SQL Server 巨量資料叢集中的應用程式部署簡介
適用於:![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
重要
Microsoft SQL Server 2019 巨量資料叢集附加元件將會淘汰。 SQL Server 2019 巨量資料叢集的支援將於 2025 年 2 月 28 日結束。 平台上將完全支援含軟體保證 SQL Server 2019 的所有現有使用者,而且軟體將會持續透過 SQL Server 累積更新來維護,直到該時間為止。 如需詳細資訊,請參閱公告部落格文章與 Microsoft SQL Server 平台上的巨量資料選項。
應用程式部署提供了建立、管理和執行應用程式的介面,以在 SQL Server 巨量資料叢集上部署應用程式。 在巨量資料叢集上部署的應用程式可受益於叢集的計算能力,且可以存取叢集上可用的資料。 這會增加應用程式的延展性和效能,同時管理資料所在的應用程式。 SQL Server 巨量資料叢集上支援的應用程式執行階段為 R、Python、dtexec 與 MLeap。
下列各節描述應用程式部署的架構和功能。
應用程式部署架構
應用程式部署是由控制器和應用程式執行階段處理常式所組成。 建立應用程式時,會提供規格檔案 (spec.yaml)。 此 spec.yaml 檔案包含控制器為了成功部署應用程式所需知道的所有內容。 下列是 spec.yaml 內容的範例:
#spec.yaml
name: add-app #name of your python script
version: v1 #version of the app
runtime: Python #the language this app uses (R or Python)
src: ./add.py #full path to the location of the app
entrypoint: add #the function that will be called upon execution
replicas: 1 #number of replicas needed
poolsize: 1 #the pool size that you need your app to scale
inputs: #input parameters that the app expects and the type
x: int
y: int
output: #output parameter the app expects and the type
result: int
控制器會檢查 spec.yaml 檔案中指定的 runtime,並呼叫對應的執行階段處理常式。 執行階段處理常式會建立應用程式。 首先,會建立包含一或多個 Pod 的 Kubernetes 複本集,其中每個 Pod 都包含要部署的應用程式。 Pod 數目是由應用程式 spec.yaml 檔案中設定的 replicas 參數所定義。 每個 Pod 都可以具有一個以上的集區。 集區數目是由 spec.yaml 檔案中設定的 poolsize 參數所定義。
這些設定會決定部署可以平行處理的要求數目。 一個特定時間的要求數目上限等於 replicas 乘上 poolsize。 如果您有 5 個複本,每個複本有 2 個集區,則部署可以平行處理 10 個要求。 下圖為 replicas 和 poolsize 的圖形表示:
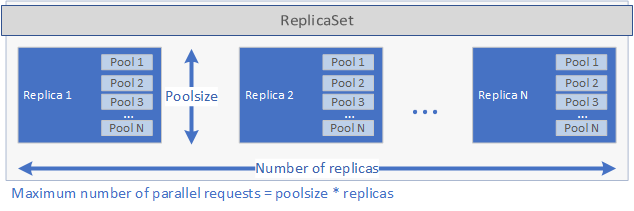
建立複本集並啟動 Pod 之後,即會建立 cron 作業 (如果已在 spec.yaml 檔案中設定 schedule )。 最後,會建立可用於管理與執行應用程式的 Kubernetes 服務 (請參閱下方)。
執行應用程式時,應用程式的 Kubernetes 服務會將要求傳送給複本並傳回結果。
OpenShift 上應用程式部署的安全性考量
SQL Server 2019 CU5 可支援 Red Hat OpenShift 上 BDC 部署,以及 BDC 的已更新安全性模型,因此不再需要特殊權限容器。 對於使用 SQL Server 2019 CU5 的所有新部署,除了沒有特殊權限以外,容器預設還會以非根使用者的身分執行。
在 CU5 版本中,使用應用程式部署介面部署的應用程式安裝步驟,執行身分仍然必須是「根」使用者。 這是必要項目,因為在安裝期間,系統會安裝應用程式將使用的額外套件。 部署為應用程式一部分的其他使用者程式碼,將會以低權限使用者的身分執行。
此外,CAP_AUDIT_WRITE 功能是允許使用 Cron 作業為 SQL Server Integration Services (SSIS) 應用程式排程所需的選擇性功能。 當應用程式的 YAML 規格檔案指定排程時,會透過 Cron 作業觸發應用程式,這需要額外的功能。 或者,您可以視需要透過 Web 服務呼叫來使用 azdata app run 觸發應用程式,這不需要 CAP_AUDIT_WRITE 功能。 請注意,從 SQL Server 2019 CU8 版本開始,cronjob 不再需要 CAP_AUDIT_WRITE 功能。
注意
OpenShift 部署一文中的自訂 SCC 不包含此功能,因為 BDC 的預設部署不需要該功能。 若要啟用此功能,必須先更新自訂 SCC YAML 檔案,才能包含 CAP_AUDIT_WRITE。
...
allowedCapabilities:
- SETUID
- SETGID
- CHOWN
- SYS_PTRACE
- AUDIT_WRITE
...
如何在巨量資料叢集內使用應用程式部署
應用程式部署的兩個主要介面為:
您也可以使用 RESTful Web 服務來執行應用程式。 如需詳細資訊,請參閱取用巨量資料叢集上的應用程式。
應用程式部署案例
應用程式部署可提供建立、管理和執行應用程式的介面,以在 SQL Server BDC 上部署應用程式。
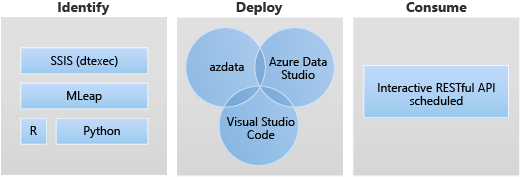
以下是應用程式部署的目標案例:
- 在巨量資料叢集內部署 Python 或 R Web 服務,以解決各種使用案例,例如機器學習推斷、API 服務等。
- 使用 MLeap 引擎建立機器學習推斷端點。
- 使用 dtexec 公用程式從 DTSX 檔案排程和執行套件,以進行資料轉換和移動。
使用應用程式部署 Python 執行階段
在應用程式部署中,BDC Python 執行階段可讓巨量資料叢集內的 Python 應用程式解決各種使用案例,例如機器學習推斷、API 服務等等。
應用程式部署 Python 執行階段會在 SQL Server 巨量資料叢集 CU10+ 上使用 Python 3.8。
在應用程式部署中,您可以在 spec.yaml 提供控制器需要知道才能部署應用程式的資訊。 以下是可以指定的欄位:
name:應用程式名稱version:例如,應用程式版本,如v1runtime:應用程式部署執行階段,您必須將其指定為:Pythonsrc:Python 應用程式的路徑entry point:src 指令碼中,要為此 Python 應用程式執行的進入點函式。
除了上述欄位之外,您還需要指定 Python 應用程式的輸入和輸出。 這會產生 spec.yaml 檔案,類似如下:
#spec.yaml
name: add-app
version: v1
runtime: Python
src: ./add.py
entrypoint: add
replicas: 1
poolsize: 1
inputs:
x: int
y: int
output:
result: int
您可以建立部署在巨量資料叢集上執行的 Python 應用程式所需的基本資料夾和檔案結構:
azdata app init --template python --name hello-py --version v1
如需後續步驟,請參閱如何在 SQL Server 巨量資料叢集上部署應用程式。
應用程式部署 Python 執行階段的限制
應用程式部署 Python 執行階段不支援排程案例。 部署 Python 應用程式並在 BDC 中執行之後,RESTful 端點會設定為接聽連入要求。
使用應用程式部署 R 執行階段
在應用程式部署中,BDC Python 執行階段可讓巨量資料叢集內的 R 應用程式解決各種使用案例,例如機器學習推斷、API 服務等等。
應用程式部署 R 執行階段會在 SQL Server 巨量資料叢集 CU10+ 上使用 Microsoft R Open (MRO) 3.5.2 版。
使用方式
在應用程式部署中,您可以在 spec.yaml 提供控制器需要知道才能部署應用程式的資訊。 以下是可以指定的欄位:
name:應用程式名稱version:例如,應用程式版本,如v1runtime:應用程式部署執行階段,您必須將其指定為:Rsrc:R 應用程式的路徑entry point:執行此 R 應用程式的進入點
除了上述欄位之外,您還需要指定 R 應用程式的輸入和輸出。 這會產生 spec.yaml 檔案,類似如下:
#spec.yaml
name: roll-dice
version: v1
runtime: R
src: ./roll-dice.R
entrypoint: rollEm
replicas: 1
poolsize: 1
inputs:
x: integer
output:
result: data.fram
您可以使用下列命令來建立部署新 R 應用程式所需的基本資料夾和檔案結構:
azdata app init --template r --name hello-r --version v1
如需後續步驟,請參閱如何在 SQL Server 巨量資料叢集上部署應用程式。
R 執行階段的限制
這些限制與 2023 年 7 月 1 日淘汰的 Microsoft R 應用程式網路一致。 如需詳細資訊和因應措施,請參閱<Microsoft R 應用程式網路淘汰>。
使用應用程式部署 dtexec 執行階段
在應用程式部署中,巨量資料叢集執行階段整合的 dtexec 公用程式來自 Linux 上的 SSIS (mssql-server-is)。 應用程式部署會使用 dtexec 公用程式從 *.dtsx 檔案載入套件。 其支援透過 Web 服務要求,以 cron 樣式排程或隨選方式執行 SSIS 套件。
此功能使用 Linux 上 SQL Server 2019 Integration Service 中的 /opt/ssis/bin/dtexec /FILE。 其支援 Linux 上的 SQL Server 2019 Integration Service (mssql-server-is 15.0.2) 的 dtsx 格式。 若要深入了解 dtexec 公用程式,請參閱 dtexec 公用程式。
在應用程式部署中,您可以在 spec.yaml 提供控制器需要知道才能部署應用程式的資訊。 以下是可以指定的欄位:
name:應用程式nameversion:例如,應用程式版本,如v1runtime:應用程式部署執行階段,若要執行 dtexec 公用程式,您必須將其指定為:SSISentrypoint:指定進入點,這在我們的案例中通常是您的 .dtsx 檔案。options:指定/opt/ssis/bin/dtexec /FILE的其他選項,例如,若要使用連接字串連線到資料庫,其會遵循下列模式:/REP V /CONN "sqldatabasename"\;"\"Data Source=xx;User ID=xx;Password=xx\""如需語法的詳細資訊,請參閱 dtexec 公用程式。
schedule:指定作業需要執行的頻率,例如,使用 cron 運算式指定此值會指定為 "*/1 * * * *",這表示工作是以分鐘為基礎執行的。
您可以使用下列命令來建立部署新 SSIS 應用程式所需的基本資料夾和檔案結構:
azdata app init --name hello-is –version v1 --template ssis
這會產生 spec.yaml 檔案,類似如下:
#spec.yaml
entrypoint: ./hello.dtsx
name: hello-is
options: /REP V
poolsize: 2
replicas: 2
runtime: SSIS
schedule: '*/2 * * * *'
version: v1
此範例也會建立範例 hello.dtsx 套件。
您所有的應用程式檔案都位於與 spec.yaml 相同的目錄中。 spec.yaml 必須位於您應用程式原始程式碼目錄的根層級,包括 dtsx 檔案。
如需後續步驟,請參閱如何在 SQL Server 巨量資料叢集上部署應用程式。
dtexec 公用程式執行階段的限制
Linux 上 SQL Server Integration Services (SSIS) 的所有限制和已知問題都適用於 SQL Server 巨量資料叢集。 您可以從 Linux 上的 SSIS 限制和已知問題中了解更多資訊。
使用應用程式部署 MLeap 執行階段
應用程式部署 MLeap 執行階段支援 MLeap Service v0.13.0。
在應用程式部署中,您可以在 spec.yaml 提供控制器需要知道才能部署應用程式的資訊。 以下是可以指定的欄位:
name:應用程式名稱version:例如,應用程式版本,如v1runtime:應用程式部署執行階段,您必須將其指定為:Mleap
除了上述欄位之外,您還需要指定 MLeap 應用程式的 bundleFileName。 這會產生 spec.yaml 檔案,類似如下:
#spec.yaml
name: mleap-census
version: v1
runtime: Mleap
bundleFileName: census-bundle.zip
replicas: 1
您可以使用下列命令來建立部署新 MLeap 應用程式所需的基本資料夾和檔案結構:
azdata app init --template mleap --name hello-mleap --version v1
如需後續步驟,請參閱如何在 SQL Server 巨量資料叢集上部署應用程式。
MLeap 執行階段的限制
這些限制與 MLeap 開放原始碼專案 GitHub 上的 Combust的願景一致。
下一步
若要深入了解如何在 SQL Server 巨量資料叢集上建立並執行應用程式,請參閱下列各項:
若要深入了解 SQL Server 巨量資料叢集,請參閱下列概觀: