如何使用自動標記進行自訂具名實體辨識
標記程序是在準備資料集時的重要部分。 由於此程序需要耗費時間和精力,因此您可以使用自動標記功能來自動標記實體。 您可以根據先前定型的模型或使用 GPT 模型,開始自動標記作業。 根據您先前定型的模型自動標記,您即可開始標記一些文件、定型模型,然後建立自動標記作業,以根據該模型為其他文件產生實體標籤。 使用 GPT 進行自動標記,您可以立即觸發自動標記作業,而不需任何先前的模型定型。 這項功能可節省手動標記實體的時間和精力。
必要條件
根據您已定型的模型使用自動標記之前,您需要:
觸發自動標記作業
當您根據您已定型的模型觸發自動標記作業時,每個資源的每月文字記錄上限為 5,000 筆。 這表示同一資源中的所有專案均套用相同的限制。
提示
文字記錄的上限計算方式為 (文件中的字元數/1,000)。 例如,如果文件有 8921 個字元,則文字記錄數為:
ceil(8921/1000) = ceil(8.921),也就是 9 筆文字記錄。
從左側導覽功能表,選取 [資料標記]。
選取頁面右側 [活動] 窗格底下的 [自動標籤] 按鈕。
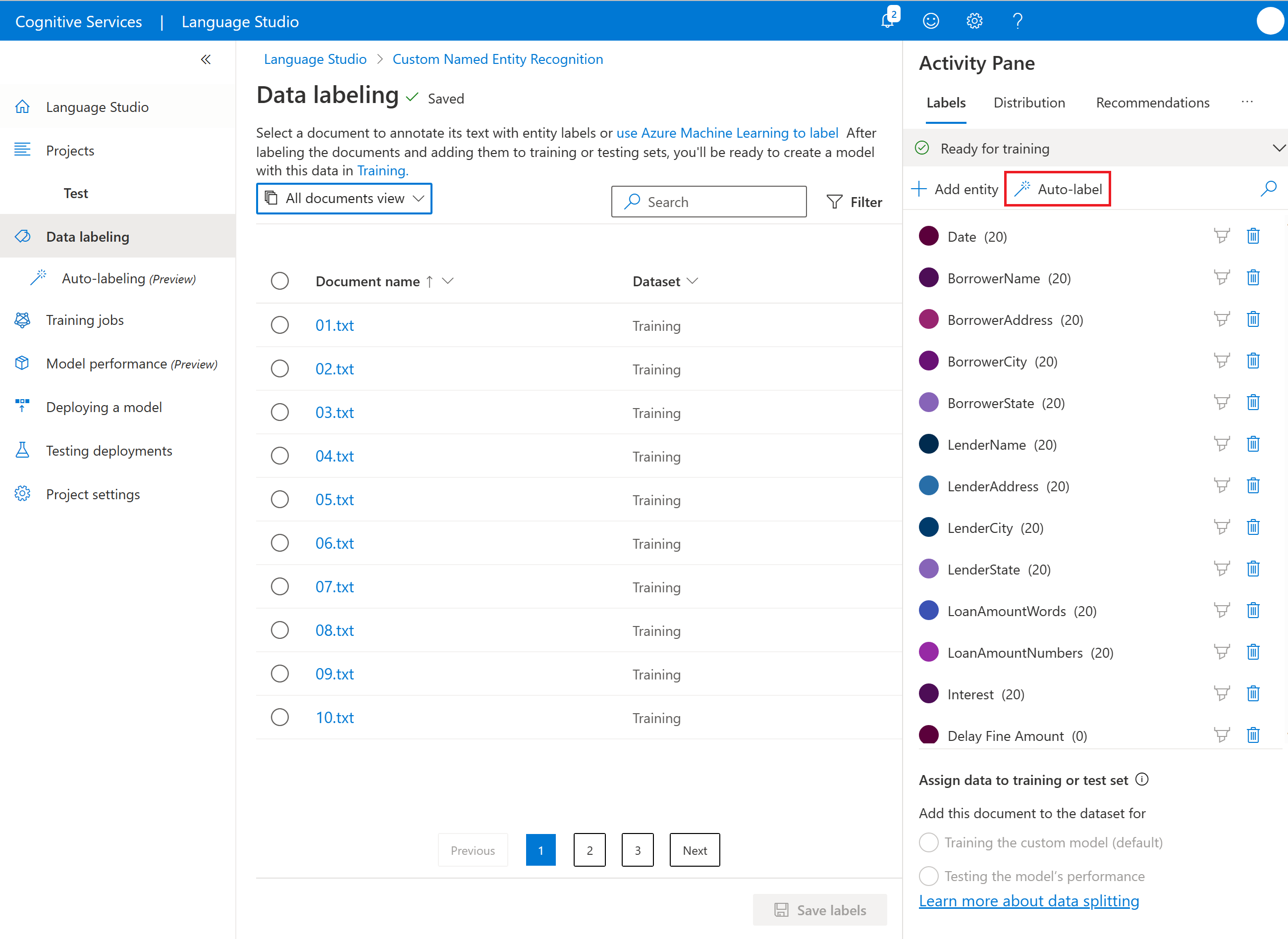
根據您已定型的模型選擇 [自動標記],然後選取 [下一步]。
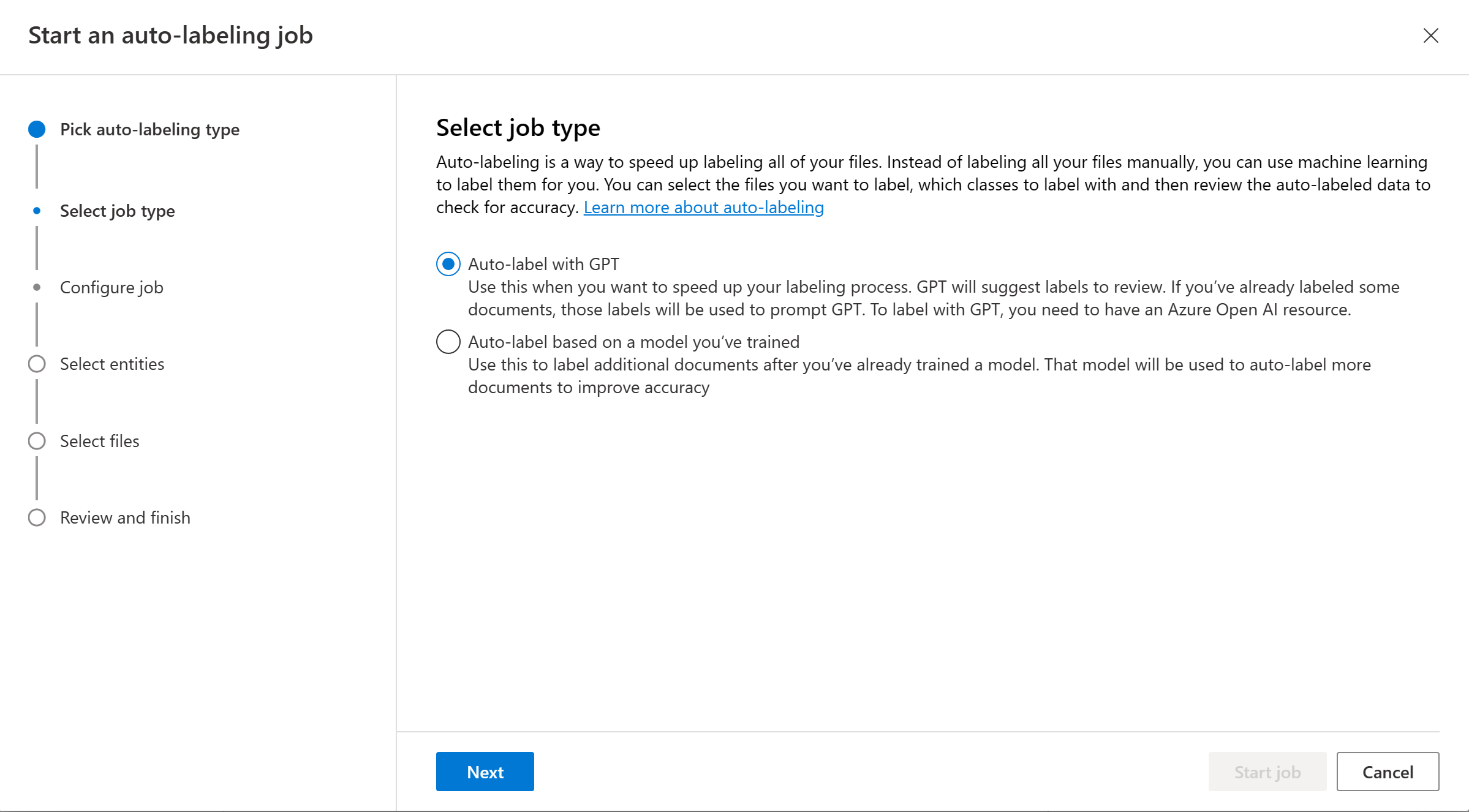
選擇定型的模型。 建議您先檢查模型效能,再將模型用於自動標記。
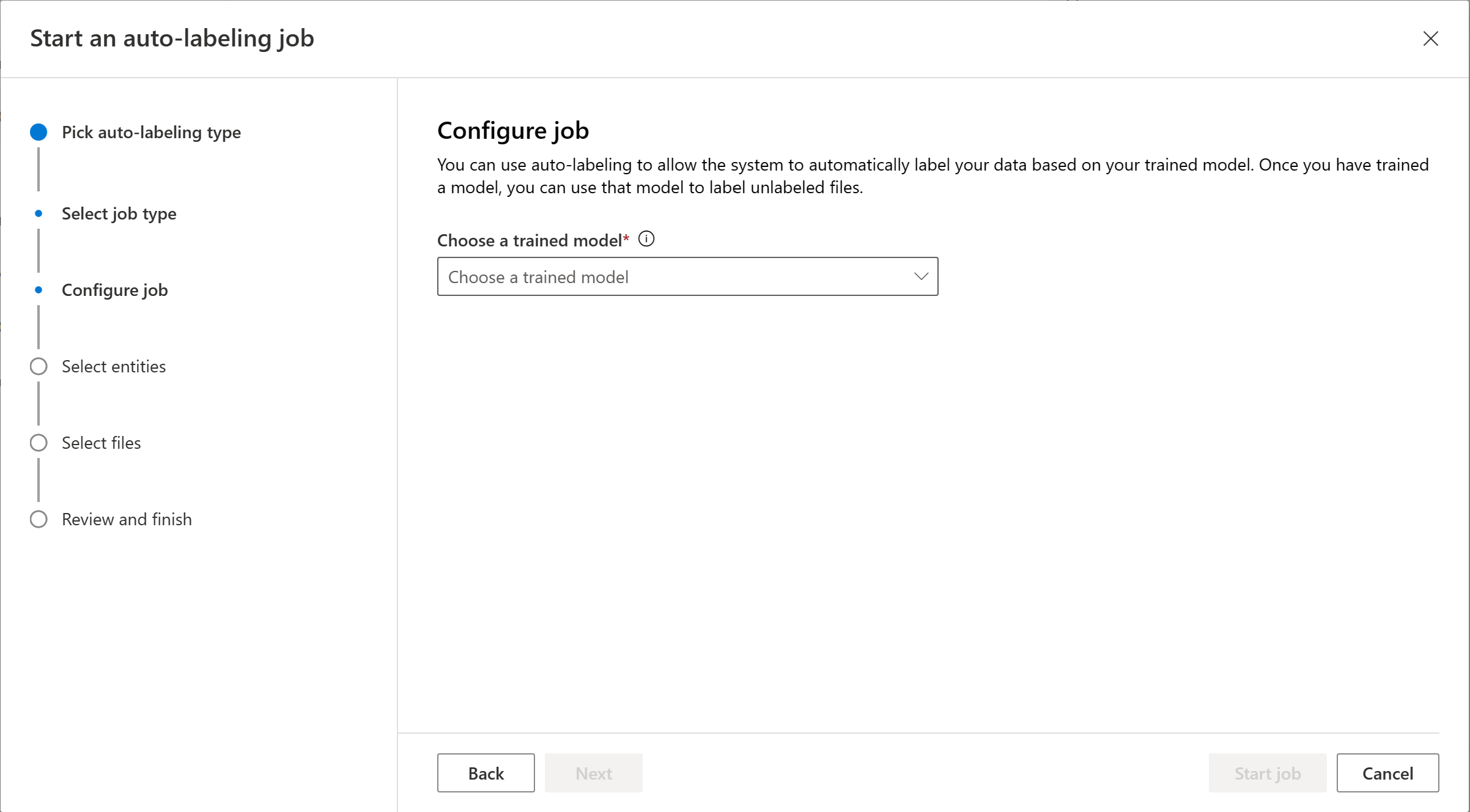
選擇您要納入自動標記作業的實體。 根據預設,會選取所有實體。 您可以看到每個實體的標籤總數、精確度和重新叫用率。 建議您納入效能良好的實體,以確保自動標記實體的品質。
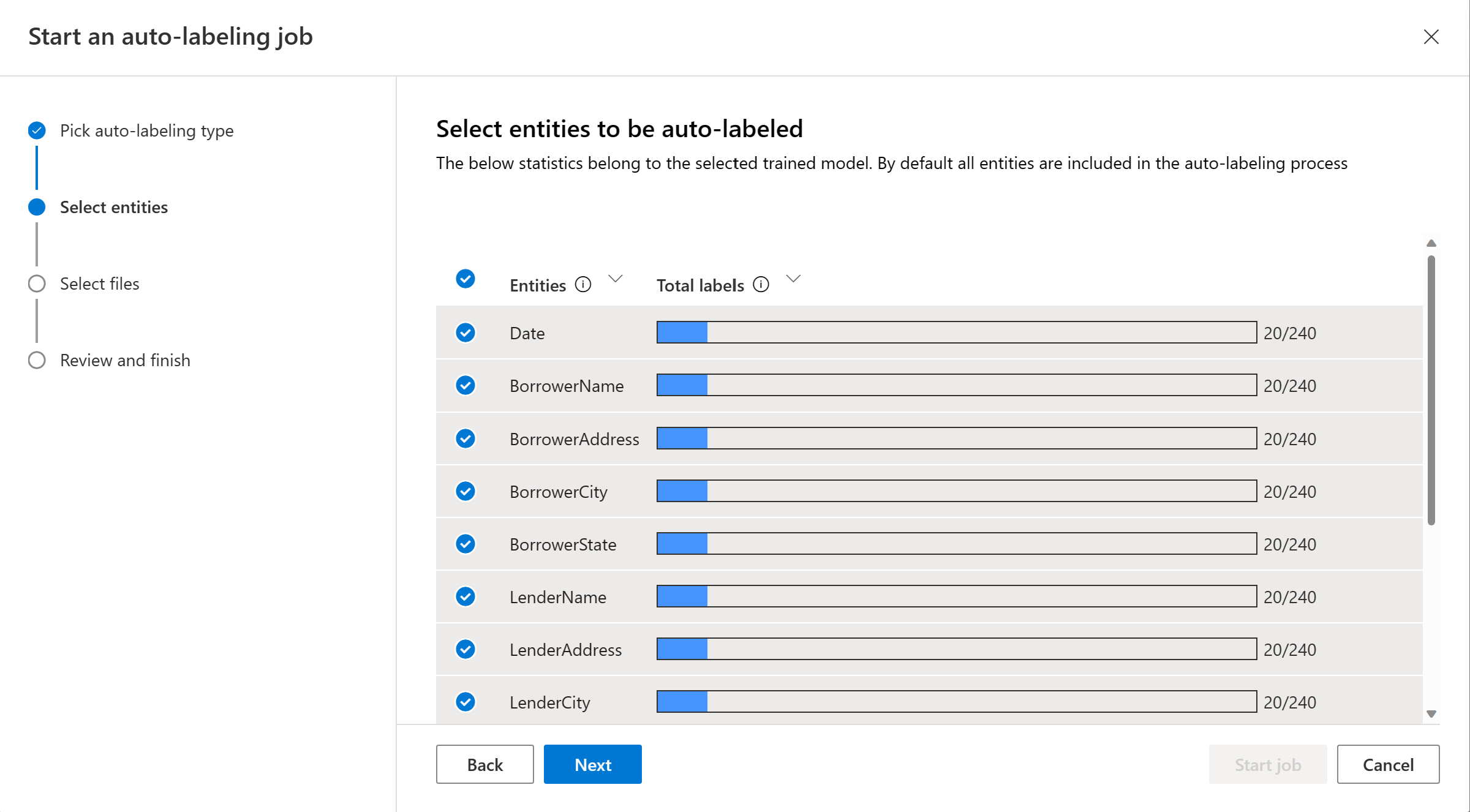
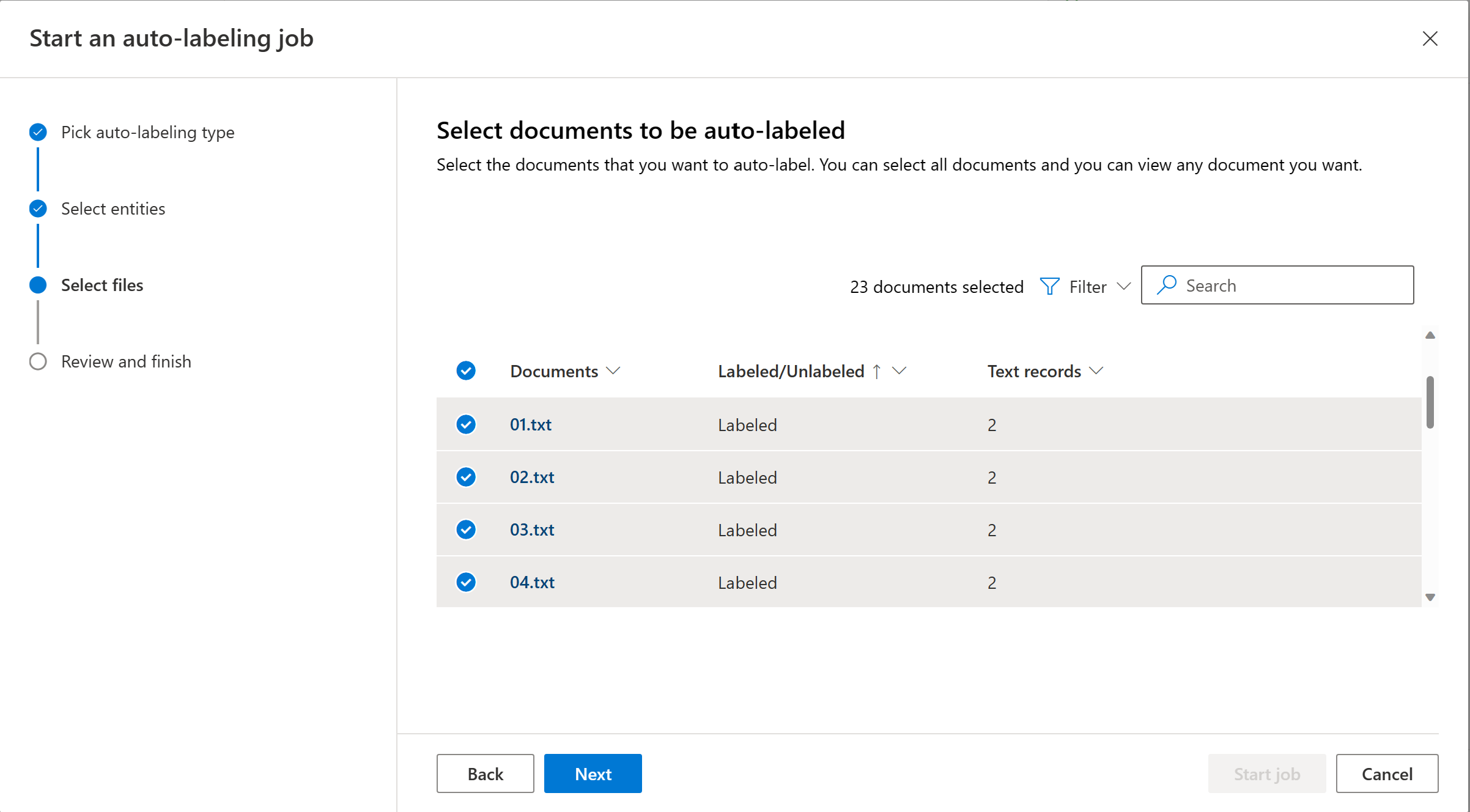
選擇要自動標記的文件。 每個文件的文字記錄數目隨即顯示。 當您選取一或多個文件時,應該會看到選取的文字記錄數目。 建議您從篩選條件中選擇未標記的文件。
注意
- 如果實體已自動標記,但具有使用者定義的標籤,則只會使用並顯示使用者定義的標籤。
- 您可以按一下文件名稱來檢視文件。
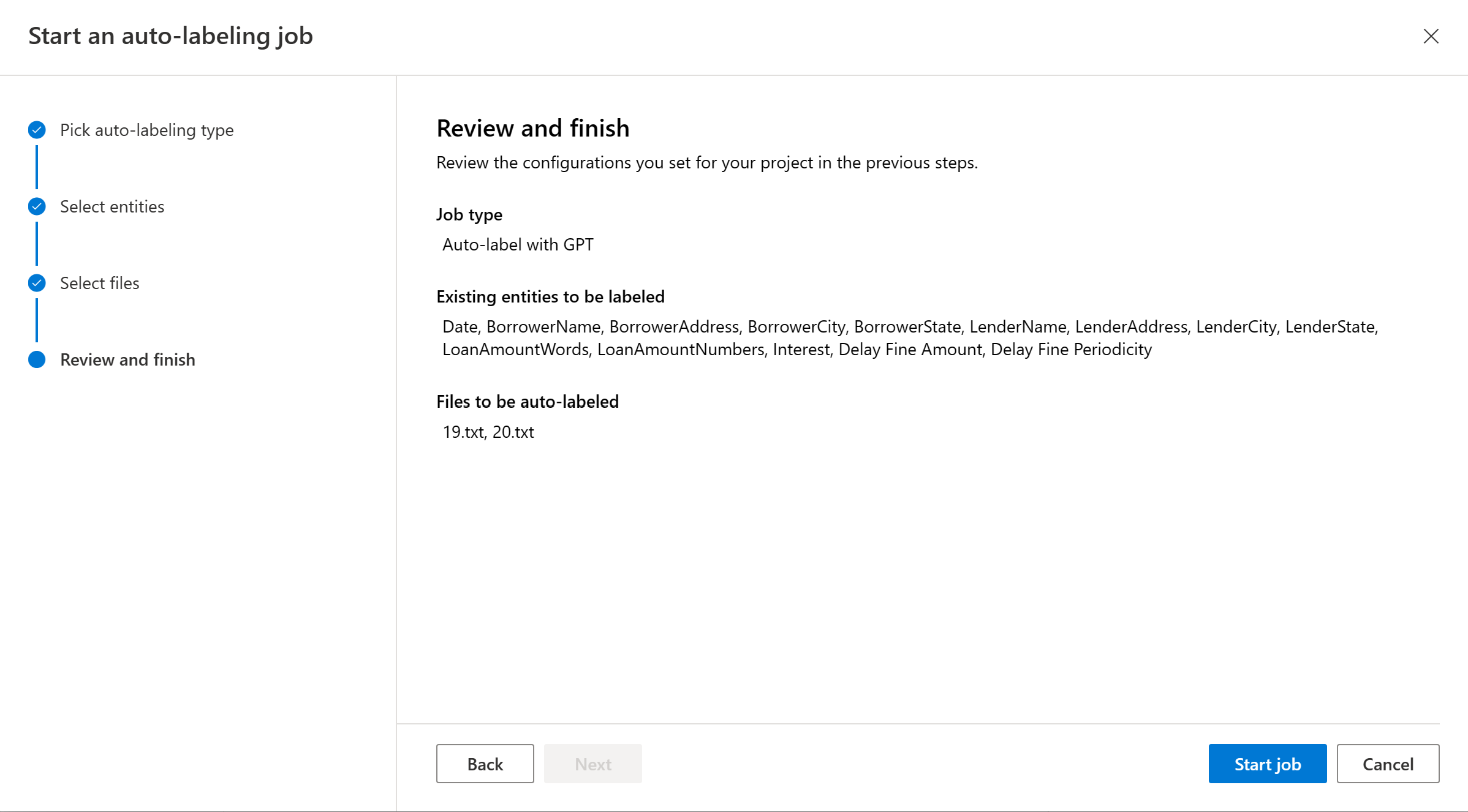
選取 [自動標記] 以觸發自動標記作業。 您應該會看到使用的模型、自動標記作業所含的文件數目、要自動標記的文字記錄和實體數目。 自動標記作業可能需要幾秒鐘到幾分鐘的時間,視您包含的文件數目而定。







檢閱已自動標記的文件
當自動標記作業完成時,您可以在 Language Studio 的 [資料標記] 頁面中看到輸出文件。 選取 [檢閱具有自動標記的文件],以檢視已套用已自動標記篩選條件的文件。

自動標記的實體將會以虛線顯示。 這些實體有兩個選取器 (核取記號和「X」),可讓您接受或拒絕自動標籤。
接受實體後,虛線會變更為實線,而且日後任何模型定型均會包含此標籤,成為使用者定義的標籤。
或者,您也可以使用畫面右上角的 [全部接受] 或 [全部拒絕],接受或拒絕文件中所有已自動標記的實體。
接受或拒絕標記的實體之後,請選取 [儲存標籤] 以套用變更。
注意
- 建議您先驗證自動標記的實體,再接受這些實體。
- 當您定型模型時,所有未接受的標籤都會遭到刪除。

下一步
- 深入了解如何標記資料。