監視 Always On 可用性群組的效能
適用於:![]() SQL Server
SQL Server
Always On 可用性群組的效能層面,對於維護關鍵任務資料庫的服務等級協定 (SLA) 來說非常重要。 了解可用性群組如何將記錄傳送至次要複本,可協助您 預估可用性實作的復原時間目標 (RTO) 與復原點目標 (RPO),以及針對效能不佳的可用性群組或複本來識別其中的瓶頸。 本文章會說明同步處理程序,示範如何計算一些關鍵計量,並提供某些常見效能疑難排解案例的連結。
資料同步處理程序
若要預估完整同步處理的時間並找出瓶頸,您需要了解同步處理程序。 效能瓶頸可能會在程序中的任何位置,而找出瓶頸可以協助您挖掘更深入的底層問題。 下圖和下表說明資料同步處理程序:

| 順序 | 步驟描述 | 註解 | 實用的計量 |
|---|---|---|---|
| 1 | 記錄檔產生 | 記錄檔資料會排清至磁碟。 此記錄檔必須複寫到次要複本。 記錄檔記錄會進入傳送佇列。 | SQL Server:Database > 每秒排清的記錄位元組 |
| 2 | 擷取 | 這會擷取每個資料庫的記錄檔並傳送至對應的夥伴佇列 (每個資料庫複本組一個)。 只要已連接可用性複本且資料移動未因任何原因暫停,此擷取程序就會持續執行,且資料庫複本組會顯示為「同步處理中」或「已同步處理」兩者之一。 如果擷取程序掃描訊息並將它加入佇列的速度不夠快,則會建立記錄檔傳送佇列。 | SQL Server:可用性複本 > 傳送到複本的位元組/秒,這是針對該可用性複本排入佇列的所有資料庫訊息總和彙總。 主要複本上為 log_send_queue_size (KB) 和 log_bytes_send_rate (KB/秒)。 |
| 3 | Send | 這會清除每個資料庫複本佇列中的訊息佇列,並跨線路傳送到個別的次要複本。 | SQL Server:可用性複本 > 每秒傳送到傳輸的位元組數 |
| 4 | 接收並快取 | 每個次要複本會接收並快取訊息。 | 效能計數器 SQL Server:可用性複本 > 每秒接收的位元組數 |
| 5 | 強行寫入 | 這會排清次要複本上的記錄檔,以進行強行寫入。 在記錄排清後,會將認知傳送回主要複本。 一旦強行寫入記錄檔,可以避免資料遺失。 |
效能計數器 SQL Server:資料庫 > 每秒排清的記錄檔位元組數 等候類型 HADR_LOGCAPTURE_SYNC |
| 6 | 取消復原 | 在次要複本上重做排清的分頁。 頁面等候重做時會保留在重做佇列中。 | SQL Server:資料庫複本 > 每秒重做的位元組數 redo_queue_size (KB) 和 redo_rate。 等候類型 REDO_SYNC |
流程控制閘道
可用性群組是以主要複本上的流程控制閘道設計,以避免所有可用性複本上過多的資源耗用,例如網路和記憶體資源。 這些流程控制閘道不會影響可用性複本的同步處理健康情況狀態,但它們可能會影響您的可用性資料庫 (包括 RPO) 的整體效能。
在主要複本上擷取記錄檔後,記錄檔會受限於兩個層級的流量控制。 一旦達到其中一個閘道的訊息閾值,記錄檔訊息便不會再傳送至特定複本,或是針對特定資料庫傳送。 一旦收到傳送訊息的認知訊息,即可傳送訊息來讓傳送的訊息數目低於閾值。
除了流程控制閘道以外,還有另外一個防止傳送記錄檔訊息的因素。 複本的同步處理可確保訊息會以記錄序號 (LSN) 的順序傳送並套用。 在傳送記錄檔訊息之前,也會針對最低認可 LSN 編號檢查其 LSN,以確定它小於其中一個閾值 (根據訊息類型而定)。 如果兩個 LSN 編號之間的間距大於閾值,則不會傳送訊息。 一旦間距再次低於閾值,則會傳送訊息。
SQL Server 2022 會對每個閘道允許的訊息數目增加限制。 藉由使用追蹤旗標 12310,增加的限制也可供下列版本的 SQL Server 使用,從下列版本開始:SQL Server 2019 CU9、SQL Server 2017 CU18,以及 SQL Server 2016 SP1 CU16。
下表比較訊息限制:
啟用追蹤旗標 12310 的 SQL Server 2022 和支援的 SQL Server 版本 (從 SQL Server 2019 CU9、SQL Server 2017 CU18 和 SQL Server 2016 SP1 CU16 開始),請參閱下列限制:
| 層級 | 閘道數目 | 訊息數目 | 實用的計量 |
|---|---|---|---|
| 傳輸 | 每個可用性複本 1 個 | 16384 | 擴充事件 database_transport_flow_control_action |
| 資料庫 | 每個可用性資料庫 1 個 | 7168 | DBMIRROR_SEND 擴充事件 hadron_database_flow_control_action |
兩個實用的效能計數器 SQL Server:可用性複本 > 每秒的流量控制和 SQL Server:可用性複本 > 每毫秒/秒的流量控制時間,會為您顯示上一秒內已啟動多少次流量控制,以及花費多少時間等候流量控制。 較高的流程控制等候時間會轉譯為較高的 RPO。 針對可能造成較高流程控制等候時間的問題,如需問題類型的詳細資訊,請參閱疑難排解:可用性群組超過 RPO。
預估容錯移轉時間 (RTO)
您 SLA 中的 RTO 會取決於您的 Always On 實作在任何給定時間的容錯移轉時間,可以用下列公式表示:

重要
如果可用性群組包含多個可用性資料庫,則包含最高 Tfailover 的可用性資料庫會變成 RTO 合規性的限制值。
失敗偵測時間 Tdetection 是系統用來偵測失敗的時間。 此時間取決於叢集層級設定,而不是個別可用性複本。 根據已設定的自動容錯移轉條件,則可能會觸發容錯移轉作為關鍵 SQL Server 內部錯誤的立即回應,例如孤立執行緒同步鎖定。 在此情況下,偵測可以和 sp_server_diagnostics (Transact-SQL) 錯誤報告傳送至 WSFC 叢集同樣快速 (預設間隔為健康情況檢查逾時的 1/3)。 容錯移轉也可因為逾時而觸發,例如叢集健康情況檢查逾時已過期 (預設為 30 秒) 或資源 DLL 和 SQL Server 執行個體之間的租用已過期 (預設為 20 秒)。 在此情況下,偵測時間與逾時間隔長度相同。 如需詳細資訊,請參閱可用性群組自動容錯移轉的彈性容錯移轉原則 (SQL Server)。
次要複本為了準備好進行容錯移轉而必須做的一件事,就是讓重做趕上記錄檔的結尾。 重做時間 Tredo 是使用下列公式計算的:

其中 redo_queue 是 redo_queue_size 中的值,而 redo_rate 是 redo_rate 中的值。
容錯移轉負擔時間 Toverhead 包含系統用來容錯移轉 WSFC 叢集,並讓資料庫上線的時間。 此時間通常簡短且一致。
預估潛在資料遺失 (RPO)
您 SLA 中的 RPO 取決於您的 Always On 實作在任何給定時間的潛在資料遺失。 這個可能的資料遺失可以用下列公式來表示:

其中 log_send_queue 是 log_send_queue_size 的值,而記錄檔產生速率是 SQL Server:資料庫 > 每秒排清的記錄檔位元組數的值。
警告
如果可用性群組包含多個可用性資料庫,則包含最高 Tdata_loss 的可用性資料庫會變成 RPO 合規性的限制值。
記錄檔傳送佇列表示可能會從從重大失敗遺失的所有資料。 使用記錄檔產生速率而非記錄檔傳送速率,第一眼看起來不尋常 (請參閱 log_send_rate)。 不過,請記住,使用記錄檔傳送速率僅能提供您同步處理的時間,而 RPO 會根據資料產生的速度 (而非同步處理資料的速度) 來測量資料遺失。
預估 Tdata_loss 更簡單的方式是使用 last_commit_time。 在主要複本上的 DMV 會針對所有複本回報此值。 您可以計算主要複本的值和次要複本的值之間的差異,以預估次要複本上的記錄檔趕上主要複本的速度。 如先前所述,這個計算不會根據記錄檔產生的速度告訴您潛在的資料遺失,但應為近似值。
使用 SSMS 儀表板預估 RTO 和 RPO
在 Always On 可用性群組中,會針對次要複本上裝載的資料庫計算和顯示 RTO 和 RPO。 在主要複本的儀表板上,次要複本會將 RTO 和 RPO 群組在一起。
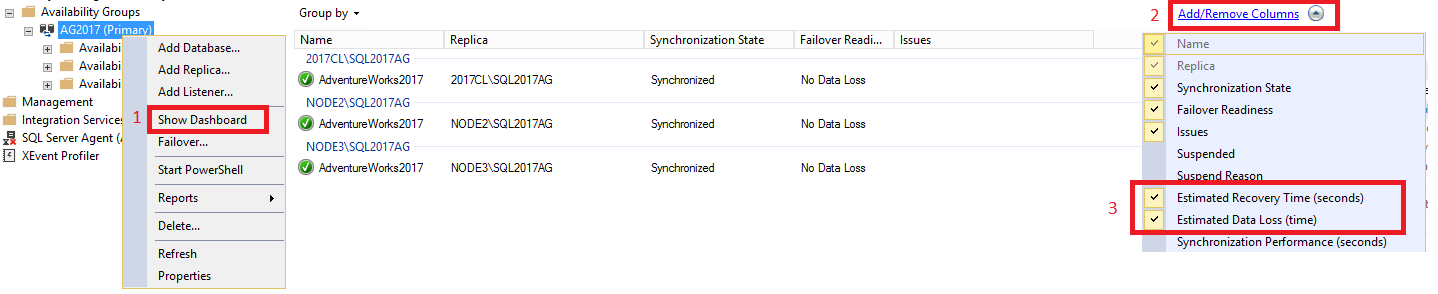
若要在儀表板內檢視 RTO 和 RPO,請執行下列作業:
在 SQL Server Management Studio 中,展開 [Always On 高可用性] 節點,並以滑鼠右鍵按一下您的可用性群組名稱,然後選取 [顯示儀表板] 。
選取 [群組依據] 索引標籤下方的 [新增/移除資料行] 。檢查 [預估復原時間 (秒)] [RTO] 和 [估計的資料遺失 (時間)] [RPO]。
計算次要資料庫 RTO
復原時間計算可判斷在容錯移轉之後需要多少時間來復原「次要資料庫」 。 容錯移轉時間通常簡短且一致。 偵測時間取決於叢集層級設定,而不是個別可用性複本。
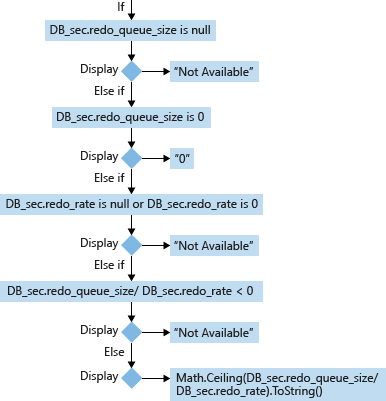
針對次要資料庫 (DB_sec),其 RTO 的計算和顯示會根據其 redo_queue_size 和 redo_rate:
除了邊角案例之外,用來計算次要資料庫 RTO 的公式是:
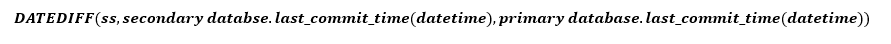
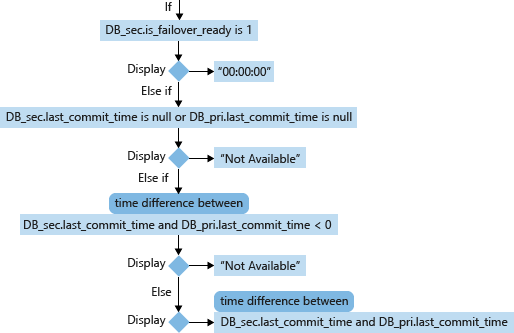
計算次要資料庫 RPO
針對次要資料庫 (DB_sec),其 RPO 的計算和顯示會根據其 is_failover_ready、last_commit_time 以及其相互關聯主要資料庫 (DB_pri) 的 last_commit_time。 secondary database.is_failover_ready = 1 時,會同步處理資料,而且在容錯移轉時不會遺失資料。 不過,如果此值為 0,則主要資料庫上的 last_commit_time 與次要資料庫上的 last_commit_time 之間會有差距。
針對主要資料庫,last_commit_time 是認可最新交易的時間。 針對次要資料庫,last_commit_time 是主要資料庫上已在次要資料庫上成功強化的交易最新認可時間。 主要和次要資料庫的這個數目應該相同。 這兩個值之間的差距是次要資料庫上尚未強化暫止交易的持續時間,而且將會在容錯移轉時遺失。
RTO/RPO 公式中使用的效能計數器
- redo_queue_size (KB) [用於 RTO] :重做佇列大小是其 last_received_lsn 與 last_redone_lsn 之間的交易記錄大小。 last_received_lsn 是記錄檔區塊識別碼,可識別裝載此次要資料庫的次要複本已經接收所有記錄檔區塊到哪一點。 last_redone_lsn 是最後一個記錄檔記錄的記錄序號,而該記錄在次要資料庫上重做。 根據這兩個值,我們可以找出起始記錄區塊 (last_received_lsn) 和結尾記錄區塊 (last_redone_lsn) 的識別碼。 這兩個記錄區塊之間的空格接著可以代表尚未重做交易記錄區塊數目。 這是以 KB 來測量。
- redo_rate (KB/秒) [用於 RTO] :累加值,在耗用期間,代表次要資料庫上已重做的交易記錄數量 (KB) (以KB/秒為單位)。
- last_commit_time (Datetime) [用於 RPO] :針對主要資料庫,last_commit_time 是認可最新交易的時間。 針對次要資料庫,last_commit_time 是主要資料庫上已在次要資料庫上成功強化的交易最新認可時間。 因為次要複本上的這個值應該與主要複本上的相同值同步,所以這兩個值之間的任何差距就是預估資料遺失 (RPO)。
使用 DMV 預估 RTO 和 RPO
可能會查詢 DMV sys.dm_hadr_database_replica_states 和 sys.dm_hadr_database_replica_cluster_states 來預估資料庫的 RPO 和 RTO。 下列查詢會建立可完成這兩個事項的預存程序。
注意
請務必先建立並執行預存程序來預估 RTO,因為需要有它所產生的值才能執行預存程序來預估 RPO。
建立預存程序來預估 RTO
- 在目標次要複本上,建立預存程序 proc_calculate_RTO。 如果此預存程序已經存在,請先將它卸除後再重新建立。
if object_id(N'proc_calculate_RTO', 'p') is not null
drop procedure proc_calculate_RTO
go
raiserror('creating procedure proc_calculate_RTO', 0,1) with nowait
go
--
-- name: proc_calculate_RTO
--
-- description: Calculate RTO of a secondary database.
--
-- parameters: @secondary_database_name nvarchar(max): name of the secondary database.
--
-- security: this is a public interface object.
--
create procedure proc_calculate_RTO
(
@secondary_database_name nvarchar(max)
)
as
begin
declare @db sysname
declare @is_primary_replica bit
declare @is_failover_ready bit
declare @redo_queue_size bigint
declare @redo_rate bigint
declare @replica_id uniqueidentifier
declare @group_database_id uniqueidentifier
declare @group_id uniqueidentifier
declare @RTO float
select
@is_primary_replica = dbr.is_primary_replica,
@is_failover_ready = dbcs.is_failover_ready,
@redo_queue_size = dbr.redo_queue_size,
@redo_rate = dbr.redo_rate,
@replica_id = dbr.replica_id,
@group_database_id = dbr.group_database_id,
@group_id = dbr.group_id
from sys.dm_hadr_database_replica_states dbr join sys.dm_hadr_database_replica_cluster_states dbcs on dbr.replica_id = dbcs.replica_id and
dbr.group_database_id = dbcs.group_database_id where dbcs.database_name = @secondary_database_name
if @is_primary_replica is null or @is_failover_ready is null or @redo_queue_size is null or @replica_id is null or @group_database_id is null or @group_id is null
begin
print 'RTO of Database '+ @secondary_database_name +' is not available'
return
end
else if @is_primary_replica = 1
begin
print 'You are visiting wrong replica';
return
end
if @redo_queue_size = 0
set @RTO = 0
else if @redo_rate is null or @redo_rate = 0
begin
print 'RTO of Database '+ @secondary_database_name +' is not available'
return
end
else
set @RTO = CAST(@redo_queue_size AS float) / @redo_rate
print 'RTO of Database '+ @secondary_database_name +' is ' + convert(varchar, ceiling(@RTO))
print 'group_id of Database '+ @secondary_database_name +' is ' + convert(nvarchar(50), @group_id)
print 'replica_id of Database '+ @secondary_database_name +' is ' + convert(nvarchar(50), @replica_id)
print 'group_database_id of Database '+ @secondary_database_name +' is ' + convert(nvarchar(50), @group_database_id)
end
- 使用目標次要資料庫名稱,執行 proc_calculate_RTO:
exec proc_calculate_RTO @secondary_database_name = N'DB_sec'
輸出會顯示目標次要複本資料庫的 RTO 值。 儲存 group_id、replica_id 和 group_database_id,以與 RPO 預估預存程序搭配使用。
範例輸出:
資料庫 DB_sec' 的 RTO 是 0
資料庫 DB4 的 group_id 是 F176DD65-C3EE-4240-BA23-EA615F965C9B
資料庫 DB4 的 replica_id 是 405554F6-3FDC-4593-A650-2067F5FABFFD
資料庫 DB4 的 group_database_id 是 39F7942F-7B5E-42C5-977D-02E7FFA6C392
建立預存程序來預估 RPO
- 在主要複本上,建立預存程序 proc_calculate_RPO。 如果它已經存在,請先將它卸除後再重新建立。
if object_id(N'proc_calculate_RPO', 'p') is not null
drop procedure proc_calculate_RPO
go
raiserror('creating procedure proc_calculate_RPO', 0,1) with nowait
go
--
-- name: proc_calculate_RPO
--
-- description: Calculate RPO of a secondary database.
--
-- parameters: @group_id uniqueidentifier: group_id of the secondary database.
-- @replica_id uniqueidentifier: replica_id of the secondary database.
-- @group_database_id uniqueidentifier: group_database_id of the secondary database.
--
-- security: this is a public interface object.
--
create procedure proc_calculate_RPO
(
@group_id uniqueidentifier,
@replica_id uniqueidentifier,
@group_database_id uniqueidentifier
)
as
begin
declare @db_name sysname
declare @is_primary_replica bit
declare @is_failover_ready bit
declare @is_local bit
declare @last_commit_time_sec datetime
declare @last_commit_time_pri datetime
declare @RPO nvarchar(max)
-- secondary database's last_commit_time
select
@db_name = dbcs.database_name,
@is_failover_ready = dbcs.is_failover_ready,
@last_commit_time_sec = dbr.last_commit_time
from sys.dm_hadr_database_replica_states dbr join sys.dm_hadr_database_replica_cluster_states dbcs on dbr.replica_id = dbcs.replica_id and
dbr.group_database_id = dbcs.group_database_id where dbr.group_id = @group_id and dbr.replica_id = @replica_id and dbr.group_database_id = @group_database_id
-- correlated primary database's last_commit_time
select
@last_commit_time_pri = dbr.last_commit_time,
@is_local = dbr.is_local
from sys.dm_hadr_database_replica_states dbr join sys.dm_hadr_database_replica_cluster_states dbcs on dbr.replica_id = dbcs.replica_id and
dbr.group_database_id = dbcs.group_database_id where dbr.group_id = @group_id and dbr.is_primary_replica = 1 and dbr.group_database_id = @group_database_id
if @is_local is null or @is_failover_ready is null
begin
print 'RPO of database '+ @db_name +' is not available'
return
end
if @is_local = 0
begin
print 'You are visiting wrong replica'
return
end
if @is_failover_ready = 1
set @RPO = '00:00:00'
else if @last_commit_time_sec is null or @last_commit_time_pri is null
begin
print 'RPO of database '+ @db_name +' is not available'
return
end
else
begin
if DATEDIFF(ss, @last_commit_time_sec, @last_commit_time_pri) < 0
begin
print 'RPO of database '+ @db_name +' is not available'
return
end
else
set @RPO = CONVERT(varchar, DATEADD(ms, datediff(ss ,@last_commit_time_sec, @last_commit_time_pri) * 1000, 0), 114)
end
print 'RPO of database '+ @db_name +' is ' + @RPO
end
- 使用目標次要資料庫的 group_id、replica_id 和 group_database_id,執行 proc_calculate_RPO。
exec proc_calculate_RPO @group_id= 'F176DD65-C3EE-4240-BA23-EA615F965C9B',
@replica_id = '405554F6-3FDC-4593-A650-2067F5FABFFD',
@group_database_id = '39F7942F-7B5E-42C5-977D-02E7FFA6C392'
- 輸出會顯示目標次要複本資料庫的 RPO 值。
監視 RTO 和 RPO
本節示範如何監視 RTO 和 RPO 計量的可用性群組。 此示範類似下列文章中提供的 GUI 教學課程:Always On 健康情況模型,第 2 部分:Extending the health model (Always On 健全狀況模型第 2 部分:擴充健全狀況模型)。
預估容錯移轉時間 (RTO) 和預估潛在資料遺失 (RPO) 中容錯移轉時間和潛在資料遺失的元素,會提供為原則管理 Facet 資料庫複本狀態中便利的效能計量 (請參閱檢閱 SQL Server 物件的原則式管理 Facet)。 您可以依排程監視這兩個計量,並在計量分別超過您的 RTO 和 RPO 時收到警示。
示範指令碼會建立依照其個別排程執行的兩個系統原則,具有下列特性:
當預估的容錯移轉時間超過 10 分鐘 (每 5 分鐘進行評估) 時會失敗的 RTO 原則
當預估的資料遺失超過 1 小時 (每 30 分鐘進行評估) 時會失敗的 RPO 原則
這兩個原則在所有可用性複本上具有相同的設定
原則會在所有的伺服器上評估,但僅限於本機可用性複本為主要複本的可用性群組上。 如果本機可用性複本不是主要複本,則不會評估原則。
當您在主要複本上檢視原則失敗時,它會顯示在 Always On 儀表板中。
若要建立原則,請在參與可用性群組的所有伺服器執行個體上依照下列指示執行:
啟動 SQL Server Agent 服務 (如果尚未啟動)。
在 SQL Server Management Studio 中,在 [工具] 功能表中,按一下 [選項] 。
在 [SQL Server Always On] 索引標籤中,選取 [啟用使用者定義 Always On 原則] 並按一下 [確定] 。
此設定可讓您在 Always On 儀表板中顯示已正確設定的自訂原則。
使用下列規格建立以原則為基礎的管理條件:
名稱:
RTOFacet:資料庫複本狀態
欄位:
Add(@EstimatedRecoveryTime, 60)運算子: <=
值:
600
當潛在容錯移轉時間超過 10 分鐘 (包括失敗偵測和容錯移轉的 60 秒額外負荷),此條件會失敗。
使用下列規格建立第二個以原則為基礎的管理條件:
名稱:
RPOFacet:資料庫複本狀態
欄位:
@EstimatedDataLoss運算子: <=
值:
3600
當潛在資料遺失超過 1 小時時,此條件會失敗。
使用下列規格建立第三個以原則為基礎的管理條件:
名稱:
IsPrimaryReplicaFacet:可用性群組
欄位:
@LocalReplicaRole運算子:=
值:
Primary
此條件會檢查給定可用性群組的本機可用性複本是否為主要複本。
使用下列規格建立以原則為基礎的管理原則:
[一般] 頁面:
名稱:
CustomSecondaryDatabaseRTO檢查條件:
RTO針對目標:IsPrimaryReplica AvailabilityGroup 中的每個 DatabaseReplicaState
此設定可確保原則僅於本機可用性複本為主要複本的可用性群組上評估。
評估模式:按排程時間
排程:CollectorSchedule_Every_5min
已啟用:選取
[描述] 頁面:
類別:可用性資料庫警告
此設定可讓原則評估結果在 Always On 儀表板中顯示。
描述:目前複本擁有已超過 10 分鐘的 RTO,假設 1 分鐘的額外負荷進行探索及容錯移轉。您應該立即調查個別的伺服器執行個體上的效能問題。
要顯示的文字:已超過 RTO!
使用下列規格建立第二個以原則為基礎的管理原則:
[一般] 頁面:
名稱:
CustomAvailabilityDatabaseRPO檢查條件:
RPO針對目標:IsPrimaryReplica AvailabilityGroup 中的每個 DatabaseReplicaState
評估模式:按排程時間
排程:CollectorSchedule_Every_30min
已啟用:選取
[描述] 頁面:
類別:可用性資料庫警告
描述:可用性資料庫已超過您的 1 小時 RPO。您應該立即調查可用性複本上的效能問題。
要顯示的文字:已超過 RPO!
當您完成時,會分別針對每個原則評估排程建立兩個新的 SQL Server Agent 作業。 這些作業的名稱開頭應該為 syspolicy_check_schedule。
您可以檢視作業記錄以檢查評估結果。 評估失敗也會記錄在事件識別碼為 34052 的 Windows 應用程式記錄檔中 (位於 [事件檢視器])。 您也可以設定 SQL Server Agent 在原則失敗時傳送警示。 如需詳細資訊,請參閱設定警示,在原則失敗時通知原則系統管理員。
效能疑難排解案例
下表列出常見的效能相關疑難排解案例。
| 狀況 | 描述 |
|---|---|
| 疑難排解:可用性群組已超過 RTO | 在自動容錯移轉或規劃的手動容錯移轉之後若未遺失資料,容錯移轉時間會超過您的 RTO。 或者,當您評估同步認可次要複本 (例如自動容錯移轉夥伴) 的容錯移轉時間時,發現它超過您的 RTO。 |
| 疑難排解:可用性群組已超過 RPO | 在您執行強制手動容錯移轉之後,遺失的資料超過您的 RPO。 或者,當您計算非同步認可次要複本的潛在資料遺失時,發現它超過您的 RPO。 |
| 疑難排解:對主要複本的變更未反映在次要複本上 | 用戶端應用程式在主要複本上成功完成更新,但是查詢次要複本卻顯示未反映變更。 |
實用的擴充事件
當針對同步處理中狀態的複本進行疑難排解時,下列擴充事件很有用。
| 活動名稱 | 類別 | 通路 | 可用性複本 |
|---|---|---|---|
| redo_caught_up | 交易 | 偵錯 | 次要 |
| redo_worker_entry | 交易 | 偵錯 | 次要 |
| hadr_transport_dump_message | alwayson |
偵錯 | Primary |
| hadr_worker_pool_task | alwayson |
偵錯 | Primary |
| hadr_dump_primary_progress | alwayson |
偵錯 | Primary |
| hadr_dump_log_progress | alwayson |
偵錯 | Primary |
| hadr_undo_of_redo_log_scan | alwayson |
分析 | 次要 |
意見反映
即將推出:我們會在 2024 年淘汰 GitHub 問題,並以全新的意見反應系統取代並作為內容意見反應的渠道。 如需更多資訊,請參閱:https://aka.ms/ContentUserFeedback。
提交及檢視以下的意見反映: