Tip
Microsoft Fabric Data Warehouse 是一個企業規模的關聯式倉庫,建立在資料湖基礎上,具備未來準備架構、內建 AI 及新功能。 如果你是資料倉儲新手,建議先從Fabric Data Warehouse開始。 現有的 專用 SQL 工作負載可升級至 Fabric,以取得資料科學、即時分析與報告等多項新功能。
在本文中,您將瞭解如何使用無伺服器 Synapse SQL 集區撰寫查詢,以讀取 Delta Lake 檔案。 Delta Lake 是一個開放原始碼的儲存層,可將 ACID (原子性、一致性、隔離性和持久性) 交易功能引入 Apache Spark 和大數據工作負載。 您可以從如何查詢 Delta Lake 數據表影片中深入瞭解。
重要
無伺服器 SQL 集區可以查詢 Delta Lake 1.0 版。 自Delta Lake 1.2版本以來導入的變更(例如重新命名欄位)不支援於無伺服器架構。 如果您使用包含刪除向量、v2 檢查點等的新版本 Delta,您應該考慮使用其他查詢引擎,比如 Microsoft Fabric SQL 端點 for Lakehouses。
Synapse 工作區中的無伺服器 SQL 集區可讓您讀取以 Delta Lake 格式儲存的數據,並將其用於報告工具。 無伺服器 SQL 集區可以讀取使用 Apache Spark、Azure Databricks 或任何其他 Delta Lake 格式產生者所建立的 Delta Lake 檔案。
Azure Synapse 中的 Apache Spark 集區可讓數據工程師使用 Scala、PySpark 和 .NET 修改 Delta Lake 檔案。 無伺服器 SQL 集區可協助數據分析師在數據工程師所建立的 Delta Lake 檔案上建立報告。
重要
使用無伺服器 SQL 集區查詢 Delta Lake 格式是 普遍可用 的功能。 不過,查詢 Spark Delta 數據表仍處於公開預覽狀態,尚未達到生產就緒狀態。 如果您查詢使用 Spark 集區建立的 Delta 數據表,可能會發生已知問題。 請參閱 無伺服器 SQL 集區自助的已知問題。
必要條件
重要
數據源只能在自訂資料庫中建立(無法在 master 資料庫或從 Apache Spark 集區複寫的資料庫中建立)。
若要使用本文中的範例,您必須完成下列步驟:
- 建立資料庫並使用參考「NYC Yellow Taxi」存儲帳戶的數據源。
- 在步驟 1 中建立的資料庫上執行 安裝腳本 ,以初始化 物件。 此安裝指令碼會建立資料來源、資料庫範圍認證,以及用於這些範例中的外部檔案格式。
如果您已建立資料庫,並將內容切換至資料庫(使用 USE database_name 語句或下拉式清單來選取某些查詢編輯器中的資料庫),您可以建立包含數據集根 URI 的外部數據源,並用它來查詢 Delta Lake 檔案。 例如:
CREATE EXTERNAL DATA SOURCE DeltaLakeStorage
WITH ( LOCATION = 'https://<yourstorageaccount>.blob.core.windows.net/delta-lake/' );
GO
SELECT TOP 10 *
FROM OPENROWSET(
BULK 'covid',
DATA_SOURCE = 'DeltaLakeStorage',
FORMAT = 'delta'
) as rows;
如果使用 SAS 金鑰或自訂身分識別來保護資料來源,您可以使用資料庫範圍認證來設定資料來源。
您可以使用指向記憶體根資料夾的位置來建立外部資料來源。 建立外部數據源之後,請使用數據源和函式中檔案的 OPENROWSET 相對路徑。 如此一來,您就不需要使用檔案的完整絕對 URI。 您也可以接著定義自訂認證來存取記憶體位置。
讀取 Delta Lake 資料夾
重要
使用必要條件中的安裝腳本來設定範例數據源和數據表。
OPENROWSET 函數可讓您透過提供根資料夾的 URL 來讀取 Delta Lake 檔案的內容。
查看DELTA檔案內容最簡單的方式是透過提供檔案 URL 給 OPENROWSET 函式並指定DELTA格式。 如果檔案可供公開使用,或如果您的Microsoft Entra 身分識別可以存取此檔案,您應該可以使用類似下列範例所示的查詢來查看檔案的內容:
SELECT TOP 10 *
FROM OPENROWSET(
BULK '/covid/',
DATA_SOURCE = 'DeltaLakeStorage',
FORMAT = 'delta') as rows;
數據行名稱和數據類型會自動從 Delta Lake 檔案讀取。 函 OPENROWSET 式會針對字串數據行使用最佳猜測類型,例如 VARCHAR(1000)。
函式 OPENROWSET 中的 URI 必須參考根 Delta Lake 資料夾,其中包含名為 _delta_log的子資料夾。
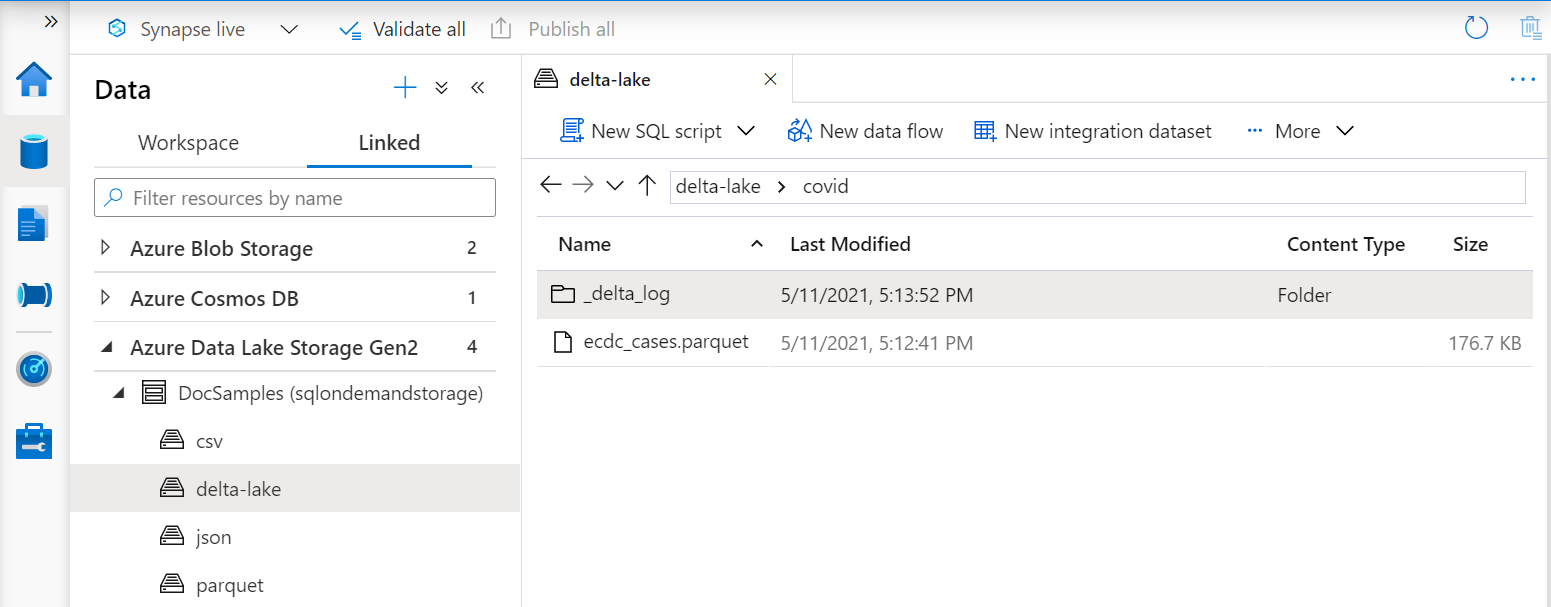
如果您沒有此子資料夾,則不會使用 Delta Lake 格式。 您可以使用類似下列範例 Apache Spark Python 腳本的腳本,將資料夾中的一般 Parquet 檔案轉換成 Delta Lake 格式:
%%pyspark
from delta.tables import DeltaTable
deltaTable = DeltaTable.convertToDelta(spark, "parquet.`abfss://delta-lake@sqlondemandstorage.dfs.core.windows.net/covid`")
注意
無伺服器 Synapse SQL 集區會使用架構推斷來自動判斷數據行及其類型。 架構推斷的規則與 Parquet 檔案所使用的規則相同。 針對 Delta Lake 類型對應到 SQL 原生類型的檢查,請查看 Parquet 的類型對應。
請確定您可以存取檔案。 如果您的檔案受到 SAS 金鑰或自訂 Azure 身分識別的保護,您必須設定 SQL 登入的伺服器層級認證。
重要
請確定您使用的是 UTF-8 資料庫定序(例如 Latin1_General_100_BIN2_UTF8),因為 Delta Lake 檔案中的字串值會使用 UTF-8 編碼進行編碼。
Delta Lake 檔案中的文字編碼與定序不符可能會導致非預期的轉換錯誤。
您可以使用下列 T-SQL 語句,輕鬆變更目前資料庫的預設順序:
ALTER DATABASE CURRENT COLLATE Latin1_General_100_BIN2_UTF8; 如需定序的詳細資訊,請參閱 Synapse SQL 支援的定序類型。
明確指定架構
OPENROWSET 可讓您明確指定要從檔案讀取哪些欄位,使用 WITH 功能子句。
SELECT TOP 10 *
FROM OPENROWSET(
BULK 'covid',
DATA_SOURCE = 'DeltaLakeStorage',
FORMAT = 'delta'
)
WITH ( date_rep date,
cases int,
geo_id varchar(6)
) as rows;
使用結果集架構的明確規格,您可以將類型大小降到最低,並針對字串數據行使用更精確的 VARCHAR(6) 類型,而不是悲觀的 VARCHAR(1000)。 類型的最小化可能會大幅改善查詢的效能。
重要
請確定您在 WITH 子句中明確指定所有字串欄位的 UTF-8 定序(例如 Latin1_General_100_BIN2_UTF8),或者在資料庫層級設置 UTF-8 定序。
檔案中的文字編碼與字串數據行定序之間的不符可能會導致非預期的轉換錯誤。
您可以使用下列 T-SQL 語句,輕鬆變更目前資料庫的預設順序:
alter database current collate Latin1_General_100_BIN2_UTF8 您可以使用下列定義,輕鬆地在資料行類型上設定定序: geo_id varchar(6) collate Latin1_General_100_BIN2_UTF8
資料集
此範例會使用NYC黃色計程車 數據集。 原始 PARQUET 數據集會被轉換成 DELTA 格式,並在範例中使用 DELTA 版本。
查詢分割資料
此範例中提供的數據集被分區到不同的子資料夾中。
不同於 Parquet,您不需要使用 函 FILEPATH 式以特定分割區為目標。
OPENROWSET會識別 Delta Lake 資料夾結構中的數據分割資料行,並可讓您使用這些數據行直接查詢數據。 此範例顯示 2017 年前三個月依年、月和payment_type的票價金額。
SELECT
YEAR(pickup_datetime) AS year,
passenger_count,
COUNT(*) AS cnt
FROM
OPENROWSET(
BULK 'yellow',
DATA_SOURCE = 'DeltaLakeStorage',
FORMAT='DELTA'
) nyc
WHERE
nyc.year = 2017
AND nyc.month IN (1, 2, 3)
AND pickup_datetime BETWEEN CAST('1/1/2017' AS datetime) AND CAST('3/31/2017' AS datetime)
GROUP BY
passenger_count,
YEAR(pickup_datetime)
ORDER BY
YEAR(pickup_datetime),
passenger_count;
函式OPENROWSET將消除在where子句、year及month中不符合條件的分區。 此檔案/數據分割剪除技術可大幅減少數據集、改善效能,以及降低查詢成本。
函式中的資料夾名稱(在此範例中為 OPENROWSET)會使用 LOCATION 資料來源中的 DeltaLakeStorage 連接,而且必須參考包含名為 _delta_log之子資料夾的根 Delta Lake 資料夾。
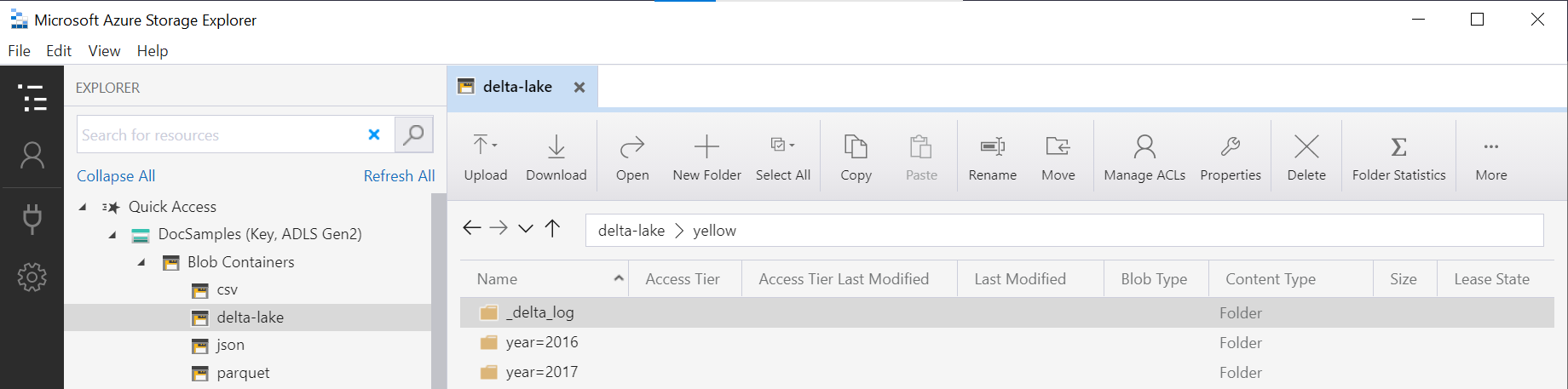
如果您沒有此子資料夾,則不會使用 Delta Lake 格式。 您可以使用下列 Apache Spark Python 腳本,將資料夾中的一般 Parquet 檔案轉換成 Delta Lake 格式:
%%pyspark
from delta.tables import DeltaTable
deltaTable = DeltaTable.convertToDelta(spark, "parquet.`abfss://delta-lake@sqlondemandstorage.dfs.core.windows.net/yellow`", "year INT, month INT")
DeltaTable.convertToDeltaLake 函式的第二個參數代表屬於資料夾模式中的分割欄位(年和月,在此範例中year=*/month=*),以及它們的類型。
限制
- 檢閱 Synapse 無伺服器 SQL 集區自助頁面上的限制和已知問題。
相關內容
接著閱讀下一篇文章,瞭解如何查詢 Parquet 巢狀類型。 如果您想要繼續建置 Delta Lake 解決方案,請瞭解如何在 Delta Lake 資料夾中建立 檢視 或 外部資料表 。