定義繞過:允許您上傳自定義字串清單,以指示不應匹配的字串。
精確度:設定精確程度。 精度用於精確匹配和模糊匹配,並確定兩個字元串需要有多接近才能被視為匹配。
- 基本:從低 (30%)、中 (60%)、高 (80%)與完全相符 (100%)進行選擇。 選取全字詞,只比對 100% 相符的記錄。
- 自訂:設定記錄需要相符的百分比。 系統只會讓超過此閾值的記錄比對相符。
名稱:規則的名稱。
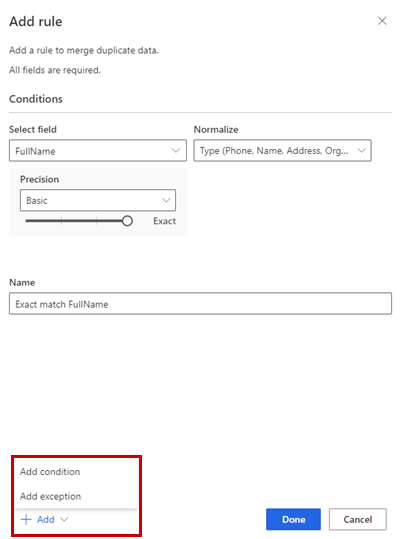
或者,選取新增>新增條件,將更多條件新增至規則。 條件以邏輯運算子 AND 相連接,只有在滿足所有條件的情況下才會執行。
或者,新增>新增例外, 將例外新增至規則。 例外是用來處理誤判和漏判的少數案例。
選取完成以建立規則。
或者,新增更多規則。
選取資料表,然後選取編輯合併喜好設定。
在合併喜好設定窗格中:
選擇三個選項之一,以決定發現重複資料時要保留的記錄:
- 填滿最多:找出包含最多已填入資料行的記錄做為入選記錄。 這是預設合併選項。
- 最新:根據最新情況找出贏家記錄。 需要日期或數字欄位來定義最新。
- 時間最接近:以新近度最接近的,找出入選方記錄。 需要日期或數字欄位來定義新近度。
如果出現平局,則入選記錄會是具有 MAX(PK) 或較大主索引鍵值的那一個。
或者,若要在資料表的個別資料行上定義合併喜好設定,請選取窗格底部的進階。 例如,您可以選擇保留最近的電子郵件,「及」來自不同記錄的最完整地址。 展開資料表以查看其所有資料行,並定義要用於個別資料行的選項。 如果您選擇基於新近度的選項,也需要指定定義新近度的日期/時間欄位。
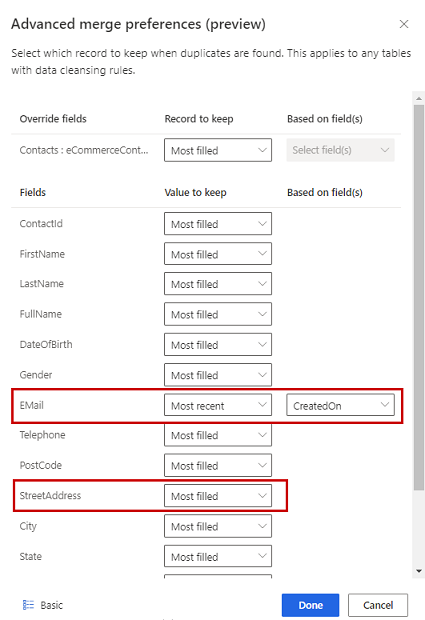
選取完成套用合併喜好設定。
定義重複資料刪除規則和合併喜好設定之後,請選取下一步。
![重複資料刪除規則頁面的螢幕擷取畫面,其中反白顯示資料表並顯示 [新增規則]](media/m3_duplicates_showmore.png#lightbox)