了解如何使用 C# 在 HDInsight 上建立 MapReduce 方案。
Apache Hadoop 串流可讓您使用指令碼或可執行檔執行 MapReduce 作業。 在此處,.NET 用來實作字數統計方案的對應工具和歸納器。
HDInsight 上的 .NET
HDInsight 叢集會使用 Mono (https://mono-project.com) 來執行 .NET 應用程式。 4.2.1 版的 Mono 隨附於 3.6 版的 HDInsight。 如需 HDInsight 隨附 Mono 版本的詳細資訊,請參閱 HDInsight 版本提供的 Apache Hadoop 元件。
如需 Mono 與 .NET Framework 版本之相容性的詳細資訊,請參閱 Mono 相容性 \(英文\)。
Hadoop 串流的運作方式
本文件中使用於串流的基本程序如下︰
- Hadoop 在 STDIN 上將資料傳遞至對應工具 (在此範例中是 mapper.exe)。
- 對應工具會處理資料,然後發出以 Tab 分隔的機碼值組到 STDOUT。
- Hadoop 會讀取輸出,接著輸出會在 STDIN 上傳遞至歸納器 (在此範例中是 reducer.exe)。
- 歸納器會讀取以 Tab 分隔的機碼值組、處理資料,然後在 STDOUT 發出以 Tab 分隔的機碼值組格式結果。
- Hadoop 會讀取輸出,接著輸出會寫入至輸出目錄。
如需有關串流的詳細資訊,請參閱 Hadoop 串流 \(英文\)。
必要條件
Visual Studio。
熟悉如何撰寫和建置以 .NET Framework 4.5 為目標的 C# 程式碼。
將 .exe 檔案上傳至叢集的方式。 本文件中的步驟使用 Data Lake Tools for Visual Studio 將檔案上傳至叢集的主要儲存體。
如果使用 PowerShell,您將需要 Az 模組 \(部分機器翻譯\)。
HDInsight 上的 Apache Hadoop 叢集。 請參閱開始在 Linux 上使用 HDInsight。
叢集主要儲存體的 URI 配置。 此結構描述會是適用於 Azure 儲存體的
wasb://,適用於 Azure Data Lake Storage Gen2 的abfs://或適用於 Azure Data Lake Storage Gen1 的adl://。 如果針對 Azure 儲存體或 Data Lake Storage Gen2 已啟用安全傳輸,則 URI 分別會是wasbs://或abfss://。
建立對應工具
在 Visual Studio 中,建立名為 mapper 的新 .NET Framework 主控台應用程式。 針對此應用程式使用下列程式碼:
using System;
using System.Text.RegularExpressions;
namespace mapper
{
class Program
{
static void Main(string[] args)
{
string line;
//Hadoop passes data to the mapper on STDIN
while((line = Console.ReadLine()) != null)
{
// We only want words, so strip out punctuation, numbers, etc.
var onlyText = Regex.Replace(line, @"\.|;|:|,|[0-9]|'", "");
// Split at whitespace.
var words = Regex.Matches(onlyText, @"[\w]+");
// Loop over the words
foreach(var word in words)
{
//Emit tab-delimited key/value pairs.
//In this case, a word and a count of 1.
Console.WriteLine("{0}\t1",word);
}
}
}
}
}
在您建立應用程式之後,建置它以在專案目錄中產生 /bin/Debug/mapper.exe 檔案。
建立歸納器
在 Visual Studio 中,建立名為 reducer 的新 .NET Framework 主控台應用程式。 針對此應用程式使用下列程式碼:
using System;
using System.Collections.Generic;
namespace reducer
{
class Program
{
static void Main(string[] args)
{
//Dictionary for holding a count of words
Dictionary<string, int> words = new Dictionary<string, int>();
string line;
//Read from STDIN
while ((line = Console.ReadLine()) != null)
{
// Data from Hadoop is tab-delimited key/value pairs
var sArr = line.Split('\t');
// Get the word
string word = sArr[0];
// Get the count
int count = Convert.ToInt32(sArr[1]);
//Do we already have a count for the word?
if(words.ContainsKey(word))
{
//If so, increment the count
words[word] += count;
} else
{
//Add the key to the collection
words.Add(word, count);
}
}
//Finally, emit each word and count
foreach (var word in words)
{
//Emit tab-delimited key/value pairs.
//In this case, a word and a count of 1.
Console.WriteLine("{0}\t{1}", word.Key, word.Value);
}
}
}
}
在您建立應用程式之後,建置它以在專案目錄中產生 /bin/Debug/reducer.exe 檔案。
上傳至儲存體
接下來,您必須將對應工具和歸納器應用程式上傳至 HDInsight 儲存體。
在 [Visual Studio] 中,選取 [檢視]>[伺服器總管]。
以滑鼠右鍵按一下 [Azure],選取 [連線至 Microsoft Azure 訂用帳戶...],接著完成登入程序。
展開您要部署此應用程式的 HDInsight 叢集。 就會列出含有文字 (預設儲存體帳戶) 的項目。
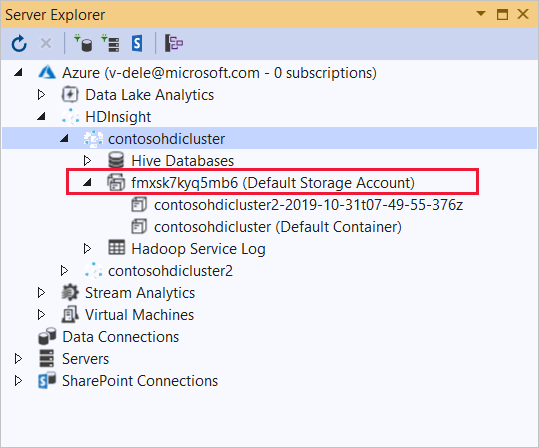
如果 [預設儲存體帳戶] 項目可以展開,表示您是使用 Azure 儲存體帳戶作為叢集的預設儲存體。 若要檢視叢集預設儲存體上的檔案,請展開項目,然後按兩下 [預設容器]。
如果 [預設儲存體帳戶] 項目可以展開,表示您是使用 Azure Data Lake Storage 作為叢集的預設儲存體。 若要檢視叢集之預設儲存體上的檔案,請按兩下 [(預設儲存體帳戶)] 項目。
若要上傳 .exe 檔案,請使用下列其中一種方法:
如果您使用 Azure 儲存體帳戶,請選取 [上傳 blob] 圖示。

在 [上傳新的檔案] 對話方塊的 [檔案名稱] 下,選取 [瀏覽]。 在 [上傳 Blob] 對話方塊中,移至 mapper 專案的 bin\debug 資料夾,接著選擇 mapper.exe 檔案。 最後,選取 [開啟],然後選取 [確定] 以完成上傳。
針對 Azure Data Lake Storage,請以滑鼠右鍵按一下檔案清單中的空白區域,然後選取 [上傳]。 最後,選取 mapper.exe 檔案,然後選取 [開啟]。
mapper.exe 上傳完成後,請針對 reducer.exe 檔案重複上傳程序。
執行工作︰使用 SSH 工作階段
下列程序描述如何使用 SSH 工作階段來執行 MapReduce 作業:
使用 ssh 命令來連線到您的叢集。 編輯以下命令並將 CLUSTERNAME 取代為您叢集的名稱,然後輸入命令:
ssh sshuser@CLUSTERNAME-ssh.azurehdinsight.net使用下列其中一個命令來啟動 MapReduce 作業:
如果預設儲存體是 Azure 儲存體:
yarn jar /usr/hdp/current/hadoop-mapreduce-client/hadoop-streaming.jar \ -files wasbs:///mapper.exe,wasbs:///reducer.exe \ -mapper mapper.exe \ -reducer reducer.exe \ -input /example/data/gutenberg/davinci.txt \ -output /example/wordcountout使用預設儲存體是 Data Lake Storage Gen1:
yarn jar /usr/hdp/current/hadoop-mapreduce-client/hadoop-streaming.jar \ -files adl:///mapper.exe,adl:///reducer.exe \ -mapper mapper.exe \ -reducer reducer.exe \ -input /example/data/gutenberg/davinci.txt \ -output /example/wordcountout使用預設儲存體是 Data Lake Storage Gen2:
yarn jar /usr/hdp/current/hadoop-mapreduce-client/hadoop-streaming.jar \ -files abfs:///mapper.exe,abfs:///reducer.exe \ -mapper mapper.exe \ -reducer reducer.exe \ -input /example/data/gutenberg/davinci.txt \ -output /example/wordcountout
下列清單描述每個參數和選項所代表的內容:
參數 描述 hadoop-streaming.jar 指定串流處理 MapReduce 功能的 jar 檔案。 -檔案 指定此作業的 mapper.exe 和 reducer.exe 檔案。 每個檔案前面的 wasbs:///、adl:///或abfs:///通訊協定通告都是叢集預設儲存體的根目錄路徑。-對應工具 指定檔案實作的對應工具。 -歸納器 指定檔案實作的歸納器。 -輸入 指定輸入資料。 -輸出 指定輸出目錄。 在 MapReduce 作業完成後,使用下列命令來檢視結果:
hdfs dfs -text /example/wordcountout/part-00000下列文字是此命令所傳回資料的範例︰
you 1128 young 38 younger 1 youngest 1 your 338 yours 4 yourself 34 yourselves 3 youth 17
執行作業:使用 PowerShell
使用下列 PowerShell 指令碼來執行 MapReduce 作業並下載結果。
# Login to your Azure subscription
$context = Get-AzContext
if ($context -eq $null)
{
Connect-AzAccount
}
$context
# Get HDInsight info
$clusterName = Read-Host -Prompt "Enter the HDInsight cluster name"
$creds=Get-Credential -Message "Enter the login for the cluster"
# Path for job output
$outputPath="/example/wordcountoutput"
# Progress indicator
$activity="C# MapReduce example"
Write-Progress -Activity $activity -Status "Getting cluster information..."
#Get HDInsight info so we can get the resource group, storage, etc.
$clusterInfo = Get-AzHDInsightCluster -ClusterName $clusterName
$resourceGroup = $clusterInfo.ResourceGroup
$storageActArr=$clusterInfo.DefaultStorageAccount.split('.')
$storageAccountName=$storageActArr[0]
$storageType=$storageActArr[1]
# Progress indicator
#Define the MapReduce job
# Note: using "/mapper.exe" and "/reducer.exe" looks in the root
# of default storage.
$jobDef=New-AzHDInsightStreamingMapReduceJobDefinition `
-Files "/mapper.exe","/reducer.exe" `
-Mapper "mapper.exe" `
-Reducer "reducer.exe" `
-InputPath "/example/data/gutenberg/davinci.txt" `
-OutputPath $outputPath
# Start the job
Write-Progress -Activity $activity -Status "Starting MapReduce job..."
$job=Start-AzHDInsightJob `
-ClusterName $clusterName `
-JobDefinition $jobDef `
-HttpCredential $creds
#Wait for the job to complete
Write-Progress -Activity $activity -Status "Waiting for the job to complete..."
Wait-AzHDInsightJob `
-ClusterName $clusterName `
-JobId $job.JobId `
-HttpCredential $creds
Write-Progress -Activity $activity -Completed
# Download the output
if($storageType -eq 'azuredatalakestore') {
# Azure Data Lake Store
# Fie path is the root of the HDInsight storage + $outputPath
$filePath=$clusterInfo.DefaultStorageRootPath + $outputPath + "/part-00000"
Export-AzDataLakeStoreItem `
-Account $storageAccountName `
-Path $filePath `
-Destination output.txt
} else {
# Az.Storage account
# Get the container
$container=$clusterInfo.DefaultStorageContainer
#NOTE: This assumes that the storage account is in the same resource
# group as HDInsight. If it is not, change the
# --ResourceGroupName parameter to the group that contains storage.
$storageAccountKey=(Get-AzStorageAccountKey `
-Name $storageAccountName `
-ResourceGroupName $resourceGroup)[0].Value
#Create a storage context
$context = New-AzStorageContext `
-StorageAccountName $storageAccountName `
-StorageAccountKey $storageAccountKey
# Download the file
Get-AzStorageBlobContent `
-Blob 'example/wordcountoutput/part-00000' `
-Container $container `
-Destination output.txt `
-Context $context
}
此指令碼會提示您輸入叢集登入帳戶名稱和密碼,以及 HDInsight 叢集名稱。 作業完成後,會將輸出下載到名為 output.txt 的檔案。 以下文字是 output.txt 檔案中的資料範例:
you 1128
young 38
younger 1
youngest 1
your 338
yours 4
yourself 34
yourselves 3
youth 17