TL;DR – Update to the latest CU, create multiple tempdb files, if you're on SQL 2014 or earlier enable TF 1117 and 1118, if you're on SQL 2016 enable TF 3427.
And now it's time for everyone's favorite SQL Server topic – tempdb! In this article, I'd like to cover some recent changes that you may not be aware of that can help alleviate some common performance issues for systems that have a very heavy tempdb workload. We're going to cover three different scenarios here:
- Object allocation contention
- Metadata contention
- Auditing overhead (even if you don't use auditing)
Object Allocation Contention
If you've been working with SQL Server for some time you've probably come across some recommendations for tempdb configuration. Here's the common wisdom when it comes to configuring tempdb:
- Create multiple data files
You should start with 1 tempdb data file per CPU core up to 8 files. You may need to add more depending on your workload. All the files must be equally sized. - If you are on SQL Server 2014 or earlier, turn on trace flags 1117 and 1118 (this behavior is the default for tempdb in SQL Server 2016).
These recommendations help address an object allocation bottleneck that can happen when your workload creates many temp tables concurrently. You know you have this type of contention if you see a lot of PAGELATCH waits on page resources 2:X:1 (PFS), 2:X:3 (SGAM), or 2:X:<some multiple of 8088> (also PFS) where X is a file number. These are special pages which are used when SQL Server needs to allocate space for a new object. By having multiple files that are equally sized, each new object allocation hits a different file, and thus a different PFS page, in a round robin fashion. It's such a common scenario that we've made these configurations the default in SQL Server 2016.
There are some cases where having multiple files alone does not completely address PFS contention. For these cases, we have implemented a fix where we not only round robin between the files, we also round robin between the PFS pages within the files, allowing us to spread the object allocations across all the files and within the files themselves. It works something like this:
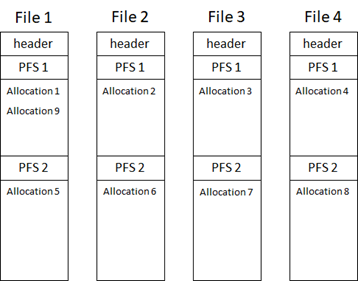
Figure 1: New round robin algorithm for allocating space using PFS pages.
As you can see, this will have the effect of spreading the object allocations across the entirety of the files rather than filling them from the beginning to the end. The tradeoff with spreading the allocations throughout the file is that a shrink operation may take longer because it will need to relocate data to the beginning of the file. In fact, if temp tables are still being created during the shrink operation, you may not be able to shrink the files much at all. Hopefully you're not shrinking databases anyway so that shouldn't be a huge burden :)
With this change, not only will increasing the number of files help with PFS contention, increasing the size of the files (which increases the number of PFS pages in the file) will also help. This new behavior doesn't replace the need for multiple files, it just gives you another tool to troubleshoot PFS contention. The recommendation listed above for number of files is still valid, and in fact, if you are having I/O contention on the tempdb storage device in addition to PFS contention, having multiple files will allow you to easily balance the I/O across multiple devices if you need to.
Metadata Contention
Object allocation contention has been a common occurrence across many versions of SQL Server, but over the years with database engine and hardware improvements that increase the frequency of temp table generation, another type of contention in tempdb has emerged – metadata contention. This is contention on the system objects in tempdb that are used to track temp tables. For this issue, let me rewind the clock a little bit and give you some history. If you've been working with SQL Server for a long time (sorry I'm about to remind you how old you are :-P), you may remember this super awesome amazing version of SQL Server called SQL Server 2005. This is the version where we introduced a whole new world: the SQLOS, DMVs and temp table caching (among other things). Temp table caching was introduced because we were already seeing metadata contention in SQL Server 2000. Caching the metadata for temp tables that were created by stored procedures (and thus were nearly guaranteed to be re-used as-is) allowed us to reduce the contention we were seeing when we inserted new metadata into the system tables. This worked beautifully and allowed us to scale up for many years.
Cache isn't an unlimited resource so of course we need to periodically prune the cache to make room for new objects. Whenever we remove something from the cache, we need to delete the corresponding rows from our metadata tables. Fast forward to today – have you guessed where we are heading yet? Now we are starting to see contention on the deletes from the cache. This is a problem you may have seen in the past, but it wasn't often on a large scale. In SQL Server 2016 this problem has become more noticeable because of the increase in table metadata that comes along with some of the new features implemented in this version. Features like temporal tables and Always Encrypted require additional metadata, and even though most of your temp tables aren't going to use these features, we need to track this metadata just in case. This means when we need to prune the temp table cache, either because of memory pressure or because a cache item has been invalidated, we need to remove a lot more metadata than we did in the past.
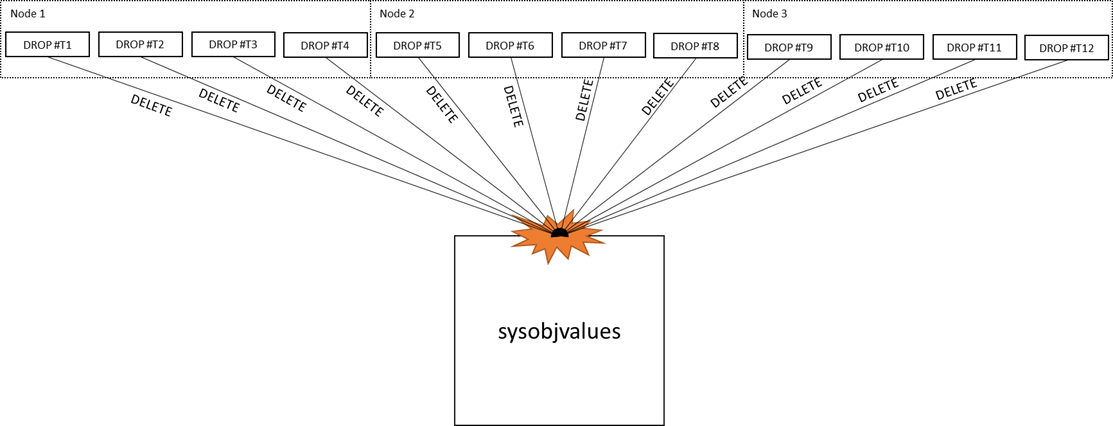
Figure 2: Illustration of tempdb metadata contention.
To address this problem, we have made 3 main changes to how we prune the temp table cache:
- We changed the process from synchronous to asynchronous.
Whenever a temp table changes within a stored procedure (e.g. add an index, add a column, explicitly drop etc.), it can't be reused. The previous behavior was to synchronously drop the table at the end of the procedure. Now, the table is not immediately dropped, it is moved to a deleted list and dropped later by another thread. With this behavior change, the only thing that triggers a delete from the cache is memory pressure, which is handled by a cache clock hand sweep, the same as other caches in SQL Server. Figure 3: Change to asynchronous drop of tempdb metadata. Note that this behavior only applies to temp tables that are created within a Stored Procedure as we do not cache ad-hoc temp tables.
Figure 3: Change to asynchronous drop of tempdb metadata. Note that this behavior only applies to temp tables that are created within a Stored Procedure as we do not cache ad-hoc temp tables. - We reduced the number of helper threads to one per NUMA node and increased the number of tables that get removed with each pass.
Previously when the deleted list reached a certain size, any thread which needed to add something to the cache had to remove an object from the deleted list first. Now only one thread per NUMA node will be tasked as a helper thread, and the threads will remove 64 objects at a time rather than 1.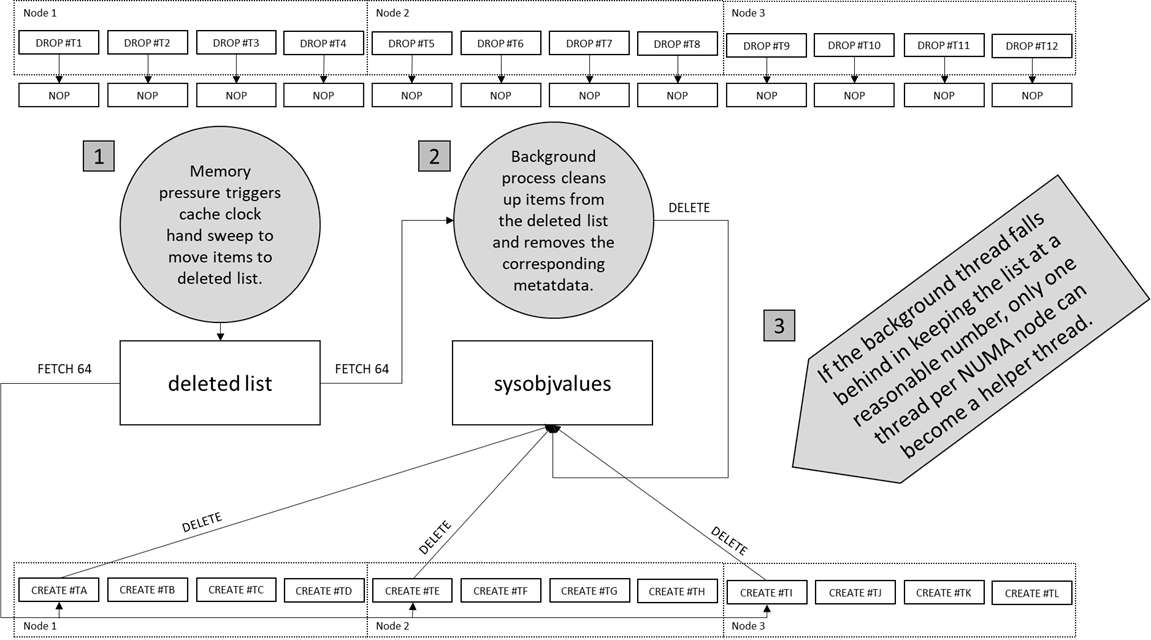 Figure 4: Reduce helper threads to one per NUMA node. Note that this behavior only applies to temp tables that are created within a Stored Procedure as we do not cache ad-hoc temp tables.
Figure 4: Reduce helper threads to one per NUMA node. Note that this behavior only applies to temp tables that are created within a Stored Procedure as we do not cache ad-hoc temp tables. - We optimized the latching strategy used when we scan for metadata.
To remove a record from a page, you must get exclusive access to that page in memory, this is what we call a page latch or buffer latch, specifically PAGELATCH_EX. Originally the process was to get an exclusive latch while we search for rows of metadata to drop. Now we get a shared latch and check to see if the rows exist first, then get an exclusive latch only if we find rows that need to be deleted. Most of the metadata that we're searching for won't exist on a temporary table, so it's a good bet we won't have to convert the latch to exclusive. This makes the overall process less likely to cause blocking.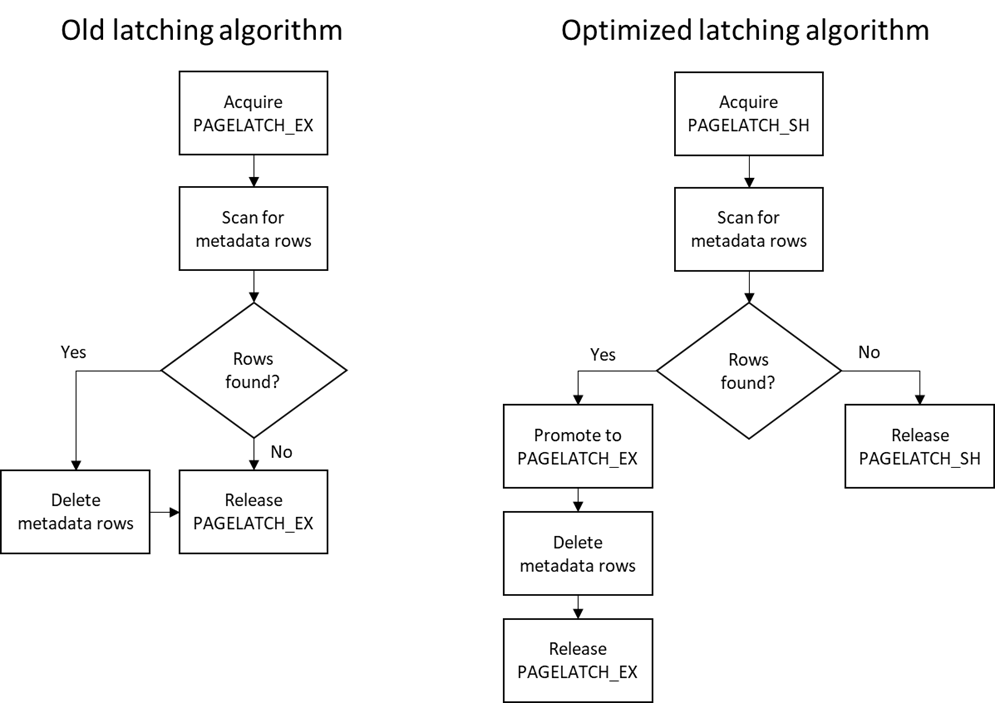 Figure 5: Latching strategy change. Note that this behavior only applies to temp tables that are created within a Stored Procedure as we do not cache ad-hoc temp tables.
Figure 5: Latching strategy change. Note that this behavior only applies to temp tables that are created within a Stored Procedure as we do not cache ad-hoc temp tables.
So how do you know if you have this metadata contention? At first glance it may look a lot like the tempdb contention you're used to seeing – PAGELATCH waits on various tempdb pages (2:X:Y where X is a file number and Y is a page number). The difference here is that rather than PFS and SGAM pages, these will be pages that belong to system objects such as sysobjvalues and sysseobjvalues. Here are the fixes which help address metadata contention in tempdb:
Performance issues occur in the form of PAGELATCH_EX and PAGELATCH_SH waits in TempDB when you use SQL Server 2016 FIX: Heavy tempdb contention occurs in SQL Server 2016 or 2017
Keep in mind that even with these fixes, it's still possible to hit metadata contention in tempdb. We are continuing to work on improving tempdb performance and metadata contention, but in the meantime, there are some best practices you can employ in your code that might help avoid the contention:
- Do not explicitly drop temp tables at the end of a stored procedure, they will get cleaned up when the session that created them ends.
- Do not alter temp tables after they have been created.
- Do not truncate temp tables
- Move index creation statements on temp tables to the new inline index creation syntax that was introduced in SQL Server 2014.
The above practices help ensure that the temp tables you create within your stored procedures are eligible for caching. Temp tables that are altered or explicitly dropped [EDIT: While an explicit drop of a temp table in a stored procedure is unnecessary and thus not recommended, it will not invalidate the cache entry.] within the stored procedure will be marked for deletion since they can't be reused. The more temp tables that need to be deleted, the more likely you are to hit the contention described above. It's also worth mentioning here that table variables carry less overhead than temp tables and may be appropriate in some scenarios in place of a temp table. If the number of rows in the table is known to be small (rule of thumb is < 100), table variables may be a good alternative. Also keep in mind that no statistics are created for table variables. If the queries you are executing against the table variable are sensitive to cardinality changes, consider enabling trace flag 2453 to turn on cardinality-based recompiles for table variables.
Auditing Overhead
Another change in SQL Server 2016 behavior that could impact tempdb-heavy workloads has to do with Common Criteria Compliance (CCC), also known as C2 auditing. We introduced functionality to allow for transaction-level auditing in CCC which can cause some additional overhead, particularly in workloads that do heavy inserts and updates in temp tables. Unfortunately, this overhead is incurred whether you have CCC enabled or not. In SQL Server 2016 you can enable trace flag 3427 to bypass this overhead starting with SP1 CU2. Starting in SQL Server 2016 SP2 CU2 and SQL Server 2017 CU4, we automatically bypass this code if CCC is disabled.
Hope this helps you optimize your tempdb workloads! Stay tuned for more tempdb improvements in future versions of SQL Server!
Comments
- Anonymous
November 19, 2018
Great write-up! Thanks for letting me geek out during my holiday. Best regards!