此功能提要提供實用的秘訣和最佳做法,協助您建立專用 SQL 集區 (先前稱為 SQL DW) 解決方案。
下圖顯示使用專用 SQL 集區 (先前稱為 SQL DW) 設計資料倉儲的程序:
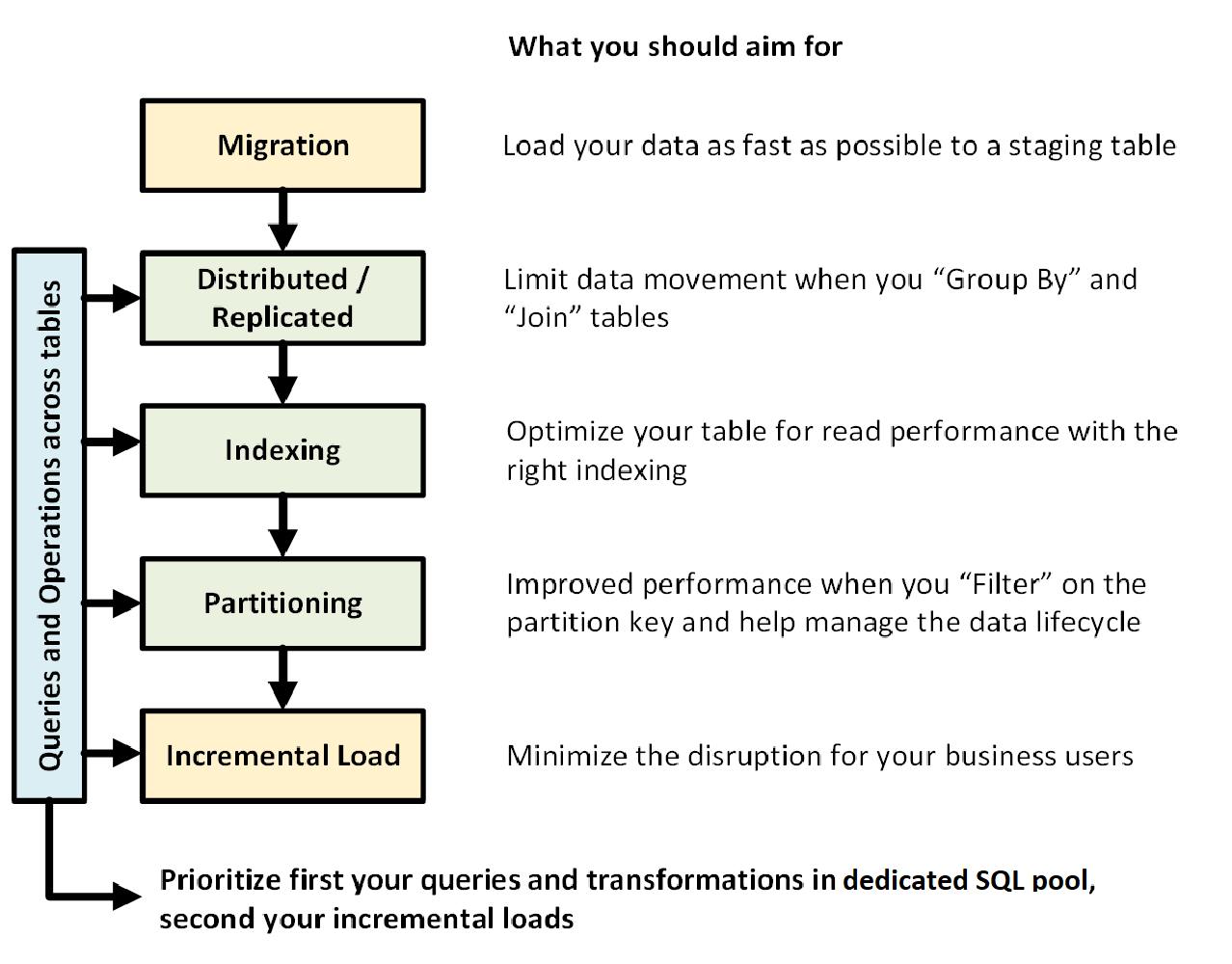
資料表之間的查詢與作業
若您事先已經知道要在資料倉儲中執行的主要作業和查詢,即可針對這些作業來設定資料倉儲架構的優先權。 這類查詢作業和作業可能包括:
- 將一或兩個事實資料表與維度資料表聯結、篩選合併的資料表,再將結果附加到資料超市。
- 對您的事實銷售進行進行大型或小型的更新。
- 僅將資料附加到您的資料表。
事先了解作業類型可協助您最佳化資料表的設計。
資料移轉
首先,請將資料載入 Azure Data Lake Storage 或 Azure Blob 儲存體。 接下來,使用 COPY 陳述式將資料載入暫存資料表中。 請使用下列組態︰
| 設計 | 建議 |
|---|---|
| 散發 | 循環配置資源 |
| 編製索引 | 堆積 |
| 資料分割 | None |
| 資源類別 | largerc 或 xlargerc |
深入了解資料移轉、資料載入及擷取、載入和轉換 (ELT) 的流程。
分散式或複寫資料表
請依照資料表屬性使用下列策略:
| 類型 | 絕佳適合... | 請留意,如果... |
|---|---|---|
| 複寫 | * 壓縮 (~5 倍壓縮) 後儲存體小於 2 GB 之星型結構描述中的小型維度資料表 | * 資料表上的許多寫入交易 (例如:插入、更新插入、刪除、更新) * 頻繁變更資料倉儲單位 (DWU) 佈建 * 您只使用 2-3 個資料行,但資料表有許多資料行 * 您對複寫的資料表建立索引 |
| 循環配置資源 (預設) | * 暫存資料表/暫存表格 * 沒有明顯的聯結索引鍵或很好的候選資料行 |
* 因為資料移動而造成效能變慢 |
| 雜湊 | * 事實資料表 * 大型維度資料表 |
* 無法更新散發索引鍵 |
祕訣:
- 以循環配置資源開始,但要追求一個可善用大規模之平行架構的雜湊散發策略。
- 請確定一般雜湊索引鍵具有相同的資料格式。
- 請勿以 varchar 格式散發。
- 具有一般雜湊索引鍵的維度資料表到具有頻繁聯結作業的事實資料表,能夠雜湊散發。
- 使用 sys.dm_pdw_nodes_db_partition_stats 分析資料中的任何偏態。
- 使用 sys.dm_pdw_request_steps 分析查詢背後的資料移動、監視時間廣播並隨機播放作業。 這對檢閱您的散發策略很有幫助。
為資料表編製索引
索引有助於快速讀取資料表。 根據您的需求,還有一組您可以使用的技術:
| 類型 | 絕佳適合... | 請留意,如果... |
|---|---|---|
| 堆積 | * 暫存表格/暫存資料表 * 具有小型查閱的小型資料表 |
* 任何查閱都會掃描完整的資料表 |
| 叢集索引 | * 最多 1 億個資料列的資料表 * 僅重度使用 1-2 個資料行的大型資料表 (超過 1 億個資料列) |
* 使用於複寫資料表 * 您擁有涉及多個聯結和 Group By 作業的複雜查詢 * 您更新索引資料行:這會耗用記憶體 |
| 叢集資料行存放區索引 (CCI) (預設) | * 大型資料表 (超過 1 億個資料列) | * 使用於複寫資料表 * 您在您的資料表上進行大規模更新作業 * 您過度分割資料表:資料列群組並不會跨越不同的散發節點與資料分割 |
祕訣:
- 在叢集索引之上,您可能會想要將非叢集索引加入到重度使用之資料行中,以用來篩選。
- 請注意您在具有 CCI 之資料表上管理記憶體的方式。 當您載入資料時,您會希望使用者 (或查詢) 受益於大型資源類別。 請務必避免修剪和建立許多小型的壓縮資料列群組。
- 在 Gen2 上,系統會在計算節點本機上快取 CCI 資料表,以獲得最大效能。
- CCI 會因為資料列群組的壓縮不良而造成效能變慢。 如果發生這種情況,請重新建置或重新組織您的 CCI。 您希望每個壓縮資料列群組至少各有 10 萬個資料列。 理想狀況是一個資料列群組有 100 萬個資料列。
- 根據累加式載入頻率和大小,您希望在您重新組織或重新建置您的索引時自動化。 徹底清理總是很有幫助。
- 當您想要修剪資料列群組時,請運用策略思考。 開啟的資料列群組有多大? 您預期未來會載入多少資料?
深入了解索引。
資料分割
當您有大型的事實資料表 (大於 10 億個資料列) 時,可能會分割資料表。 99% 的情況下,資料分割索引鍵應該以日期為依據。
若有需要 ELT 的暫存表格,資料分割便有益。 它能協助資料生命週期管理。 請小心避免過度分割您的事實或暫存資料表,特別是在叢集資料行存放區索引上。
深入了解磁碟分割。
累加式載入
如果您要以累加方式載入資料,首先請務必配置較大的資源類別來載入資料。 載入具有叢集資料行存放區索引的資料表時,這一點特別重要。 如需詳細資訊,請參閱資源類別。
我們建議您使用 PolyBase 和 ADF V2,將 ELT 管線自動處理到資料倉儲中。
針對記錄資料中的大型批次更新,請考慮使用 CTAS 來寫入您想要保留在資料表中的資料,而不是使用 INSERT、UPDATE 和 DELETE。
維護統計資料
對您的資料做重大變更 時,同時更新統計資料很重要。 請參閱更新統計資料,判斷是否已發生重大變更。 更新的統計資料會將查詢計劃最佳化。 如果您發現維護所有統計資料所需時間太長,可能要更謹慎選擇為哪些資料行統計資料。
您也可以定義更新的頻率。 例如,您可能想要更新每天都要加入新值的日期資料行。 對於牽涉聯結的資料行、WHERE 子句中使用的資料行、在 GROUP BY 中找到的資料行,統計資料可以獲得最大效益。
深入了解統計資料。
資源類別
資源群組可作為將記憶體配置給查詢的方式。 如果您需要更多的記憶體,以便改善查詢或載入速度,則您需要配置較高的資源類別。 相反地,使用較大的資源類別會影響並行處理。 在將所有使用者移動至較大的資料類別之前,建議您考量以下事項。
如果您注意到查詢時間過長,請檢查您的使用者沒有在大型的資源類別中執行。 大型的資源類別會耗用許多並行處理的位置。 它們會導致其他查詢排入佇列。
最後,藉由使用專用 SQL 集區 (先前稱為 SQL DW) 的 Gen2,每個資源類別都會獲得比 Gen1 多 2.5 倍的記憶體。
深入了解如何使用資源類別與並行處理。
降低您的成本
Azure Synapse 的主要功能就是能夠管理計算資源。 您可以在不使用專用 SQL 集區 (先前稱為 SQL DW) 時予以暫停,這會停止計算資源的計費。 您可以調整資源,以符合您的效能需求。 若要暫停,請使用 Azure 入口網站或 PowerShell。 若要調整規模,請使用 Azure 入口網站、PowerShell、T-SQL 或 REST API。
使用 Azure 函式,在您想要的時間自動調整規模:

將架構最佳化以發揮最大效能
建議您考量中樞架構和支點架構中的 SQL 資料庫和 Azure Analysis Services。 該解決方案可以隔離不同使用者群組之間的工作負載,也可以使用 SQL Database 和 Azure Analysis Services 的進階安全性功能。 這也是將無限制的並行處理提供給您的使用者的一種方法。
深入了解利用 Azure Synapse Analytics 中的專用 SQL 集區 (先前稱為 SQL DW) 的一般架構。
按一下 SQL 資料庫中的支點,從專用 SQL 集區 (先前稱為 SQL DW) 進行部署: