使用異常偵測器單變量 API 的最佳做法
重要
從 2023 年 9 月 20 日起,您將無法建立新的異常偵測器資源。 異常偵測器服務將於 2026 年 10 月 1 日淘汰。
異常偵測器 API 是無狀態的異常偵測服務。 其結果的精確度和效能可能會受到下列影響:
- 準備時間序列資料的方式。
- 已使用的異常偵測器 API 參數。
- API 要求中的資料點數目。
使用本文以了解使用 API 取得最佳資料結果的最佳做法。
何時使用批次 (整個) 或最新 (最後一個) 異常偵測點
異常偵測器 API 的批次偵測端點可讓您偵測整個時間序列資料中的異常。 在此偵測模式中,會建立單一統計模型並套用至資料集中的每個點。 如果您的時間序列具有下列特性,建議您使用批次偵測在一個 API 呼叫中預覽資料。
- 偶爾出現異常的季節性時間序列。
- 偶爾出現峰值/谷值的平坦趨勢時間序列。
不建議使用批次異常偵測進行即時資料監視,或在沒有上述特性的時間序列資料上使用。
批次偵測只會建立並套用一個模型,每個點的偵測都是在整個序列的內容中進行。 如果時間序列資料呈上升和下降趨勢而沒有季節性,則模型可能遺漏了某些變異點 (資料中的谷值和峰值)。 同樣地,某些變異點比資料集中較晚出現的點顯著性更低,因此可能不具有足以納入模型的顯著性。
進行即時資料監視時,由於批次偵測會分析點的數量,因此速度會比偵測最新點的異常狀態更慢。
若要進行即時資料監視,建議您只偵測最新資料點的異常狀態。 藉由持續套用最新點偵測,就能更有效率且精確地進行串流資料監視。
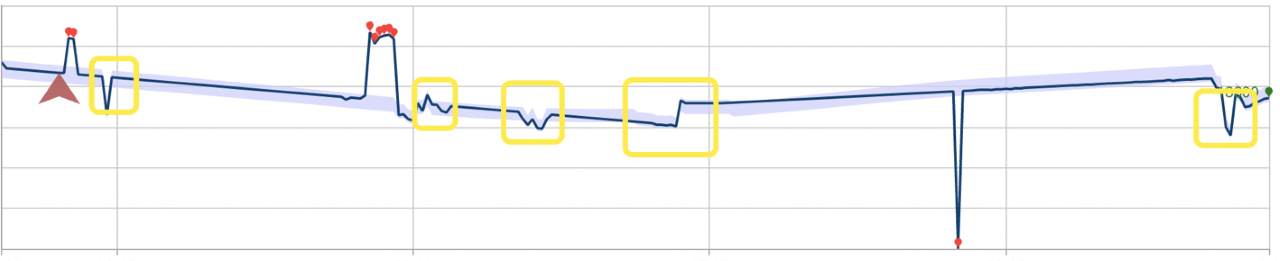
下列範例說明這些偵測模式可能會對效能造成的影響。 第一張圖片顯示持續偵測最新點及 28 個先前所看到資料點的異常狀態結果。 紅點表示異常。

以下是使用批次異常偵測的相同資料集。 針對作業所建立的模型已略過數個異常,並以矩形標示。
資料準備
異常偵測器 API 接受格式化為 JSON 要求物件的時間序列資料。 時間序列可以是一段時間內循序記錄的任何數值資料。 您可以將時間序列資料視窗傳送至異常偵測器 API 端點來提升 API 的效能。 您可以傳送的資料點數目下限為 12,上限為 8640 點。 資料粒度已定義為您資料的取樣率。
傳送至異常偵測器 API 的資料點必須具有有效的國際標準時間 (UTC) 時間戳記,以及一個數值。
{
"granularity": "daily",
"series": [
{
"timestamp": "2018-03-01T00:00:00Z",
"value": 32858923
},
{
"timestamp": "2018-03-02T00:00:00Z",
"value": 29615278
},
]
}
如果您的資料是依非標準時間間隔取樣,您可以透過在要求中新增 customInterval 屬性進行指定。 例如,如果您的序列每隔 5 分鐘取樣一次,您可以將下列內容新增至您的 JSON 要求:
{
"granularity" : "minutely",
"customInterval" : 5
}
遺漏資料點
平均分佈的時間序列資料集中經常會遺漏資料點,特別是具有精細資料粒度的資料集 (短取樣間隔。例如每隔幾分鐘取樣的資料)。 在您的資料中遺漏小於 10% 的預期點數,不應該會對偵測結果造成負面影響。 請考慮根據資料的特性來填補資料的間隙,例如替代早期的資料點、線性插補或移動平均。
彙總分散式資料
異常偵測器 API 最適用於平均分佈的時間序列。 如果您的資料是隨機分佈的,您應該依時間單位 (例如每分鐘、每小時或每日) 進行彙總。
對具有季節性模式的資料進行異常偵測
如果您知道時間序列資料具有季節性模式 (會定期出現),則可以改善精確度和 API 回應時間。
若在建構 JSON 要求時指定 period,可將異常偵測延遲降低高達 50%。 period 是一個整數,可大致指定時間序列重複模式所需的資料點數目。 例如,每天有一個資料點的時間序列會有 7 的 period,而每小時有一點的時間序列 (具有相同的每週模式) 會有 7*24 的 period。 如果您不確定資料的模式,則不需要指定此參數。
為了獲得最佳結果,請提供四個 period 的資料點,再加上一個額外的資料點。 例如,上述具有每週模式的每小時資料應該在要求本文中提供 673 個資料點 (7 * 24 * 4 + 1)。
取樣資料進行即時監視
如果您的串流資料是依短間隔 (例如秒或分鐘) 取樣,則傳送建議的資料點數目可能會超過異常偵測器 API 允許的數目上限 (8640 個資料點)。 如果您的資料顯示穩定的季節性模式,請考慮以較大的時間間隔 (例如小時) 傳送時間序列資料的樣本。 以這種方式取樣您的資料,也可明顯改善 API 回應時間。