查詢交錯
適用於: SQL Server Analysis Services Azure Analysis Services Fabric/Power BI Premium
SQL Server Analysis Services Azure Analysis Services Fabric/Power BI Premium
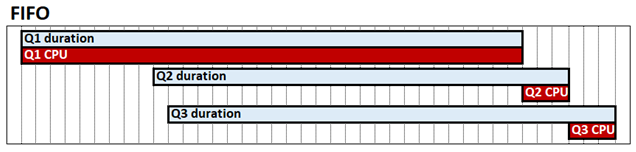
查詢交錯是表格式模式系統組態,可改善高並行案例中的查詢效能。 根據預設,Analysis Services 表格式引擎在 CPU 方面會以先進先出 (FIFO) 方式運作。 例如,使用 FIFO 時,如果收到一個資源昂貴且可能緩慢的儲存引擎查詢,然後接著兩個否則快速的查詢,快速查詢可能會遭到封鎖,等待昂貴的查詢完成。 下圖顯示此行為,其中顯示 Q1、Q2 和 Q3 作為個別查詢、其持續時間和 CPU 時間。
查詢交錯與 短查詢偏差 可讓並行查詢共用 CPU 資源,這表示快速查詢不會在慢速查詢後面封鎖。 完成這三個查詢所需的時間仍然大致相同,但在我們的範例 Q2 和 Q3 中,直到結束才會封鎖。 短查詢偏差表示快速查詢,由每個查詢在指定時間點已耗用多少 CPU 所定義,可以配置比長時間執行的查詢更高的資源比例。 在下圖中,Q2 和 Q3 查詢會被視為 快速 並配置超過 Q1 的 CPU。
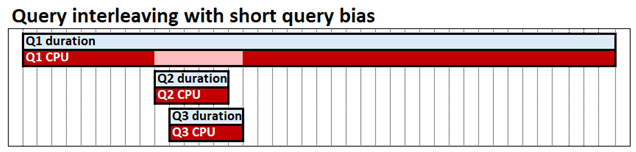
查詢交錯的目的是對隔離執行的查詢產生很少或沒有效能影響;單一查詢仍可使用與 FIFO 模型一樣多的 CPU。
重要考慮
在判斷查詢交錯是否適合您的案例之前,請記住下列事項:
- 查詢交錯僅適用於匯入模型。 它不會影響 DirectQuery 模型。
- 查詢交錯只會考慮 VertiPaq 儲存引擎查詢所使用的 CPU。 它不適用於公式引擎作業。
- 單一 DAX 查詢可能會導致多個 VertiPaq 儲存引擎查詢。 DAX 查詢會根據記憶體引擎查詢取用的 CPU,快速 或 速度變慢。 DAX 查詢是測量單位。
- 重新整理作業預設會受到保護,不受查詢交錯。 長時間執行的重新整理作業會以不同的方式分類為長時間執行的查詢。
配置
若要設定查詢交錯,請設定 Threadpool\SchedulingBehavior 屬性。 您可以使用下列值來指定此屬性:
| 價值 | 描述 |
|---|---|
| -1 | 自動。 引擎會選擇佇列類型。 |
| 0 (SSAS 2019 的預設值) | 首先,先出(FIFO)。 |
| 1 | 簡短的查詢偏差。 當壓力偏向快速查詢時,引擎會逐漸節流長時間執行的查詢。 |
| 3 (Azure AS、Power BI、SSAS 2022 和更新版本的預設) | 快速取消的簡短查詢偏差。 改善高併行案例中的使用者查詢回應時間。 僅適用於 Azure AS、Power BI、SSAS 2022 和更新版本。 |
此時,只能使用 XMLA 來設定 SchedulingBehavior 屬性。 在 SQL Server Management Studio 中,下列 XMLA 代碼段會將 SchedulingBehavior 属性設定為 1、簡短的查詢偏差。
<Alter AllowCreate="true" ObjectExpansion="ObjectProperties" xmlns="http://schemas.microsoft.com/analysisservices/2003/engine">
<Object />
<ObjectDefinition>
<Server xmlns:xsd="http://www.w3.org/2001/XMLSchema" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:ddl2="http://schemas.microsoft.com/analysisservices/2003/engine/2" xmlns:ddl2_2="http://schemas.microsoft.com/analysisservices/2003/engine/2/2" xmlns:ddl100_100="http://schemas.microsoft.com/analysisservices/2008/engine/100/100" xmlns:ddl200="http://schemas.microsoft.com/analysisservices/2010/engine/200" xmlns:ddl200_200="http://schemas.microsoft.com/analysisservices/2010/engine/200/200" xmlns:ddl300="http://schemas.microsoft.com/analysisservices/2011/engine/300" xmlns:ddl300_300="http://schemas.microsoft.com/analysisservices/2011/engine/300/300" xmlns:ddl400="http://schemas.microsoft.com/analysisservices/2012/engine/400" xmlns:ddl400_400="http://schemas.microsoft.com/analysisservices/2012/engine/400/400" xmlns:ddl500="http://schemas.microsoft.com/analysisservices/2013/engine/500" xmlns:ddl500_500="http://schemas.microsoft.com/analysisservices/2013/engine/500/500">
<ID>myserver</ID>
<Name>myserver</Name>
<ServerProperties>
<ServerProperty>
<Name>ThreadPool\SchedulingBehavior</Name>
<Value>1</Value>
</ServerProperty>
</ServerProperties>
</Server>
</ObjectDefinition>
</Alter>
重要
需要重新啟動伺服器實例。 在 Azure Analysis Services 中,您必須暫停再繼續伺服器,才能有效地重新啟動。
其他屬性
在大部分情況下,SchedulingBehavior 是您唯一需要設定的屬性。 下列其他屬性的預設值應該適用於大部分有簡短查詢偏差的案例,不過視需要變更這些屬性。 除非藉由設定 SchedulingBehavior 屬性來啟用查詢交錯,否則下列屬性
ReservedComputeForFastQueries - 設定 快速 查詢的保留邏輯核心數目。 所有查詢都會視為 快速,直到其衰敗,因為它們已耗用一定數量的 CPU。 ReservedComputeForFastQueries 是介於 0 到 100 之間的整數。 預設值為 75。
ReservedComputeForFastQueries 的測量單位是核心的百分比。 例如,在具有 20 個核心的伺服器上,值為 80,會嘗試保留 16 個核心供快速查詢使用(但不會執行重新整理作業)。 ReservedComputeForFastQueries 會四捨五入到最接近的整數核心。 建議您不要將此屬性值設定為低於 50。 這是因為快速查詢可能會被剝奪,而且與功能的整體設計相反。
DecayIntervalCPUTime - 整數,代表查詢在衰變之前花費的毫秒 CPU 時間。 如果系統處於 CPU 壓力之下,衰敗的查詢會限製為未保留給快速查詢的其餘核心。 默認值為 60,000。 這代表 1 分鐘的 CPU 時間,而不是經過的行事歷時間。
ReservedComputeForProcessing - 設定每個處理 (資料重新整理) 作業的保留邏輯核心數目。 屬性值是介於 0 到 100 之間的整數,預設值為 75 表示。 值代表 ReservedComputeForFastQueries 屬性所決定的核心百分比。 值為 0 (零) 表示處理作業受限於與查詢相同的查詢交錯邏輯,因此可能會衰敗。
雖然未執行任何處理作業,但 ReservedComputeForProcessing 沒有任何作用。 例如,在值為 80 的伺服器上,具有 20 個核心的 ReservedComputeForFastQueries 會保留 16 個核心供快速查詢使用。 使用 75 的值,ReservedComputeForProcessing 接著會保留 16 個核心中的 12 個進行重新整理作業,讓 4 個用於快速查詢,同時處理作業正在執行和取用 CPU。 如下列 衰敗查詢 一節所述,其餘 4 個核心(未保留給快速查詢或處理作業)仍會在閑置時用於快速查詢和處理。
這些額外的屬性位於 ResourceGovernance 屬性節點底下。 在 SQL Server Management Studio 中,下列範例 XMLA 代碼段會將 DecayIntervalCPUTime 屬性設定為低於預設值的值:
<Alter AllowCreate="true" ObjectExpansion="ObjectProperties" xmlns="http://schemas.microsoft.com/analysisservices/2003/engine">
<Object />
<ObjectDefinition>
<Server xmlns:xsd="http://www.w3.org/2001/XMLSchema" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:ddl2="http://schemas.microsoft.com/analysisservices/2003/engine/2" xmlns:ddl2_2="http://schemas.microsoft.com/analysisservices/2003/engine/2/2" xmlns:ddl100_100="http://schemas.microsoft.com/analysisservices/2008/engine/100/100" xmlns:ddl200="http://schemas.microsoft.com/analysisservices/2010/engine/200" xmlns:ddl200_200="http://schemas.microsoft.com/analysisservices/2010/engine/200/200" xmlns:ddl300="http://schemas.microsoft.com/analysisservices/2011/engine/300" xmlns:ddl300_300="http://schemas.microsoft.com/analysisservices/2011/engine/300/300" xmlns:ddl400="http://schemas.microsoft.com/analysisservices/2012/engine/400" xmlns:ddl400_400="http://schemas.microsoft.com/analysisservices/2012/engine/400/400" xmlns:ddl500="http://schemas.microsoft.com/analysisservices/2013/engine/500" xmlns:ddl500_500="http://schemas.microsoft.com/analysisservices/2013/engine/500/500">
<ID>myserver</ID>
<Name>myserver</Name>
<ServerProperties>
<ServerProperty>
<Name>ResourceGovernance\DecayIntervalCPUTime</Name>
<Value>15000</Value>
</ServerProperty>
</ServerProperties>
</Server>
</ObjectDefinition>
</Alter>
已衰敗的查詢
本節所述的條件約束僅適用於系統承受 CPU 壓力時。 例如,單一查詢,如果它是在指定時間在系統中執行的唯一查詢,則不論其是否已衰敗,都可以取用所有可用的核心。
每個查詢可能需要許多儲存引擎作業。 當集區中衰變查詢的核心可供使用時,排程器會根據經過的行事歷時間檢查最舊的執行查詢,以查看其是否已用盡其 最大核心權利 (MCE)。 如果沒有,則會執行其下一個作業。 如果是,則會評估下一個最舊的查詢。 查詢 MCE 取決於它已經使用的衰變間隔數目。 針對所使用的每個衰變間隔,MCE 會根據下表所示的演算法來減少。 這會繼續執行,直到查詢完成、逾時或 MCE 縮減為單一核心為止。
在下列範例中,系統有 32 個核心,且系統的 CPU 承受壓力。
ReservedComputeForFastQueries 為 60 (60%)。
- 20 個核心 (19.2 進位) 保留給快速查詢。
- 其餘12個核心會配置給衰敗的查詢。
DecayIntervalCPUTime 為 60,000 (CPU 時間 1 分鐘)。
只要查詢未逾時或完成,查詢的生命週期可能如下所示:
| 階段 | 地位 | 執行/排程 | MCE |
|---|---|---|---|
| 0 | 快 | MCE 是 20 個核心(保留給快速查詢)。 在 20 個保留核心之間,以 FIFO 方式執行查詢,以其他 快速 查詢。 CPU 時間的 1 分鐘衰減間隔已用到。 |
20 = MIN(32/2˄0, 20) |
| 1 | 腐爛 | MCE 設定為12個核心(其餘12個核心未保留給快速查詢)。 作業會根據 MCE 的可用性來執行。 CPU 時間的 1 分鐘衰減間隔已用到。 |
12 = MIN(32/2˄1, 12) |
| 2 | 腐爛 | MCE 設定為 8 個核心(32 個核心總數的四分之一)。 作業會根據 MCE 的可用性來執行。 CPU 時間的 1 分鐘衰減間隔已用到。 |
8 = MIN(32/2˄2, 12) |
| 3 | 腐爛 | MCE 會設定為 4 個核心。 作業會根據 MCE 的可用性來執行。 CPU 時間的 1 分鐘衰減間隔已用到。 |
4 = MIN(32/2˄3, 12) |
| 4 | 腐爛 | MCE 會設定為 2 個核心。 作業會根據 MCE 的可用性來執行。 CPU 時間的 1 分鐘衰減間隔已用到。 |
2 = MIN(32/2˄4, 12) |
| 5 | 腐爛 | MCE 會設定為 1 核心。 作業會根據 MCE 的可用性來執行。 當查詢已觸底時,不會套用衰變間隔。 沒有進一步衰變,因為達到至少1個核心。 |
1 = MIN(32/2˄5, 12) |
如果系統處於 CPU 壓力之下,則每個查詢的指派數目不會超過其 MCE。 如果所有核心目前都供各自 MCE 內的查詢使用,則其他查詢會等到核心可供使用。 當核心可供使用時,會根據經過的行事歷時間挑選最舊的標題查詢。 MCE 是壓力下的上限:它不保證任何時間點的核心數目。
另請參閱
Analysis Services 中的伺服器屬性
意見反應
即將登場:在 2024 年,我們將逐步淘汰 GitHub 問題作為內容的意見反應機制,並將它取代為新的意見反應系統。 如需詳細資訊,請參閱:https://aka.ms/ContentUserFeedback。
提交並檢視相關的意見反應