Azure Synapse Studio 小組在 Microsoft Spark 公用程式 (mssparkutils) 套件中建置了兩個新的掛接/卸除 API。 您可以使用這些 API 將遠端記憶體(Azure Blob 儲存體 或 Azure Data Lake Storage Gen2)連結至所有工作節點(驅動程序節點和背景工作節點)。 記憶體就緒之後,您可以使用本機檔案 API 來存取數據,就像儲存在本機檔系統中一樣。 如需詳細資訊,請參閱 Spark公用程式Microsoft簡介。
本文說明如何在工作區中使用掛接/卸除 API。 您將了解:
- 如何掛接 Data Lake Storage Gen2 或 Blob 記憶體。
- 如何透過本機文件系統 API 存取裝入點下的檔案。
- 如何使用 API 存取裝入點
mssparkutils fs下的檔案。 - 如何使用 Spark 讀取 API 存取裝入點下的檔案。
- 如何卸除裝入點。
警告
暫時停用 Azure 檔案共用掛接。 您可以改用 Data Lake Storage Gen2 或 Azure Blob 儲存體 掛接,如下一節所述。
不支援 Azure Data Lake Storage Gen1 記憶體。 您可以遵循 Azure Data Lake Storage Gen1 至 Gen2 移轉指引 ,再使用掛接 API,遷移至 Data Lake Storage Gen2。
掛接儲存體
本節說明如何逐步掛接 Data Lake Storage Gen2 作為範例。 裝載 Blob 儲存體的運作方式類似。
此範例假設您有一個名為的 Data Lake Storage Gen2 帳戶 storegen2。 帳戶有一個名為 的容器,您想要在Spark集區中掛接至/test該容器mycontainer。
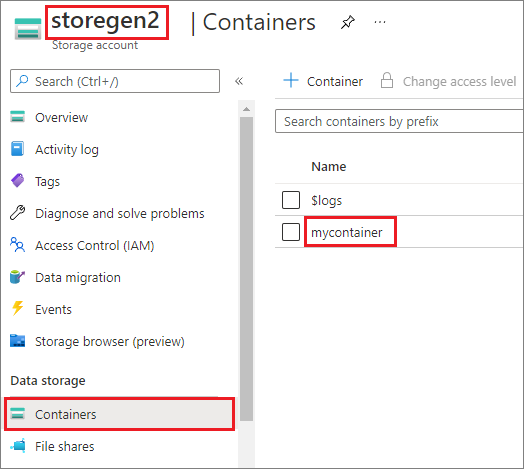
若要掛接名為 mycontainer的容器, mssparkutils 首先必須檢查您是否具有存取容器的許可權。 目前,Azure Synapse Analytics 支援三種觸發程式掛接作業的驗證方法: linkedService、 accountKey和 sastoken。
使用連結服務掛接 (建議)
我們建議透過連結服務掛接觸發程式。 此方法可避免安全性外泄,因為 mssparkutils 不會儲存任何秘密或驗證值本身。 相反地, mssparkutils 一律從鏈接服務擷取驗證值,以向遠端記憶體要求 Blob 數據。
您可以建立 Data Lake Storage Gen2 或 Blob 記憶體的連結服務。 目前,當您建立連結服務時,Azure Synapse Analytics 支援兩種驗證方法:
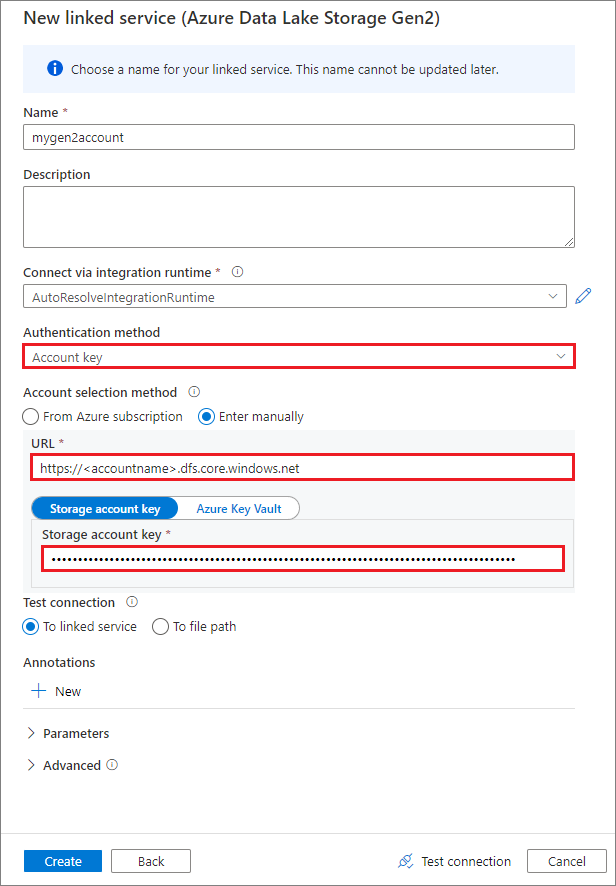
使用帳戶金鑰建立連結服務
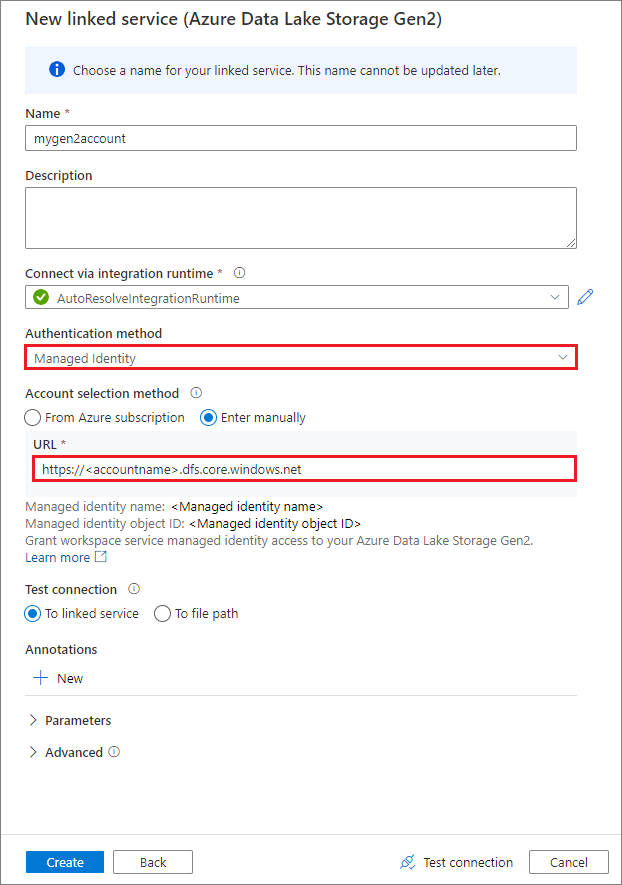
使用系統指派的受控識別建立連結服務
重要
- 如果上述建立的連結服務與 Azure Data Lake Storage Gen2 使用受控私人端點(含 dfs URI),則我們需要使用 Azure Blob 儲存體 選項建立另一個次要受控私人端點(搭配 blob URI),以確保內部 fsspec/adlfs 程式代碼可以使用 BlobServiceClient 接口聯機。
- 如果次要受控私人端點未正確設定,則會看到類似 ServiceRequestError 的錯誤訊息:無法連線到主機 [storageaccountname].blob.core.windows.net:443 ssl:True [名稱或服務未知]
注意
如果您使用受控識別作為驗證方法來建立連結服務,請確定工作區 MSI 檔案具有掛接容器的記憶體 Blob 數據參與者角色。
成功建立連結服務之後,您可以使用下列 Python 程式代碼,輕鬆地將容器掛接至 Spark 集區:
mssparkutils.fs.mount(
"abfss://mycontainer@<accountname>.dfs.core.windows.net",
"/test",
{"linkedService": "mygen2account"}
)
注意
如果無法使用,您可能需要匯入 mssparkutils:
from notebookutils import mssparkutils
無論您使用哪一種驗證方法,我們不建議您掛接根資料夾。
裝載參數:
- fileCacheTimeout: Blobs 預設會在本機暫存資料夾中快取 120 秒。 在此期間,blobfuse 不會檢查檔案是否為最新狀態。 參數可以設定為變更預設逾時時間。 當多個用戶端同時修改檔案時,為了避免本機和遠端檔案之間的不一致,建議您縮短快取時間,甚至將其變更為 0,並且一律從伺服器取得最新的檔案。
- timeout:裝載作業逾時預設為120秒。 參數可以設定為變更預設逾時時間。 當執行程式太多或掛接逾時時,建議增加值。
- scope:scope 參數是用來指定掛接的範圍。 預設值為 「job」。如果範圍設定為 「作業」,則只有目前的叢集才能看到掛接。 如果範圍設定為「工作區」,則目前工作區中的所有筆記本都可以看到掛接,如果不存在,就會自動建立裝入點。 將相同的參數新增至卸除 API 以取消掛接裝入點。 僅支援連結服務驗證的工作區層級掛接。
您可以使用這些參數,如下所示:
mssparkutils.fs.mount(
"abfss://mycontainer@<accountname>.dfs.core.windows.net",
"/test",
{"linkedService":"mygen2account", "fileCacheTimeout": 120, "timeout": 120}
)
透過共用存取簽章權杖或帳戶密鑰裝載
除了透過連結服務掛接, mssparkutils 還支援明確傳遞帳戶密鑰或 共用存取簽章 (SAS) 令牌作為掛接目標的參數。
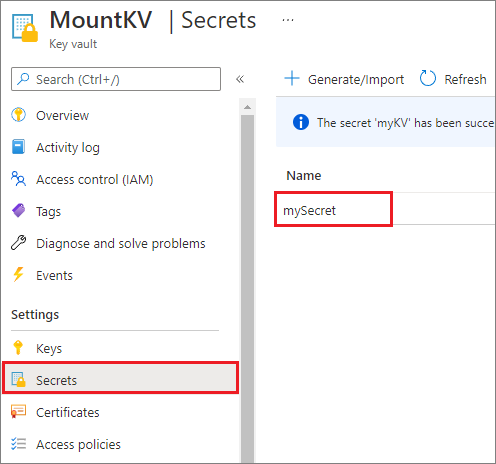
基於安全性考慮,我們建議您將帳戶密鑰或 SAS 令牌儲存在 Azure 金鑰保存庫 中(如下列範例螢幕快照所示)。 接著,您可以使用 API 來擷取它們 mssparkutil.credentials.getSecret 。 如需詳細資訊,請參閱使用 金鑰保存庫 和 Azure CLI 管理記憶體帳戶金鑰(舊版)。
以下是範例程式碼:
from notebookutils import mssparkutils
accountKey = mssparkutils.credentials.getSecret("MountKV","mySecret")
mssparkutils.fs.mount(
"abfss://mycontainer@<accountname>.dfs.core.windows.net",
"/test",
{"accountKey":accountKey}
)
注意
基於安全性考慮,請勿將認證儲存在程序代碼中。
使用 mssparkutils fs API 存取裝入點下的檔案
掛接作業的主要目的是讓客戶使用本機文件系統 API 來存取儲存在遠端記憶體帳戶中的數據。 您也可以使用 mssparkutils fs API 搭配掛接路徑做為參數來存取數據。 這裡使用的路徑格式稍有不同。
假設您已使用掛接 API 將 Data Lake Storage Gen2 容器 mycontainer 掛接至 /test。 透過本機檔案系統 API 存取資料時:
- 對於小於或等於 3.3 的 Spark 版本,路徑格式為
/synfs/{jobId}/test/{filename}。 - 對於大於或等於 3.4 的 Spark 版本,路徑格式為
/synfs/notebook/{jobId}/test/{filename}。
我們建議使用 mssparkutils.fs.getMountPath() 來取得正確的路徑:
path = mssparkutils.fs.getMountPath("/test")
注意
當您使用 workspace 範圍掛接記憶體時,裝入點會在資料夾下 /synfs/workspace 建立。 您需要使用 mssparkutils.fs.getMountPath("/test", "workspace") 來取得正確的路徑。
當您想要使用 mssparkutils fs API 存取資料時,路徑格式如下所示: synfs:/notebook/{jobId}/test/{filename}。 在此案例中,您可以看到 synfs 這是用來作為架構,而不是掛接路徑的一部分。 當然,您也可以使用本機文件系統架構來存取數據。 例如: file:/synfs/notebook/{jobId}/test/{filename} 。
下列三個範例示範如何使用 存取具有裝入點路徑 mssparkutils fs的檔案。
列出目錄:
mssparkutils.fs.ls(f'file:{mssparkutils.fs.getMountPath("/test")}')讀取檔案內容:
mssparkutils.fs.head(f'file:{mssparkutils.fs.getMountPath("/test")}/myFile.csv')建立目錄:
mssparkutils.fs.mkdirs(f'file:{mssparkutils.fs.getMountPath("/test")}/myDir')
使用 Spark 讀取 API 存取裝入點下的檔案
您可以提供參數,以透過Spark讀取API存取數據。 當您使用 mssparkutils fs API 時,這裡的路徑格式會相同。
從掛接的 Data Lake Storage Gen2 儲存器帳戶讀取檔案
下列範例假設 Data Lake Storage Gen2 儲存器帳戶已經掛接,然後使用掛接路徑讀取檔案:
%%pyspark
df = spark.read.load(f'file:{mssparkutils.fs.getMountPath("/test")}/myFile.csv', format='csv')
df.show()
注意
當您使用連結服務掛接記憶體時,應該一律先明確設定 spark 連結服務組態,再使用 synfs 架構來存取數據。 如需詳細資訊,請參閱具有連結服務的 ADLS Gen2 記憶體。
從掛接的 Blob 記憶體帳戶讀取檔案
如果您掛接 Blob 儲存器帳戶並想要使用 mssparkutils 或 Spark API 存取它,您必須先透過 Spark 設定明確設定 SAS 令牌,再嘗試使用掛接 API 掛接容器:
若要在觸發程式掛接之後使用
mssparkutils或Spark API存取 Blob 記憶體帳戶,請更新Spark組態,如下列程式代碼範例所示。 如果您想要只在掛接之後使用本機檔案 API 來存取 Spark 組態,則可以略過此步驟。blob_sas_token = mssparkutils.credentials.getConnectionStringOrCreds("myblobstorageaccount") spark.conf.set('fs.azure.sas.mycontainer.<blobStorageAccountName>.blob.core.windows.net', blob_sas_token)建立連結服務 ,並使用連結的服務
myblobstorageaccount掛接 Blob 記憶體帳戶:%%spark mssparkutils.fs.mount( "wasbs://mycontainer@<blobStorageAccountName>.blob.core.windows.net", "/test", Map("linkedService" -> "myblobstorageaccount") )掛接 Blob 記憶體容器,然後使用透過本機檔案 API 的掛接路徑讀取檔案:
# mount the Blob Storage container, and then read the file by using a mount path with open(mssparkutils.fs.getMountPath("/test") + "/myFile.txt") as f: print(f.read())透過 Spark 讀取 API 從掛接的 Blob 記憶體容器讀取資料:
%%spark // mount blob storage container and then read file using mount path val df = spark.read.text(f'file:{mssparkutils.fs.getMountPath("/test")}/myFile.txt') df.show()
卸載入點
使用下列程式代碼來卸載入點(/test 在此範例中為):
mssparkutils.fs.unmount("/test")
已知的限制
卸除機制不是自動的。 當應用程式執行完成時,若要卸載裝入點以釋放磁碟空間,您必須在程式代碼中明確呼叫卸除 API。 否則,在應用程式執行完成之後,裝載點仍會存在於節點中。
目前不支援掛接 Data Lake Storage Gen1 儲存器帳戶。