從存放集區將 CSV 資料虛擬化 (巨量資料叢集)
重要
Microsoft SQL Server 2019 巨量資料叢集附加元件將會淘汰。 SQL Server 2019 巨量資料叢集的支援將於 2025 年 2 月 28 日結束。 平台上將完全支援含軟體保證 SQL Server 2019 的所有現有使用者,而且軟體將會持續透過 SQL Server 累積更新來維護,直到該時間為止。 如需詳細資訊,請參閱公告部落格文章與 Microsoft SQL Server 平台上的巨量資料選項。
SQL Server 巨量資料叢集可從 HDFS 中的 CSV 檔案將資料虛擬化。 此程序可供資料保留在原始位置,但可從 SQL Server 執行個體進行查詢,就像任何其他資料表一樣。 此功能使用 PolyBase 連接器,並可將 ETL 程序的需求降到最低。 如需資料虛擬化的詳細資訊,請參閱使用 PolyBase 進行資料虛擬化簡介
Prerequisites
選取或上傳 CSV 檔案以用於資料虛擬化
在 Azure Data Studio (ADS) 中,連線到巨量資料叢集的 SQL Server 主要執行個體。 連線之後,展開物件瀏覽器中的 HDFS 元素,以找出您想要進行資料虛擬化的 CSV 檔案。
基於本教學課程的目的,請建立名為 Data 的新目錄。
- 以滑鼠右鍵按一下 HDFS 根目錄操作功能表。
- 選取 [新增目錄]。
- 將新目錄命名為 Data。
上傳範例資料。 如需簡單的逐步解說,可使用範例 CSV 資料檔案。 本文使用美國運輸部的航空公司誤點原因資料。 請下載未經處理資料,並將資料解壓縮至電腦。 將檔案命名為 airline_delay_causes.csv。
解壓縮範例檔案後,將其上傳:
- 在 Azure Data Studio 中,以滑鼠「右鍵」 按一下所建立的新目錄。
- 選取 [上傳檔案]。
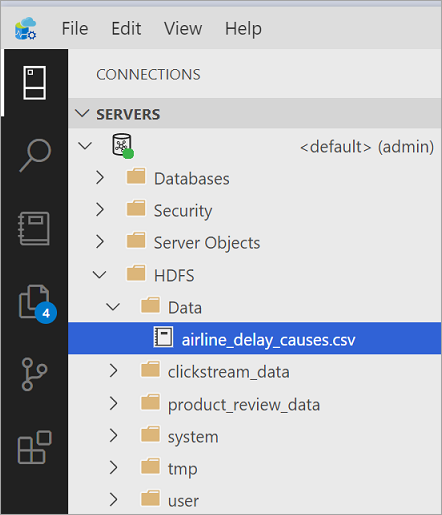
Azure Data Studio 會將檔案上傳到巨量資料叢集上的 HDFS。
在目標資料庫中建立存放集區外部資料來源
根據預設,已不會在巨量資料叢集中的資料庫中建立存放集區外部資料來源。 請使用下列 Transact-SQL 查詢在目標資料庫中建立預設的 SqlStoragePool 外部資料來源,才能建立外部資料表。 請務必先將查詢的內容變更為目標資料庫。
-- Create the default storage pool source for SQL Big Data Cluster
IF NOT EXISTS(SELECT * FROM sys.external_data_sources WHERE name = 'SqlStoragePool')
CREATE EXTERNAL DATA SOURCE SqlStoragePool
WITH (LOCATION = 'sqlhdfs://controller-svc/default');
建立外部資料表
從 ADS 以滑鼠右鍵按一下 CSV 檔案,然後從操作功能表選取 [Create External Table From CSV File] \(從 CSV 檔案建立外部資料表\) 。 您也可以從 HDFS 中目錄內的 CSV 檔案建立外部資料表,但前提是這些檔案的所在目錄遵循相同結構描述。 如此可在目錄層級虛擬化資料,而不需要處理個別檔案並透過合併資料來取得聯結的結果集。 Azure Data Studio 會引導您完成建立外部資料表的步驟。
指定資料庫、資料來源、資料表名稱、結構描述及資料表外部檔案格式的名稱。
選取 [下一步]。
預覽資料
Azure Data Studio 提供匯入資料的預覽。
![顯示 [從 CSV 建立外部資料表] 視窗的螢幕擷取畫面,其中包含已匯入資料的預覽。](media/data-virtualization/130-csv-preview-data.png?view=sql-server-ver15)
完成檢視預覽後,請選取 [下一步] 以繼續
修改資料行
在下一個視窗中,您可修改想要建立的外部資料表資料行。 您可改變資料行名稱、變更資料類型,並允許可為 Null 的資料列。
![顯示步驟 3 修改資料行的 [從 CSV 建立外部資料表] 視窗螢幕擷取畫面。](media/data-virtualization/140-csv-modify-columns.png?view=sql-server-ver15)
驗證目的地資料行後,請選取 [下一步]。
摘要
此步驟提供您選項的摘要。 此步驟會提供 SQL Server 名稱、資料庫名稱、資料表名稱、資料表結構描述和外部資料表資訊。 在此步驟中,您可選擇產生指令碼或建立資料表。 [產生指令碼] 會使用 T-SQL 建立指令碼以建立外部資料來源。 [建立資料表] 會建立外部資料來源。
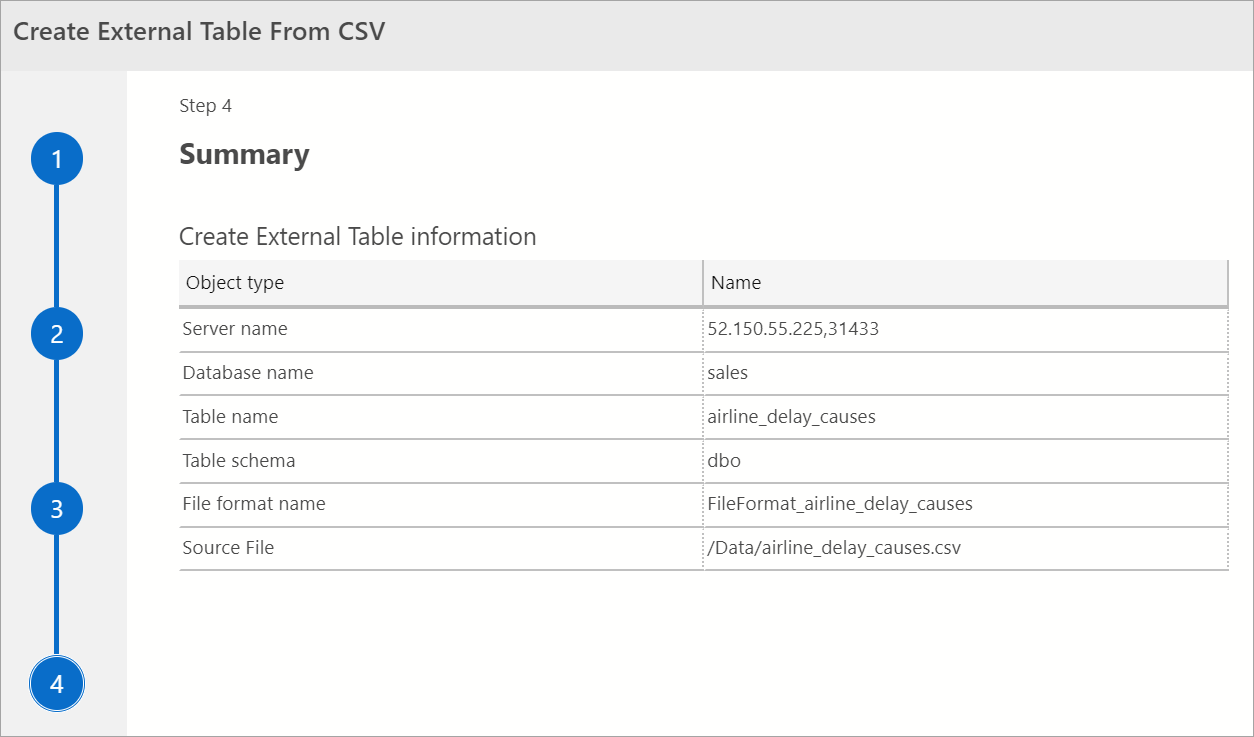
如果選取 [建立資料表],則 SQL Server 會在目的地資料庫中建立外部資料表。
如果選取 [產生指令碼],則 Azure Data Studio 會建立用來建立外部資料表的 T-SQL 查詢。
建立完成後,即可使用 SQL Server 執行個體的 T-SQL 直接查詢資料表。
後續步驟
如需 SQL Server 巨量資料叢集和相關案例的詳細資訊,請參閱 SQL Server 巨量資料叢集簡介。