向量索引大小並維持不超過限制
針對每個向量欄位,Azure AI 搜尋使用欄位指定的演算法參數建構內部向量索引。 Azure AI 搜尋對向量索引大小施加配額,因此您應該要了解如何估計和監視向量大小,確保您不超過限制。
注意
關於術語的附註。 在內部,搜尋索引的實體資料結構包括原始內 (用於需要非權杖化內容的擷取模式)、反向索引 (用於可搜尋的文字欄位),以及向量索引 (用於可搜尋的向量欄位)。 本文說明支援每個向量欄位的內部向量索引限制。
提示
向量量化和儲存體設定目前為預覽版。 使用縮小資料類型、純量量化和消除備援儲存體等功能,維持不超過向量配額和記憶體配額。
配額和向量索引大小的要點
向量索引大小以位元組為單位測量。
向量配額以記憶體條件約束為基礎。 所有可搜尋的向量索引都必須載入記憶體。 同時,其他執行階段作業也必須有足夠的記憶體。 向量配額存在,為的是確保整體系統針對所有工作負載維持穩定平衡。
向量索引也受限於磁碟配額,也就是說,所有索引都受限於磁碟配額。 向量索引沒有個別的磁碟配額。
向量配額以整體方式按分割區在搜尋服務強制執行,這表示如果您新增分割區,向量配額就會增加。 新服務每個分割區的向量配額較高:
如何檢查分割區大小和數量
如果您不確定搜尋服務限制為何,以下是取得該資訊的兩種方式:
在 Microsoft Azure 入口網站的 [搜尋服務] [概觀] 頁面中,[屬性] 索引標籤和 [使用量] 索引標籤會顯示分割區大小和記憶體,以及向量配額和向量索引大小。
在 Microsoft Azure 入口網站的 [縮放] 頁面,您可以檢閱分割區的數目和大小。
如何檢查服務建立日期
2024 年 4 月 3 日之後建立的服務比較新,相較於以相同階層計費費率提供的舊版服務,提供 5 到 10 倍以上的向量記憶體。 如果您的服務較舊,請考慮建立新服務並移轉內容。
在 Microsoft Azure 入口網站,開啟包含搜尋服務的資源群組。
在左導覽窗格的 [設定] 下,選取 [部署]。
找出您的搜尋服務部署。 如果有許多部署,請使用篩選條件來尋找 "search"。
選取部署。 若有多個,請按一下以查看其是否解析為您的搜尋服務。
展開部署詳細資料。 您應該會看到「已建立」和建立日期。
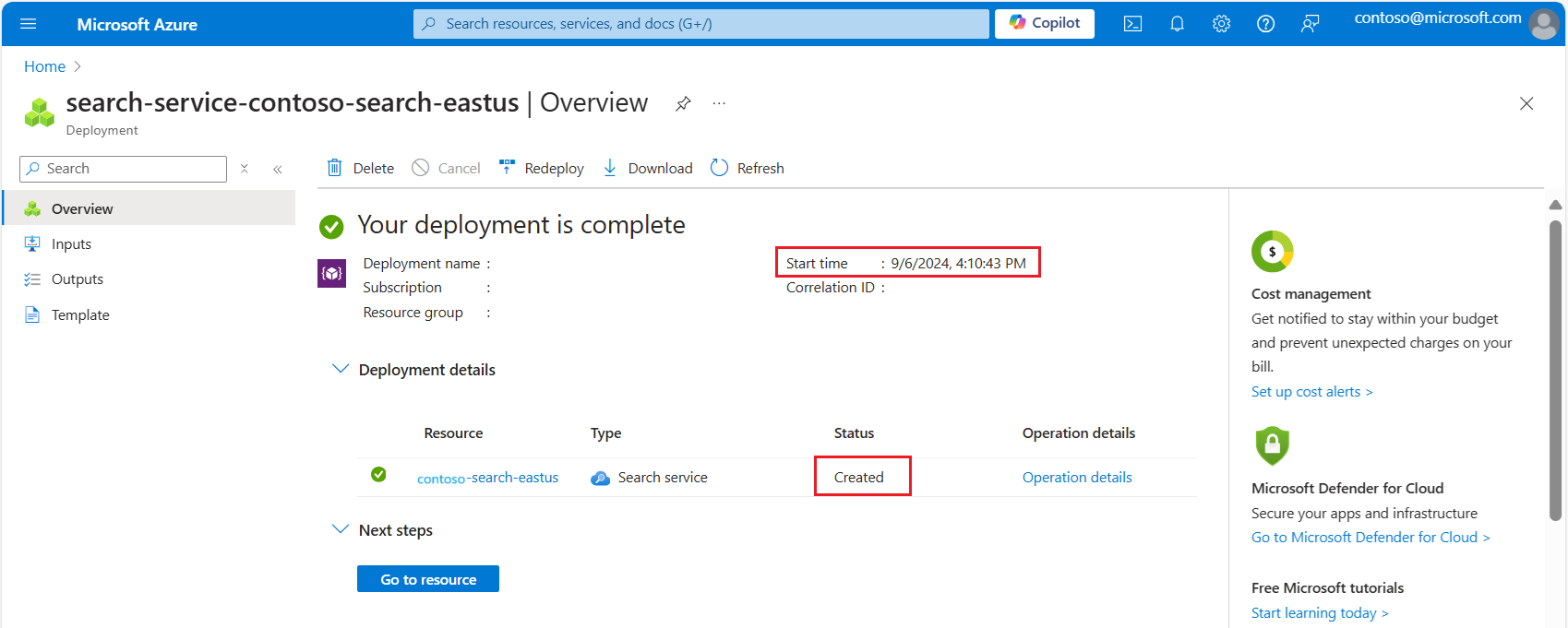
既然您知道搜尋服務的存留期,請根據服務建立日期來檢閱向量配額限制:
如何取得向量索引大小
向量計量的要求是資料平面作業。 您可以使用 Azure 入口網站、REST API 或 Azure SDK,透過服務統計資料和個別索引,取得服務層級的向量使用量。
您可以在 [概觀] 頁面的 [使用量] 索引標籤中找到使用量資訊。入口網站頁面每隔幾分鐘重新整理一次,因此,如果您最近更新了索引,請先稍候一下再檢查結果。
下列螢幕擷取畫面適用於,針對一個分割區和一個複本設定的較舊標準 1 (S1) 搜尋服務。
- 記憶體配額是磁碟條件約束,包含搜尋服務的所有索引 (向量和非向量)。
- 向量索引大小配額是記憶體條件約束。 這是載入針對搜尋服務上每個向量欄位所建立之所有內部向量索引所需的記憶體量。
螢幕擷取畫面顯示索引 (向量和非向量) 耗用近 460 MB 的可用磁碟記憶體。 向量索引在服務層級耗用近 93 MB 的記憶體。
![[概觀] 頁面使用量索引標籤的螢幕擷取畫面,顯示相較於配額的向量索引耗用量。](media/vector-search-index-size/portal-vector-index-size.png#lightbox)
新增或移除分割區時,記憶體和向量索引大小的配額都會增加或減少。 如果變更分割區計數,圖格會顯示記憶體和向量配額相應的變更。
注意
在磁碟上,向量索引不是 93 MB。 磁碟上的向量索引比記憶體中的向量索引多三倍。 如需詳細資料,請參閱向量欄位如何影響磁碟儲存體。
影響向量索引大小的因素
有三個主要元件會影響內部向量索引的大小:
- 資料的原始大小
- 所選演算法的額外負荷
- 刪除或更新索引內文件的額外負荷
資料的原始大小
每個向量都是單精確度浮點數的陣列,以類型 Collection(Edm.Single) 的欄位表示。
向量資料結構需要儲存體,在下列計算中以資料的「原始大小」表示。 使用此「原始大小」來估計向量欄位的向量索引大小需求。
一個向量的儲存大小取決於其維度。 請將一個向量的大小乘以包含該向量欄位的文件數目,以取得「原始大小」:
raw size = (number of documents) * (dimensions of vector field) * (size of data type)
| EDM 資料類型 | 資料類型的大小 |
|---|---|
Collection(Edm.Single) |
4 個位元組 |
Collection(Edm.Half) |
2 個位元組 |
Collection(Edm.Int16) |
2 個位元組 |
Collection(Edm.SByte) |
1 個位元組 |
所選演算法的記憶體額外負荷
每個近似最接近像素 (ANN) 演算法都會在記憶體中產生額外的資料結構,以啟用有效率的搜尋。 這些結構會耗用記憶體內的額外空間。
針對 HNSW 演算法,記憶體額外負荷範圍介於 1% 與 20% 之間。
較高維度的記憶體額外負荷較低,因為向量的原始大小會增加,而額外資料結構會維持固定大小,因為其會儲存圖形內連線的相關資訊。 因此,額外資料結構的貢獻構成整體大小的一小部分。
對於較大的 HNSW 參數 m 值,記憶體額外負荷較高,這會決定在索引建構期間為每個新向量建立的雙向連結數目。 這是因為 m 影響每份文件大約 8 到 10 個位元組乘以 m。
下表摘要說明內部測試中觀察到的額外負荷百分比:
| 維度 | HNSW 參數 (m) | 額外負荷百分比 |
|---|---|---|
| 96 | 4 | 20% |
| 200 | 4 | 8% |
| 768 | 4 | 2% |
| 1536 | 4 | %1 |
| 3072 | 4 | 0.5% |
這些結果示範 HNSW 演算法的維度、HNSW 參數 m 和記憶體額外負荷之間的關聯性。
刪除或更新索引內文件的額外負荷
刪除或更新具有向量欄位的文件時 (更新會在內部以刪除和插入作業表示),基礎文件會在後續查詢期間標示為已刪除和已略過。 當新文件編製索引且內部向量索引增長時,系統會清除這些已刪除的文件並回收資源。 這表示您可能會觀察到刪除文件與釋放基礎資源之間有延遲的情形。
我們將這稱為已刪除的文件比例。 由於已刪除的文件比率取決於您服務的索引編製特性,因此沒有通用啟發學習法來估計此參數,而且沒有 API 或指令碼傳回服務的有效比率。 我們觀察到一半的客戶具有小於 10% 的已刪除文件比率。 如果您傾向於執行高頻率刪除或更新,則可能會觀察到較高的已刪除文件比率。
這是影響向量索引大小的另一個因素。 不幸的是,我們沒有一種機制可呈現目前刪除的文件比率。
估計記憶體中的資料大小總計
將先前描述的因素納入考慮,若要估計向量索引的總大小,請使用下列計算方式:
(raw_size) * (1 + algorithm_overhead (in percent)) * (1 + deleted_docs_ratio (in percent))
例如,若要計算 raw_size,假設您使用熱門的 Azure OpenAI 模型,text-embedding-ada-002 具有 1,536 個維度。 這表示一份文件將會取用 1,536 個 Edm.Single (浮點數),或 6,144 個位元組,因為每個 Edm.Single 為 4 個位元組。 1,000 份具有單一、1,536 維度向量欄位的文件,總共會取用 1000 份文件 x 1536 個浮點數/文件 = 1,536,000 個浮點數,或 6,144,000 個位元組。
如果您有多個向量欄位,則必須針對索引內的每個向量欄位執行此計算,並將其全部加在一起。 例如,1,000 份具有兩個 1,536 維度向量欄位的文件,取用 1000 份文件 x 2 個欄位 x 1536 個浮點數/文件 x 4 位元組/浮點數 = 12,288,000 個位元組。
若要取得向量索引大小,請將這個 raw_size 乘以 演算法額外負荷和已刪除的文件比率。 如果所選 HNSW 參數的演算法額外負荷為 10%,且已刪除的文件比率為 10%,則我們會取得:6.144 MB * (1 + 0.10) * (1 + 0.10) = 7.434 MB。
向量欄位如何影響磁碟儲存體
本文多半提供記憶體向量大小的相關資訊。 如果您想知道磁碟上的向量大小,向量資料的磁碟耗用量大約是記憶體中向量索引大小的三倍。 例如,如果您的 vectorIndexSize 使用量為 100 MB (1000 萬位元組),則您至少已使用 300 MB 的 storageSize 配額因應向量索引。
意見反應
即將登場:在 2024 年,我們將逐步淘汰 GitHub 問題作為內容的意見反應機制,並將它取代為新的意見反應系統。 如需詳細資訊,請參閱:https://aka.ms/ContentUserFeedback。
提交並檢視相關的意見反應