教學課程:在 HDInsight 上搭配 Apache Kafka 使用 Apache Spark 結構化串流
本教學課程示範如何使用 Apache Spark 結構化串流,在 Azure HDInsight 上使用 Apache Kafka 讀取和寫入數據。
Spark 結構化串流是建置在Spark SQL上的串流處理引擎。 它可讓您在靜態數據上表示與批次計算相同的串流計算。
在本教學課程中,您會了解如何:
- 使用 Azure Resource Manager 樣本建立叢集
- 搭配 Kafka 使用 Spark 結構化串流
當您完成本檔中的步驟時,請記得刪除叢集以避免產生過多費用。
必要條件
jq,這是命令列 JSON 處理器。 請參閱 https://stedolan.github.io/jq/。
熟悉在 HDInsight 上搭配 Spark 使用 Jupyter Notebook 。 如需詳細資訊,請參閱 使用 HDInsight 上的 Apache Spark 載入數據和執行查詢檔。
熟悉 Scala 程式設計語言。 本教學課程中使用的程序代碼是以 Scala 撰寫。
熟悉建立 Kafka 主題。 如需詳細資訊,請參閱 HDInsight 上的 Apache Kafka 快速入門 檔。
重要
本檔中的步驟需要 Azure 資源群組,其中包含 HDInsight 上的 Spark 和 HDInsight 叢集上的 Kafka。 這些叢集都位於 Azure 虛擬網絡 內,可讓 Spark 叢集直接與 Kafka 叢集通訊。
為了方便起見,本文件會連結至可建立所有必要的 Azure 資源的範本。
如需在虛擬網路中使用 HDInsight 的詳細資訊,請參閱 規劃 HDInsight 的虛擬網路檔。
使用 Apache Kafka 進行結構化串流
Spark 結構化串流是建置在 Spark SQL 引擎上的串流處理引擎。 使用結構化串流時,您可以使用撰寫批次查詢的相同方式來撰寫串流查詢。
下列代碼段示範從 Kafka 讀取並儲存至檔案。 第一個是批次作業,而第二個作業是串流作業:
// Read a batch from Kafka
val kafkaDF = spark.read.format("kafka")
.option("kafka.bootstrap.servers", kafkaBrokers)
.option("subscribe", kafkaTopic)
.option("startingOffsets", "earliest")
.load()
// Select data and write to file
kafkaDF.select(from_json(col("value").cast("string"), schema) as "trip")
.write
.format("parquet")
.option("path","/example/batchtripdata")
.option("checkpointLocation", "/batchcheckpoint")
.save()
// Stream from Kafka
val kafkaStreamDF = spark.readStream.format("kafka")
.option("kafka.bootstrap.servers", kafkaBrokers)
.option("subscribe", kafkaTopic)
.option("startingOffsets", "earliest")
.load()
// Select data from the stream and write to file
kafkaStreamDF.select(from_json(col("value").cast("string"), schema) as "trip")
.writeStream
.format("parquet")
.option("path","/example/streamingtripdata")
.option("checkpointLocation", "/streamcheckpoint")
.start.awaitTermination(30000)
在這兩個代碼段中,數據會從 Kafka 讀取並寫入檔案。 範例之間的差異如下:
| Batch | 串流 |
|---|---|
read |
readStream |
write |
writeStream |
save |
start |
串流作業也會使用 awaitTermination(30000),這會在 30,000 毫秒後停止數據流。
若要搭配 Kafka 使用結構化串流,您的項目必須相依於 org.apache.spark : spark-sql-kafka-0-10_2.11 套件。 此套件的版本應該符合 HDInsight 上的 Spark 版本。 針對Spark 2.4 (適用於 HDInsight 4.0),您可以在 找到不同項目類型的 https://search.maven.org/#artifactdetails%7Corg.apache.spark%7Cspark-sql-kafka-0-10_2.11%7C2.2.0%7Cjar相依性資訊。
針對搭配本教學課程使用的 Jupyter Notebook,下列數據格會載入此套件相依性:
%%configure -f
{
"conf": {
"spark.jars.packages": "org.apache.spark:spark-sql-kafka-0-10_2.11:2.2.0",
"spark.jars.excludes": "org.scala-lang:scala-reflect,org.apache.spark:spark-tags_2.11"
}
}
建立叢集
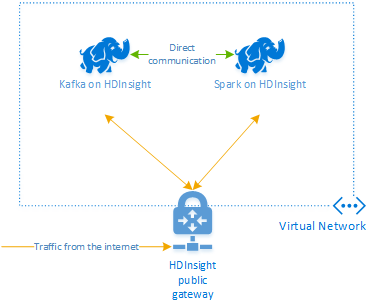
HDInsight 上的 Apache Kafka 無法透過公用因特網存取 Kafka 訊息代理程式。 使用 Kafka 的任何項目都必須位於相同的 Azure 虛擬網路中。 在本教學課程中,Kafka 和 Spark 叢集都位於相同的 Azure 虛擬網路中。
下圖顯示Spark與 Kafka 之間的通訊如何流動:
注意
Kafka 服務僅限於虛擬網路內的通訊。 叢集上的其他服務,例如 SSH 和 Ambari,可以透過因特網存取。 如需 HDInsight 可用公用埠的詳細資訊,請參閱 HDInsight 所使用的埠和 URI。
若要建立 Azure 虛擬網路,然後在其中建立 Kafka 和 Spark 叢集,請使用以下步驟:
使用下列按鈕登入 Azure,並在 Azure 入口網站 中開啟範本。

Azure Resource Manager 範本位於 https://raw.githubusercontent.com/Azure-Samples/hdinsight-spark-kafka-structured-streaming/master/azuredeploy.json。
此範本會建立下列資源︰
HDInsight 4.0 或 5.0 叢集上的 Kafka。
HDInsight 4.0 或 5.0 叢集上的 Spark 2.4 或 3.1。
Azure 虛擬網路,其中包含 HDInsight 叢集。
重要
本教學課程中使用的結構化串流筆記本需要 HDInsight 4.0 或 5.0 上的 Spark 2.4 或 3.1。 如果您在 HDInsight 上使用舊版 Spark,當您使用筆記本時會收到錯誤。
使用以下資訊填入 [自訂範本] 區段中的項木:
設定 值 訂用帳戶 您的 Azure 訂用帳戶 資源群組 包含資源的資源群組。 Location 資源建立的 Azure 區域。 Spark 叢集名稱 Spark 叢集的名稱。 前六個字元必須與 Kafka 叢集名稱不同。 Kafka 叢集名稱 Kafka 叢集的名稱。 前六個字元必須與 Spark 叢集名稱不同。 叢集登入使用者名稱 叢集的管理員用戶名稱。 叢集登入密碼 叢集的系統管理員用戶密碼。 SSH 使用者名稱 要為叢集建立的SSH使用者。 SSH 密碼 SSH 使用者的密碼。 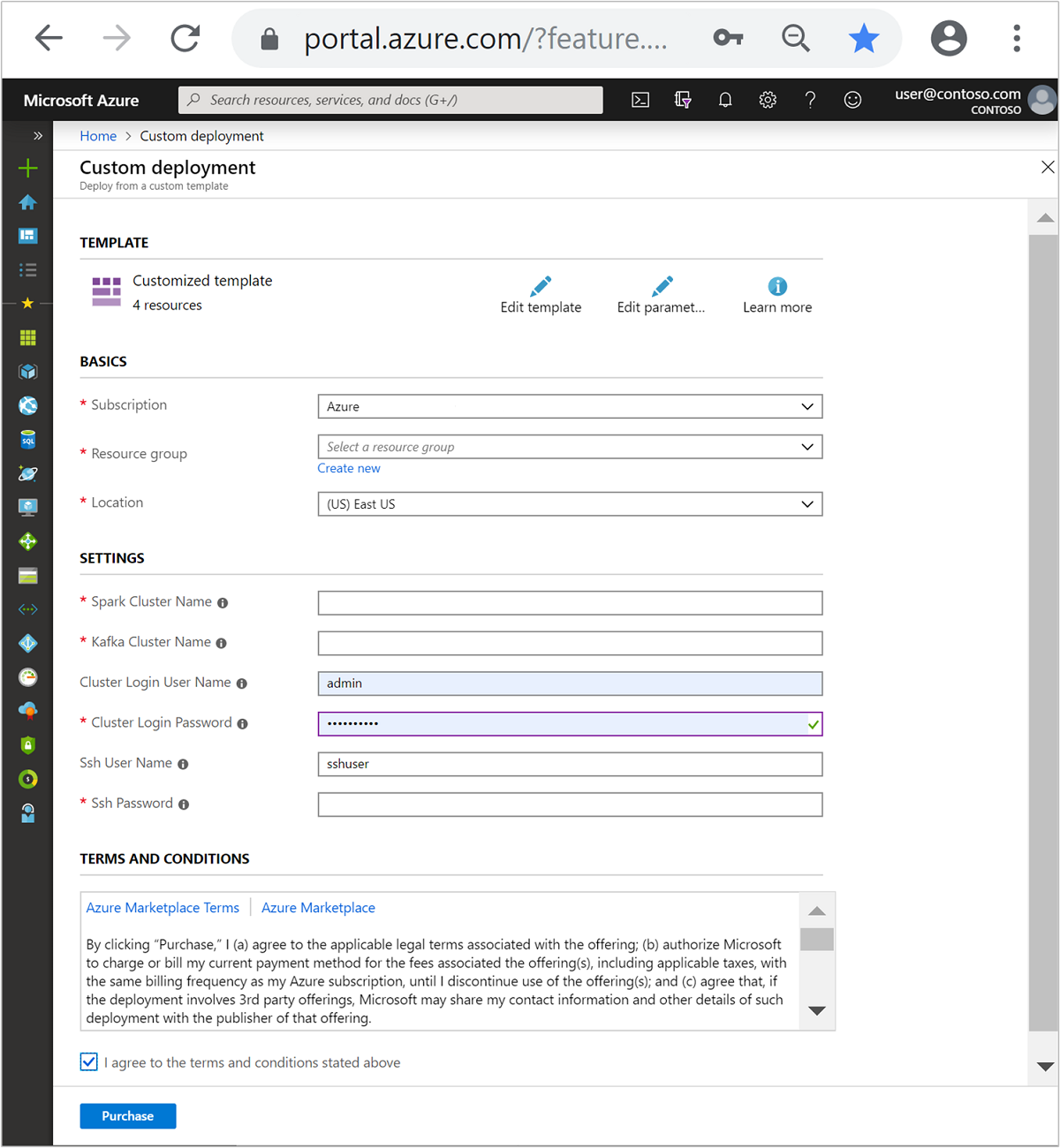
閱讀條款 及條件,然後選取 [我同意上述條款及條件]。
選取 [購買] 。
注意
建立叢集最多可能需要 20 分鐘的時間。
使用Spark結構化串流
此範例示範如何使用 Spark 結構化串流搭配 HDInsight 上的 Kafka。 它會使用紐約市提供的計程車車程數據。 此筆記本所使用的數據集來自 2016 年綠色計程車車程數據。
收集主機資訊。 使用下面的 curl 和 jq 命令來取得 Kafka ZooKeeper 和訊息代理程式主機資訊。 這些命令是針對 Windows 命令提示字元所設計,其他環境需要稍微變化。
KafkaCluster取代為 Kafka 叢集的名稱,並以KafkaPassword叢集登入密碼取代 。 此外,請將 取代C:\HDI\jq-win64.exe為您 jq 安裝的實際路徑。 在 Windows 命令提示字元中輸入命令,並儲存輸出以供後續步驟使用。REM Enter cluster name in lowercase set CLUSTERNAME=KafkaCluster set PASSWORD=KafkaPassword curl -u admin:%PASSWORD% -G "https://%CLUSTERNAME%.azurehdinsight.net/api/v1/clusters/%CLUSTERNAME%/services/ZOOKEEPER/components/ZOOKEEPER_SERVER" | C:\HDI\jq-win64.exe -r "["""\(.host_components[].HostRoles.host_name):2181"""] | join(""",""")" curl -u admin:%PASSWORD% -G "https://%CLUSTERNAME%.azurehdinsight.net/api/v1/clusters/%CLUSTERNAME%/services/KAFKA/components/KAFKA_BROKER" | C:\HDI\jq-win64.exe -r "["""\(.host_components[].HostRoles.host_name):9092"""] | join(""",""")"從網頁瀏覽器瀏覽至
https://CLUSTERNAME.azurehdinsight.net/jupyter,其中CLUSTERNAME是叢集的名稱。 出現提示時,請輸入您在建立叢集時所使用的叢集登入 (admin) 和密碼。選取 [新增 > Spark ] 以建立筆記本。
Spark 串流具有 microbatching,這表示數據會在批次和執行程式在數據批次上執行。 如果執行程式閑置逾時少於處理批次所需的時間,則執行程式會持續新增和移除。 如果執行程式閑置逾時大於批次持續時間,則執行程序永遠不會移除。 因此 ,建議您在執行串流應用程式時,將spark.dynamicAllocation.enabled 設定為 false,以停用動態配置。
在 Notebook 數據格中輸入下列資訊,以載入 Notebook 所使用的套件。 使用 CTRL + ENTER 執行命令。
%%configure -f { "conf": { "spark.jars.packages": "org.apache.spark:spark-sql-kafka-0-10_2.11:2.2.0", "spark.jars.excludes": "org.scala-lang:scala-reflect,org.apache.spark:spark-tags_2.11", "spark.dynamicAllocation.enabled": false } }建立 Kafka 主題。 將 取代
YOUR_ZOOKEEPER_HOSTS為在第一個步驟中擷取的 Zookeeper 主機資訊,以編輯下列命令。 在 Jupyter Notebook 中輸入已編輯的命令,以建立tripdata主題。%%bash export KafkaZookeepers="YOUR_ZOOKEEPER_HOSTS" /usr/hdp/current/kafka-broker/bin/kafka-topics.sh --create --replication-factor 3 --partitions 8 --topic tripdata --zookeeper $KafkaZookeepers擷取計程車車程的數據。 在下一個數據格中輸入 命令,以載入紐約市計程車車程的數據。 數據會載入資料框架,然後數據框架會顯示為資料格輸出。
import spark.implicits._ // Load the data from the New York City Taxi data REST API for 2016 Green Taxi Trip Data val url="https://data.cityofnewyork.us/resource/pqfs-mqru.json" val result = scala.io.Source.fromURL(url).mkString // Create a dataframe from the JSON data val taxiDF = spark.read.json(Seq(result).toDS) // Display the dataframe containing trip data taxiDF.show()設定 Kafka 訊息代理程式主機資訊。 將 取代
YOUR_KAFKA_BROKER_HOSTS為您在步驟 1 中擷取的訊息代理程式主機資訊。 在下一個 Jupyter Notebook 數據格中輸入已編輯的命令。// The Kafka broker hosts and topic used to write to Kafka val kafkaBrokers="YOUR_KAFKA_BROKER_HOSTS" val kafkaTopic="tripdata" println("Finished setting Kafka broker and topic configuration.")將數據傳送至 Kafka。 在下列命令中
vendorid,欄位會當做 Kafka 訊息的索引鍵值使用。 分割數據時,Kafka 會使用索引鍵。 所有欄位都會儲存在 Kafka 訊息中,做為 JSON 字串值。 在 Jupyter 中輸入下列命令,以使用批次查詢將資料儲存至 Kafka。// Select the vendorid as the key and save the JSON string as the value. val query = taxiDF.selectExpr("CAST(vendorid AS STRING) as key", "to_JSON(struct(*)) AS value").write.format("kafka").option("kafka.bootstrap.servers", kafkaBrokers).option("topic", kafkaTopic).save() println("Data sent to Kafka")宣告架構。 下列命令示範如何從 kafka 讀取 JSON 數據時使用架構。 在下一個 Jupyter 單元格中輸入 命令。
// Import bits useed for declaring schemas and working with JSON data import org.apache.spark.sql._ import org.apache.spark.sql.types._ import org.apache.spark.sql.functions._ // Define a schema for the data val schema = (new StructType).add("dropoff_latitude", StringType).add("dropoff_longitude", StringType).add("extra", StringType).add("fare_amount", StringType).add("improvement_surcharge", StringType).add("lpep_dropoff_datetime", StringType).add("lpep_pickup_datetime", StringType).add("mta_tax", StringType).add("passenger_count", StringType).add("payment_type", StringType).add("pickup_latitude", StringType).add("pickup_longitude", StringType).add("ratecodeid", StringType).add("store_and_fwd_flag", StringType).add("tip_amount", StringType).add("tolls_amount", StringType).add("total_amount", StringType).add("trip_distance", StringType).add("trip_type", StringType).add("vendorid", StringType) // Reproduced here for readability //val schema = (new StructType) // .add("dropoff_latitude", StringType) // .add("dropoff_longitude", StringType) // .add("extra", StringType) // .add("fare_amount", StringType) // .add("improvement_surcharge", StringType) // .add("lpep_dropoff_datetime", StringType) // .add("lpep_pickup_datetime", StringType) // .add("mta_tax", StringType) // .add("passenger_count", StringType) // .add("payment_type", StringType) // .add("pickup_latitude", StringType) // .add("pickup_longitude", StringType) // .add("ratecodeid", StringType) // .add("store_and_fwd_flag", StringType) // .add("tip_amount", StringType) // .add("tolls_amount", StringType) // .add("total_amount", StringType) // .add("trip_distance", StringType) // .add("trip_type", StringType) // .add("vendorid", StringType) println("Schema declared")選取數據並啟動數據流。 下列命令示範如何使用批次查詢從 Kafka 擷取數據。 然後將結果寫出至 Spark 叢集上的 HDFS。 在此範例中,會
select從 Kafka 擷取訊息(值欄位),並將架構套用至該訊息。 然後,數據會以 parquet 格式寫入 HDFS (WASB 或 ADL)。 在下一個 Jupyter 單元格中輸入 命令。// Read a batch from Kafka val kafkaDF = spark.read.format("kafka").option("kafka.bootstrap.servers", kafkaBrokers).option("subscribe", kafkaTopic).option("startingOffsets", "earliest").load() // Select data and write to file val query = kafkaDF.select(from_json(col("value").cast("string"), schema) as "trip").write.format("parquet").option("path","/example/batchtripdata").option("checkpointLocation", "/batchcheckpoint").save() println("Wrote data to file")您可以在下一個 Jupyter 單元格中輸入 命令,以確認檔案是否已建立。 它會列出目錄中的
/example/batchtripdata檔案。%%bash hdfs dfs -ls /example/batchtripdata雖然上一個範例使用批次查詢,但下列命令示範如何使用串流查詢來執行相同動作。 在下一個 Jupyter 單元格中輸入 命令。
// Stream from Kafka val kafkaStreamDF = spark.readStream.format("kafka").option("kafka.bootstrap.servers", kafkaBrokers).option("subscribe", kafkaTopic).option("startingOffsets", "earliest").load() // Select data from the stream and write to file kafkaStreamDF.select(from_json(col("value").cast("string"), schema) as "trip").writeStream.format("parquet").option("path","/example/streamingtripdata").option("checkpointLocation", "/streamcheckpoint").start.awaitTermination(30000) println("Wrote data to file")執行下列數據格,以確認檔案是由串流查詢所撰寫。
%%bash hdfs dfs -ls /example/streamingtripdata
清除資源
若要清除本教學課程所建立的資源,您可以刪除資源群組。 刪除資源群組也會刪除相關聯的 HDInsight 叢集。 以及與資源群組相關聯的任何其他資源。
若要使用 Azure 入口網站 移除資源群組:
- 在 Azure 入口網站 中,展開左側的功能表以開啟服務的功能表,然後選擇 [資源群組] 以顯示資源群組的清單。
- 找出要刪除的資源群組,然後在列表右側的 [更多] 按鈕 (...) 上按下滑鼠右鍵。
- 選取 [ 刪除資源群組],然後確認。
警告
HDInsight 叢集計費會在叢集建立後啟動,並在刪除叢集時停止。 計費是以每分鐘按比例計算,因此不再使用時,請一律刪除您的叢集。
刪除 HDInsight 叢集上的 Kafka 會刪除儲存在 Kafka 中的任何數據。
意見反應
即將登場:在 2024 年,我們將逐步淘汰 GitHub 問題作為內容的意見反應機制,並將它取代為新的意見反應系統。 如需詳細資訊,請參閱:https://aka.ms/ContentUserFeedback。
提交並檢視相關的意見反應