TripPin 第 5 部分 - 分頁
此多部分教學課程涵蓋如何建立Power Query的新數據源延伸模組。 本教學課程旨在循序完成,每個課程都是以先前課程中建立的連接器為基礎,以累加方式將新功能新增至您的連接器。
在本課程中,您將會:
- 將分頁支援新增至連接器
許多 Rest API 會傳回「頁面」中的數據,要求用戶端提出多個要求,以將結果合併在一起。 雖然分頁有一些常見的慣例(例如 RFC 5988),但一般會因 API 到 API 而有所不同。 值得慶幸的是,TripPin 是 OData 服務,而 OData 標準 會使用 響應主體中傳回的 odata.nextLink 值來定義分頁的方式。
為了簡化 連接器先前的反覆專案 ,函 TripPin.Feed 式無法 感知頁面。 它只會剖析從要求傳回的任何 JSON,並將其格式化為數據表。 熟悉 OData 通訊協定的人可能注意到,回應格式有許多不正確的假設(例如假設有包含value記錄數位的欄位)。
在這一課,您會藉由讓回應處理邏輯頁面感知來改善回應處理邏輯。 未來的教學課程可讓頁面處理邏輯更健全且能夠處理多個回應格式(包括來自服務的錯誤)。
注意
您不需要使用以 OData.Feed 為基礎的連接器實作自己的分頁邏輯,因為它會自動為您處理所有分頁邏輯。
分頁檢查清單
實作分頁支援時,您必須瞭解 API 的下列事項:
- 如何要求下一頁的數據?
- 分頁機制是否涉及計算值,還是從回應中擷取下一頁的 URL?
- 如何知道何時停止分頁?
- 您是否應該注意與分頁相關的參數? (例如「頁面大小」)
這些問題的解答會影響您實作分頁邏輯的方式。 雖然分頁實作有一些程式碼重複使用(例如使用 Table.GenerateByPage,但大部分連接器最終都需要自定義邏輯。
注意
本課程包含 OData 服務的分頁邏輯,其遵循特定格式。 請檢查 API 的檔,以判斷連接器中需要進行的變更,以支援其分頁格式。
OData 分頁概觀
OData 分頁是由響應承載中包含的 nextLink 批注所驅動。 nextLink 值包含下一頁數據的 URL。 您會知道回應中尋找最外層物件中的欄位,是否有另一頁 odata.nextLink 的數據。 odata.nextLink如果沒有欄位,您已讀取所有資料。
{
"odata.context": "...",
"odata.count": 37,
"value": [
{ },
{ },
{ }
],
"odata.nextLink": "...?$skiptoken=342r89"
}
某些 OData 服務可讓用戶端提供 頁面大小上限喜好設定,但不論是否接受,服務都由服務決定。 Power Query 應該能夠處理任何大小的回應,因此您不需要擔心指定頁面大小喜好設定,您可以支援任何服務在您擲回的任何服務。
如需伺服器驅動分頁的詳細資訊,請參閱 OData 規格。
測試 TripPin
修正分頁實作之前,請先確認上一個教學課程中延伸模組的目前行為。 下列測試查詢會擷取 人員 數據表,並新增索引數據行以顯示您目前的數據列計數。
let
source = TripPin.Contents(),
data = source{[Name="People"]}[Data],
withRowCount = Table.AddIndexColumn(data, "Index")
in
withRowCount
開啟 Fiddler,並在 Power Query SDK 中執行查詢。 請注意,查詢會傳回包含八個數據列的數據表(索引 0 到 7)。
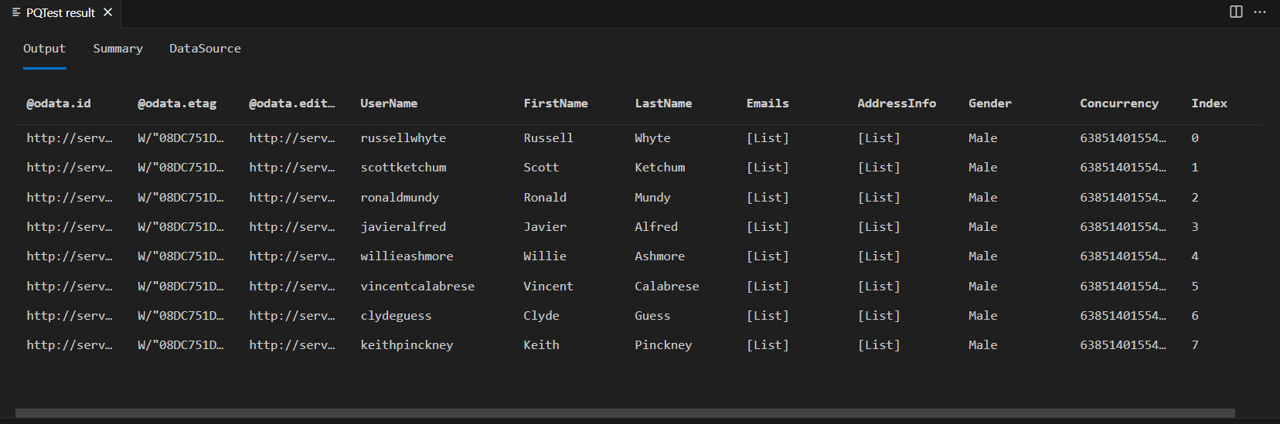
如果您查看 fiddler 回應的本文,您會看到它實際上包含欄位 @odata.nextLink ,指出有更多可用的數據頁面。
{
"@odata.context": "https://services.odata.org/V4/TripPinService/$metadata#People",
"@odata.nextLink": "https://services.odata.org/v4/TripPinService/People?%24skiptoken=8",
"value": [
{ },
{ },
{ }
]
}
實作 TripPin 的分頁
您現在將會對延伸模組進行下列變更:
- 匯入通用
Table.GenerateByPage函式 - 新增用來
Table.GenerateByPage將所有頁面黏附在一GetAllPagesByNextLink起的函式 GetPage新增可讀取單一數據頁的函式- 新增函式以從回應擷取下一個
GetNextLinkURL - 更新
TripPin.Feed以使用新的頁面讀取器函式
注意
如本教學課程稍早所述,分頁邏輯在數據源之間會有所不同。 這裡的實作會嘗試將邏輯分成應該可重複使用的函式,以供使用 回應中傳回下一個連結 的來源使用。
Table.GenerateByPage
若要將來源傳回的多個頁面合併成單一資料表,我們將使用 Table.GenerateByPage。 此函式會採用其自變數, getNextPage 該函式應該只執行其名稱建議的動作:擷取下一頁的數據。 Table.GenerateByPage 會重複呼叫 函 getNextPage 式,每次傳遞結果時產生上次呼叫的結果,直到傳回 null 訊號,表示沒有更多頁面可供使用。
由於此函式不是 Power Query 標準連結庫的一部分,因此您必須將其 原始程式碼 複製到 .pq 檔案。
實作 GetAllPagesByNextLink
函式的GetAllPagesByNextLink主體會實作 的getNextPageTable.GenerateByPage函式自變數。 它會呼叫 函GetPage式,並從上一個呼叫中記錄的meta欄位擷取下一頁數據的 NextLink URL。
// Read all pages of data.
// After every page, we check the "NextLink" record on the metadata of the previous request.
// Table.GenerateByPage will keep asking for more pages until we return null.
GetAllPagesByNextLink = (url as text) as table =>
Table.GenerateByPage((previous) =>
let
// if previous is null, then this is our first page of data
nextLink = if (previous = null) then url else Value.Metadata(previous)[NextLink]?,
// if NextLink was set to null by the previous call, we know we have no more data
page = if (nextLink <> null) then GetPage(nextLink) else null
in
page
);
實作 GetPage
您的 GetPage 函式會使用 Web.Contents 從 TripPin 服務擷取單一頁面的數據,並將響應轉換成數據表。 它會將 Web.Contents 的響應傳遞至 GetNextLink 函式,以擷取下一頁的 URL,並將它設定在 meta 傳回數據表的記錄上(數據頁面)。
此實作是先前教學課程中稍加修改的呼叫版本 TripPin.Feed 。
GetPage = (url as text) as table =>
let
response = Web.Contents(url, [ Headers = DefaultRequestHeaders ]),
body = Json.Document(response),
nextLink = GetNextLink(body),
data = Table.FromRecords(body[value])
in
data meta [NextLink = nextLink];
實作 GetNextLink
您的 GetNextLink 函式只會檢查欄位回應 @odata.nextLink 的主體,並傳回其值。
// In this implementation, 'response' will be the parsed body of the response after the call to Json.Document.
// Look for the '@odata.nextLink' field and simply return null if it doesn't exist.
GetNextLink = (response) as nullable text => Record.FieldOrDefault(response, "@odata.nextLink");
融會貫通
實作分頁邏輯的最後一個步驟是更新 TripPin.Feed 以使用新的函式。 現在,您只要透過呼叫 , GetAllPagesByNextLink但在後續的教學課程中,您將新增新功能(例如強制執行架構和查詢參數邏輯)。
TripPin.Feed = (url as text) as table => GetAllPagesByNextLink(url);
如果您從教學課程稍早重新執行相同的 測試查詢 ,您現在應該會看到頁面閱讀程序運作。 您也應該看到回應中有 24 個數據列,而不是 8 個數據列。
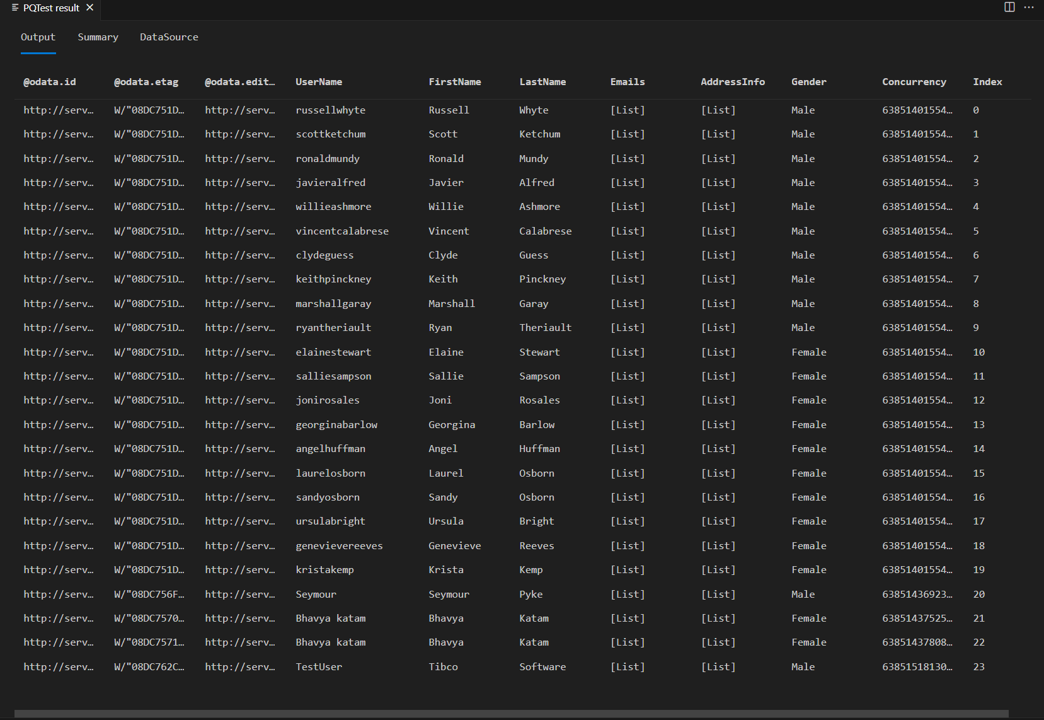
如果您查看 fiddler 中的要求,則現在應該會看到每個數據頁面的個別要求。
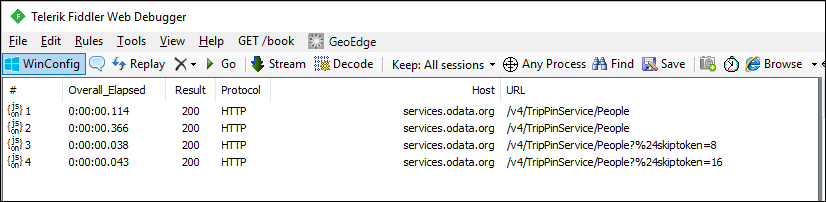
注意
您會注意到服務中第一頁數據的重複要求,這不理想。 額外的要求是 M 引擎架構檢查行為的結果。 暫時忽略此問題,並在下一個教學課程中加以解決,您將在其中套用明確的架構。
結論
本課程說明如何實作 Rest API 的分頁支援。 雖然邏輯在 API 之間可能會有所不同,但此處建立的模式應該可重複使用,並稍微修改。
在下一課,您將探討如何將明確架構套用至您的數據,超越您從 Json.Document取得的簡單text和number數據類型。
下一步
意見反映
即將推出:我們會在 2024 年淘汰 GitHub 問題,並以全新的意見反應系統取代並作為內容意見反應的渠道。 如需更多資訊,請參閱:https://aka.ms/ContentUserFeedback。
提交及檢視以下的意見反映: