SQL Server 2016 Service Pack 1 (SP1) released !!!
With cloud first strategy, the SQL Product Team has observed great success and adoption of SQL Server 2016 compared to any previous releases. Today, we are even more excited and pleased to announce the availability of SQL Server 2016 Service Pack 1 (SP1) . With SQL Server 2016 SP1, we are making key improvements allowing a consistent programmability surface area for developers and organizations across SQL Server editions. This will enable you to build advanced applications that scale across editions and cloud as you grow. Developers and application partners can now build to a single programming surface when creating or upgrading intelligent applications, and use the edition which scales to the application's needs.
In addition to a consistent programmability experience across all editions, SQL Server 2016 SP1 also introduces all the supportability and diagnostics improvements first introduced in SQL 2014 SP2, as well as new improvements and fixes centered around performance, supportability, programmability and diagnostics based on the learnings and feedback from customers and SQL community.
SQL Server 2016 SP1 also includes all the fixes up to SQL Server 2016 RTM CU3 including Security Update MS16–136.
Following is the detailed list of improvements introduced in SQL Server 2016 SP1
The following table compares the list of features which were only available in Enterprise edition which are now enabled in Standard, Web, Express, and LocalDB editions with SQL Server 2016 SP1. This consistent programmatically surface area allows developers and ISVs to develop and build applications leveraging the following features which can be deployed against any edition of SQL Server installed in the customer environment. The scale and high availability limits do not change, and remain as–is for lower editions as documented in this MSDN article.
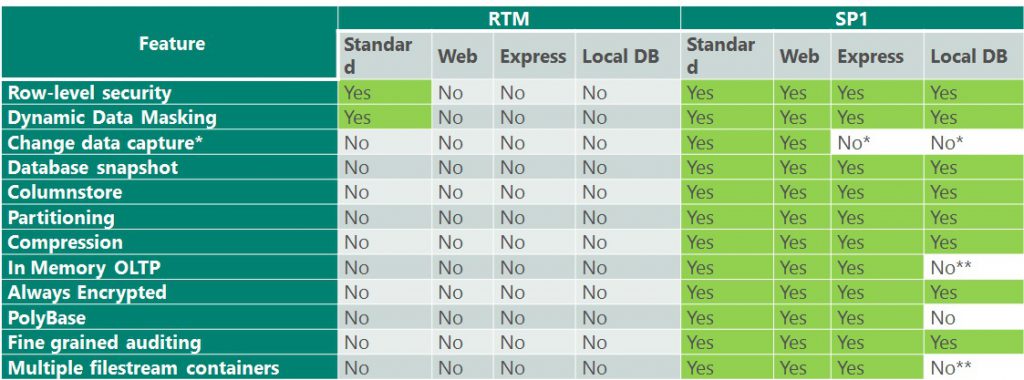 * Requires SQL Server agent which is not part of SQL Server Express Editions
* Requires SQL Server agent which is not part of SQL Server Express Editions
** Requires creating filestream file groups which is not possible in Local DB due to insufficient permissions.
Boosting transaction processing using Storage Class Memory in Windows Server 2016 - One of the most significant performance overheads for high transactional workloads systems is committing to the transaction log. This is especially true when employing In-Memory OLTP tables which remove most other bottlenecks from high update rate applications. SQL Server 2016 SP1 adds a significant new performance feature, the ability to accelerate transaction commit times by orders of magnitude, when employing Storage Class Memory (NVDIMM-N nonvolatile storage) supported in Windows Server 2016. This scenario is also referred to as “Persistent Log buffer” which is explained in detail in our SQL Server storage engine blog.
Database Cloning – Clone database is a new DBCC command added that allows DBAs and support teams to troubleshoot existing production databases by cloning the schema and metadata, statistics without the data. Cloned databases is not meant to be used in production environments. To see if a database has been generated from a call to clonedatabase you can use the following command, select DATABASEPROPERTYEX('clonedb', 'isClone'). The return value of 1 is true, and 0 is false. In SQL Server 2016 SP1, DBCC CLONEDATABASE added supports cloning of CLR, Filestream/Filetable, Hekaton and Query Store objects. DBCC CLONEDATABASE in SQL 2016 SP1 gives you the ability to generate query store only, statistics only, or pure schema only clone without statistics or query store. A CLONED database always contains the schema and the default clone also contains the statistics and query store data. For more information refer KB 3177838.
DBCC CLONEDATABASE (source_database_name, target_database_name) –– Default CLONE WITH SCHEMA, STATISTICS and QUERYSTORE metadata.
DBCC CLONEDATABASE (source_database_name, target_database_name) WITH NO_STATISTICS –– SCHEMA AND QUERY STORE ONLY CLONE
DBCC CLONEDATABASE (source_database_name, target_database_name) WITH NO_QUERYSTORE –– SCHEMA AND STATISTICS ONLY CLONE
DBCC CLONEDATABASE (source_database_name, target_database_name) WITH NO_STATISTICS,NO_QUERYSTORE –– SCHEMA ONLY CLONECREATE OR ALTER (Yes, we heard you !!!) – New CREATE OR ALTER support makes it easier to modify and deploy objects like Stored Procedures, Triggers, User–Defined Functions, and Views. This was one of the highly requested features by developers and SQL Community.
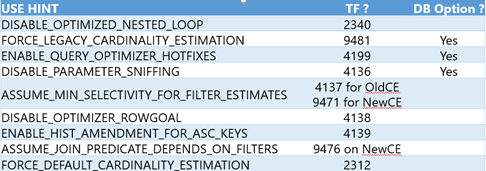
New USE HINT query option – A new query option, OPTION(USE HINT('<option>')) , is added to alter query optimizer behavior using supported query level hints listed below. Nine different hints are supported to enable functionality which was previously only available via trace flags. Unlike QUERYTRACEON, the USE HINT option does not require sysadmin privileges.
- Programmatically identify LPIM to SQL service account – New sql_memory_model, sql_memory_model_desc columns in DMV sys.dm_os_sys_info to allow DBAs to programmatically identify if Lock Pages in Memory (LPIM) privilege is in effect at the service startup time.
- Programatically identify IFI privilege to SQL service account – New column instant_file_initialization_enabled in DMV sys.dm_server_services to allow DBAs to programmatically identify if Instant File initialization (IFI) is in effect at the SQL Server service startup.
- Tempdb supportability – A new Errorlog message indicating the number of tempdb files and notifying different size/autogrowth of tempdb data files at server startup.
- Extended diagnostics in showplan XML – Showplan XML extended to support Memory grant warning, expose max memory enabled for the query, information about enabled trace flags, memory fractions for optimized nested loop joins, query CPU time, query elapsed time, top waits, and information about parameters data type.
- Lightweight per–operator query execution profiling – Dramatically reduces performance overhead of collecting per–operator query execution statistics such as actual number of rows. This feature can be enabled either using global startup TF 7412, or is automatically turned on when an XE session containing query_thread_profile is enabled. When the lightweight profiling is on, the information in sys.dm_exec_query_profiles is also available, enabling the Live Query Statistics feature in SSMS and populating a new DMF sys.dm_exec_query_statistics_xml.
- New DMF sys.dm_exec_query_statistics_xml – Use this DMF to obtain actual query execution showplan XML (with actual number of rows) for a query which is still being executed in a given session (session id as input parameter). The showplan with a snapshot of current execution statistics is returned when profiling infrastructure (legacy or lightweight) is on.
- New DMF for incremental statistics – New DMF sys.dm_db_incremental_stats_properties to expose information per–partition for incremental stats.
- Better correlation between diagnostics XE and DMVs – Query_hash and query_plan_hash are used for identifying a query uniquely. DMV defines them as varbinary(8), while XEvent defines them as UINT64. Since SQL server does not have "unsigned bigint", casting does not always work. This improvement introduces new XEvent action/filter columns equivalent to query_hash and query_plan_hash except they are defined as INT64 which can help correlating queries between XE and DMVs.
- Better troubleshooting for query plans with push–down predicate – New EstimatedlRowsRead attribute added in showplan XML for better troubleshooting and diagnostics for query plans with push down predicates.
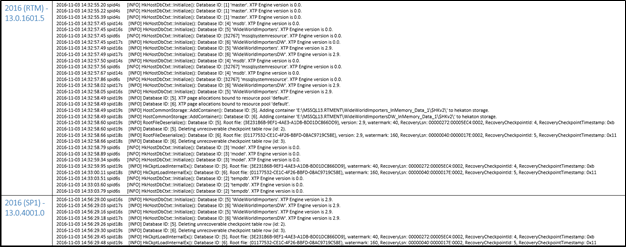
- Removing noisy Hekaton logging messages from Errorlog – With SQL 2016, Hekaton engine started logging additional messages in SQL Errorlog for supportability and troubleshooting which was overwhelming and flooded the Errorlog with hekaton messages. Based on feedback from DBAs and SQL community, starting SQL 2016 SP1, the Hekaton logging messages are reduced to minimal in Error log as shown below.
- Improved AlwaysOn Latency Diagnostics – New XEvents and Perfmon diagnostics capability added to troubleshoot latency more efficiently.
- Manual Change Tracking Cleanup – New cleanup stored procedure sp_flush_CT_internal_table_on_demand introduced to clean the change tracking internal table on demand. For more information, refer KB 3173157.
- DROP TABLE support for replication - DROP TABLE DDL support for replication to allow replication articles to be dropped. For more information, refer KB 3170123.
- Signed Filestream RsFx Driver on Windows Server 2016/Windows 10– The Filestream RsFx driver introduced with SQL Server 2016 SP1 is signed and certified using Windows Hardware Developer Center Dashboard portal (Dev Portal) allowing SQL Server 2016 SP1 Filestream RsFx driver to be installed on Windows Server 2016/Windows 10 without any issue. For more information on this issue, refer to the SQL Tiger team blogpost here.
- Bulk insert into heaps with auto TABLOCK under TF 715 – Trace Flag 715 enables table lock for bulk load operations into heap with no non–clustered indexes. When this trace flag is enabled, bulk load operations acquires bulk update (BU) locks when bulk copying data into a table. Bulk update (BU) locks allow multiple threads to bulk load data concurrently into the same table while preventing other processes that are not bulk loading data from accessing the table. The behavior is similar to when the user explicitly specifies TABLOCK hint while performing bulk load or when the sp_tableoption table lock on bulk load is on for a given table however enabling this TF makes this behavior by default without making any query changes or database changes. For more information, refer to the SQL Tiger team blog post here.
- Parallel INSERT..SELECT Changes for Local temp tables – With SQL Server 2016, Parallel INSERT in INSERT…SELECT operations was introduced. INSERTs into user tables required TABLOCK hint for parallel inserts while INSERTs into local temporary tables were automatically enabled for parallelism without having to designate the TABLOCK hint that user tables require. In a batch workload, INSERT parallelism significantly improves query performance but if there's a significant concurrent workload trying to run parallel inserts, it causes considerable contention against PFS pages which reduces the overall throughput of the system. This behavior introduced regression in OLTP workload migrating to SQL Server 2016. With SQL Server 2016 SP1, Parallel INSERTs in INSERT..SELECT to local temporary tables is disabled by default and will require TABLOCK hint for parallel insert to be enabled.
All the newly introduced Trace flags with SQL Server 2016 SP1 are documented and can be found at https://aka.ms/traceflags.
The full versions of the WideWorldImporters sample databases now work with Standard Edition and Express Edition, starting SQL Server 2016 SP1. No changes were needed in the sample. The database backups created at RTM for Enterprise edition simply work with Standard and Express in SP1. Download is here: https://github.com/Microsoft/sql-server-samples/releases/tag/wide-world-importers-v1.0
The SQL Server 2016 SP1 installation may require reboot post installation. As a best practice, we recommend to plan and perform a reboot following the installation of SQL Server 2016 SP1.
We will be updating and adding follow-up posts on the Tiger blog in the coming weeks to describe some of the above improvements in detail.
As noted above, SP1 contains a roll-up of solutions provided in SQL Server 2016 cumulative updates up to and including the latest Cumulative Update – CU3 and Security Update MS16–136 released on November 8th, 2016. Therefore, there is no reason to wait for SP1 CU1 to 'catch–up' with SQL Server 2016 CU3 content.
The Service Pack is available for download on the Microsoft Download Center and ready to use in Azure Images Gallery and will also be made available on the, MSDN, Eval Center, MBS/Partner Source and VLSC in the coming weeks. As part of our continued commitment to software excellence for our customers, this upgrade is available to all customers with existing SQL Server 2016 deployments.
To obtain SQL Server 2016 SP1, please visit the links below:
SQL Server 2016 SP1 SQL Server 2016 SP1 Feature Pack SQL Server 2016 Service Pack 1 Release Information
Thank you,
Microsoft SQL Server Engineering Team
Comments
- Anonymous
November 16, 2016
Hi,Can you clarify this statement: "With SQL Server 2016 SP1, Parallel INSERTs in INSERT..SELECT to local temporary tables is disabled and will also require TABLOCK hint for parallel insert to be enabled."Does this mean that it's always disabled for temp tables, and TABLOCK will be required for non-temp tables? Or does it mean that TABLOCK will allow it for temp tables? It seems rather ambiguously worded.Thanks,Adam- Anonymous
November 16, 2016
Hi Adam, it means it is disabled by default for local temporary tables but when you use TABLOCK hint with local temporary table, you will see parallel plan. The behavior is consistent with INSERT..SELECT for non-temp tables now with SP1.
- Anonymous
- Anonymous
November 16, 2016
Holy carp! - Anonymous
November 16, 2016
The comment has been removed- Anonymous
November 16, 2016
The comment has been removed- Anonymous
November 16, 2016
The comment has been removed
- Anonymous
- Anonymous
- Anonymous
November 16, 2016
This is huge! Thanks - Anonymous
November 16, 2016
And so, COLUMNSTORE is also available in Standard Edition now?- Anonymous
November 16, 2016
Yes it is ?- Anonymous
November 16, 2016
Great!!! - Anonymous
November 18, 2016
For in-memory tables only or for disk-based (xVelocity) tables too ?- Anonymous
November 28, 2016
In SQL 2016 SP1, Standard Edition supports Columnstore indexes on disk based tables, and in-memory tables.
- Anonymous
- Anonymous
- Anonymous
- Anonymous
November 16, 2016
The comment has been removed- Anonymous
November 16, 2016
Always ON and other operational limits remain the same.
- Anonymous
- Anonymous
November 16, 2016
Is the reporting services branding available in the standard edition now?- Anonymous
November 16, 2016
Hi Kurt, All SP1 enhancements for SSRS are blogged in RSTeamblog https://blogs.msdn.microsoft.com/sqlrsteamblog/2016/11/16/whats-new-in-sql-server-2016-sp1-for-reporting-services/
- Anonymous
- Anonymous
November 16, 2016
Very nice. How about a higher memory limit for Service Pack 2?Please?- Anonymous
November 28, 2016
Yes !! as well as CPU, it is "2016" for crying out loud. We will no longer require EE at all, or simply charge a Enhanced RAM licensing fee for anything above the current limit, such as a one time lic fee of $150 for each 10GB additional above limit, same for CPU.
- Anonymous
- Anonymous
November 16, 2016
partitioning is available in standard version now? Is this same partitioning that was only in enterprise versions before?- Anonymous
November 16, 2016
Yes it is.- Anonymous
November 28, 2016
If we restore a SQL 2014 R2 EE database, using tab partitioning and page/row compression to a 2016 SP1 instance, those features will be retained ?- Anonymous
November 28, 2016
There is no SQL 2014 R2. However, if you're referring to restoring a 2014 or 2016 EE DB using those two features, they will be retained.
- Anonymous
- Anonymous
- Anonymous
- Anonymous
November 16, 2016
When are these coming to sql azure db such as Create Or Alter.- Anonymous
November 28, 2016
CREATE OR ALTER is enabled in SQL Azure DB. As are the new USE HINT query hints.
- Anonymous
- Anonymous
November 16, 2016
(feel free to remove this and my previous comment...I was running the expensive query without stats profile on, which is a requirement) - Anonymous
November 16, 2016
That's pretty good news. Passed this on to our ops team as this is something of interest to them.I was looking at v.Next and saw that String_Agg is added there. Any chance of that making it down to SQL 2016 in a future SP/CU or is that just too different? - Anonymous
November 16, 2016
The comment has been removed- Anonymous
November 16, 2016
A1. You can use sys.dm_db_persisted_sku_features track features which are already turned ON. There is no DMV which gives Is_Data_Compression_available but you can use a query to see if it Enterprise Edition or if build number > 13.0.4001. Can that work?A2. The restore to 2016SP1 Standard will work. A3. You will need to drop all the sku features like partitioning table, In-memory oltp, Columnstore index before you downgrade else the databases might go in suspect mode. There is no trace flag or registry fixes to turn off features since the user objects associated with the features are not auto dropped.You can use sys.dm_db_persisted_sku_features to identify the features in use and drop them before you downgrade. We will publish a KB article on this soon.A4. Thanks for the feedback and yes, he hear you and will look into it.- Anonymous
November 17, 2016
Yes, this is something that's really needed, particularly when you add Azure SQL DB into the same mix.Any feature that can be enabled/disabled should have a SERVERPROPERTY (or ideally a DATABASEPROPERTY instead) that indicates whether or not it's currently available. Because even checking versions, etc. isn't enough. Full text or R or, etc, etc. might be installed or might not be installed whether or not they are available in the edition.
- Anonymous
- Anonymous
- Anonymous
November 16, 2016
I am looking for the exact syntax for USE HINT.Is it OPTION(USE HINT'9481') if I want to run the query using the legacy CE?Chris- Anonymous
November 16, 2016
Hi Chris it should be OPTION(USE HINT ('FORCE_LEGACY_CARDINALITY_ESTIMATION')). Please look at the query hint BOL page for details https://msdn.microsoft.com/en-us/library/ms181714.aspx
- Anonymous
- Anonymous
November 16, 2016
Thanks for a detailed answer.The build will have to do for 2016. Our customers are running on Enterprise or Standard Edition from 2008R2 upwards. We've used SERVERPROPERTY('EngineEdition') IN ( 3, 5, 6 ) thus far, so we'll augment the UDF to inquire of the build, too. I guess I wouldn't be the only one interested in a feature-level SERVERPROPERTY breakout for multi-version deployment challenges...I'm stunned and thankful we can migrate customers from 2012 Enterprise to 2016 Standard so easily, in both those ways - restore being the most surprising advance. Many thanks to the Team for that one! The KB is eagerly awaited as we had to address just this situation only yesterday...Thank you. (It's beginning to look a lot like Christmas)- Anonymous
November 16, 2016
Can you log a connect item and share it. If there is enough customer interest, we can prioritize it. Thanks for your feedback and we are equally excited about the release.- Anonymous
November 16, 2016
Done! Hoping for traction :)https://connect.microsoft.com/SQLServer/feedback/details/3111773
- Anonymous
- Anonymous
- Anonymous
November 16, 2016
Hi,The new features available in standard edition are limited to the list in the image above ? Other features such as online index rebuild are still only available in enterprise edition ?- Anonymous
November 16, 2016
Hi Dennes, yes that's true.
- Anonymous
- Anonymous
November 16, 2016
Does SQL 2016 SP1 support Transparent Data Encryption feature for other SQL server edition rather Enterprise edition- Anonymous
November 16, 2016
TDE is Enterprise edition only.- Anonymous
June 05, 2017
Hi Parikshit,I'd like to ask if in MSSQL 2016 only the Enterprise edition supports TDE? How about the Developer edition?- Anonymous
June 05, 2017
Both Enterprise and Dev edition supports TDE.
- Anonymous
- Anonymous
- Anonymous
- Anonymous
November 17, 2016
Is there any full ISO installer with SP1 included?- Anonymous
November 17, 2016
It should be released shortly in the usual download channels where you already download other SQL Server ISOs.
- Anonymous
- Anonymous
November 17, 2016
"SQL Server 2016 SP1 also includes all the fixes up to SQL Server 2016 RTM CU3 including Security Update MS16–136."When did SQL Server 2016 RTM CU3 come out?- Anonymous
November 17, 2016
It will very shortly. MS16–136 also includes CU3 (it will be the same build).- Anonymous
November 17, 2016
Please refer to this KB for more details https://support.microsoft.com/en-us/kb/3205413
- Anonymous
- Anonymous
- Anonymous
November 17, 2016
Hi,The Standard edition supports fine grained auditing, so we can configure Database Audit Level on Standard edition SQL Server 2016 SP1, and without any restrictions?Thank you,Daniel - Anonymous
November 17, 2016
Well done. This is really huge news and just what we needed. - Anonymous
November 17, 2016
Well done. This is really huge news and just what we needed. Could you clarify if advanced scanning (merry-go-round scanning) is still Enterprise only?- Anonymous
November 18, 2016
Yes, you should not expect performance/scale enhancements, as the purpose in SP1 feature adds is to standardize programming language surface area.
- Anonymous
- Anonymous
November 17, 2016
Will the Microsoft OLEDB Provider for DB2 be available in 2016.1 Standard now?- Anonymous
December 28, 2016
The Microsoft OLEDB Provider for DB2 is available in the SQL Server 2016 Feature Pack on Microsoft Downloads: https://www.microsoft.com/en-us/download/details.aspx?id=52676
- Anonymous
- Anonymous
November 17, 2016
Is the Resource Governor still limited to Enterprise Edition or is it also available in Standard Edition?- Anonymous
November 17, 2016
The scope was to have a consistent programmability surface area between Enterprise and Standard Editions. This is so application developers have a way to program an application in the same way using all the features of SQL Server regardless of which edition the app may eventually be deployed on. Resource governor is a operational/scalability requirement not programmability requirement.
- Anonymous
- Anonymous
November 17, 2016
ONLINE Index rebuild. Please add this feature in standard edition at least as this is one of the highly required features- Anonymous
November 17, 2016
The scope was to have a consistent programmability surface area between Enterprise and Standard Editions. This is so application developers have a way to program an application in the same way using all the features of SQL Server regardless of which edition the app may eventually be deployed on. Online index operations are therefore an operational requirement not programmability requirement.- Anonymous
November 18, 2016
how does Compression represent a difference in the programmability surface area?- Anonymous
November 18, 2016
Reasoning is that it defines an object (DDL) and as such would require differences in code development and deployment.
- Anonymous
- Anonymous
- Anonymous
- Anonymous
November 17, 2016
What's memory limit for the Expression edition in SP1?- Anonymous
November 17, 2016
Memory limit for Express Edition is 1GB. you can find more information on scale limits below https://msdn.microsoft.com/en-us/library/cc645993(v=sql.130).aspx
- Anonymous
- Anonymous
November 18, 2016
Hi All,about SSAS there are some improvements in the Standard edition?We use a lot of advanced feature of SSAS for multidimensional models that we had in the Business Intelligence edition of SQL 2012/2014 and for using that with SQL 2016 we need to use Enterprise ediiton that is much more expensive.If you have add some advanced features also in the standard edition of SQL 2016 SP1, it will be a great news.Thanks- Anonymous
November 18, 2016
All the SSAS improvements for SP1 are covered in the following blog post https://blogs.msdn.microsoft.com/analysisservices/2016/11/17/improving-analysis-services-performance-and-scalability-with-sql-server-2016-service-pack-1/
- Anonymous
- Anonymous
November 18, 2016
Does SP1 fix the imposibilty to install on Windows Server 2008 R2 or Windows 7? This is the main bug in SQL Server 2016. Take note that vast mayority of users don't like a spyware and featured limited OS's with a nightmare mobile and very, very, very ugly user interface like Windows 8.x, Windows 10, Windows Server 2012 or Windows Server 2016.- Anonymous
November 18, 2016
SQL Server 2016 SP1 does not change any of the hardware or software requirements as listed in https://msdn.microsoft.com/en-us/library/ms143506.aspx.- Anonymous
November 18, 2016
Wating for fixing this in SQL Server or fixing the Windows 10 or Windows Server 2013/2016 ugly user interface nightmare, removing spyware, suggestions (called ADS in real world), and all mobile and unusefull UWP apps.- Anonymous
November 18, 2016
Thank you for the feedback. As you might understand, you just enumerated Windows Server topics that are not addressable in SQL Server itself.
- Anonymous
- Anonymous
November 21, 2016
Please, do add support for Windows 7.We cannot use the latest versions of SQL Server (Express).- Anonymous
November 21, 2016
Please upgrade to one of the minimum supported operating system versions. You can see how to use SQL Server in Windows 8 and later versions of Windows operating system in https://msdn.microsoft.com/en-us/library/mt790215.aspx.
- Anonymous
- Anonymous
- Anonymous
- Anonymous
November 18, 2016
Thanks for this great release ! We now really need an edition downgrade option in the SP1 installation process. At the moment the only way to do such an edition downgrade is to completely uninstall and reinstall. I'm thinking the SP1 installation should detect that such a downgrade is possible and offer it as an installation option. - Anonymous
November 18, 2016
This is great! I used to completely ignore news about enterprise-only features. It's exciting that the programmability experience will now be the same for all editions. - Anonymous
November 18, 2016
Upgrading from RTM CU2 build 2164 to SP1 build 4001 reset the DCOM permissions for SSIS service just like in https://support.microsoft.com/en-ca/kb/2000474Do I need to raise a Connect item?Chris- Anonymous
November 18, 2016
Thanks Chris for bringing this to our notice.Let me check and get back to you. In either case, you will not need to raise a connect item for this.- Anonymous
November 18, 2016
Would this be the reason why I'm suddenly getting this error message for published SSIS projects executing via SQL Agent jobs after upgrade from CU2 to SP1?Warning: Could not open global shared memory to communicate with performance DLL; data flow performance counters are not available. To resolve, run this package as an administrator, or on the system's console. - Anonymous
November 24, 2016
Parikshit,Any news on this issue? I noticed its not in the list of SP1 issue blog entry.Chris- Anonymous
November 24, 2016
Sorry I can see it mentioned in the SP1 issue blog now.Chris
- Anonymous
- Anonymous
- Anonymous
- Anonymous
November 18, 2016
Was the need for NF 3.5 removed if you wanted to use Database Mail? I had seen this was needed for SQL 2016 RTM.ThanksChris- Anonymous
November 18, 2016
Hi Chris, That requirement hasn't changed yet even with SQL 2016 SP1.
- Anonymous
- Anonymous
November 19, 2016
The comment has been removed- Anonymous
November 28, 2016
Hello Paul, please refer to your account manager for licensing questions. About functionality, you can use a SQL 2012 EE DB in SQL 2016 SE SP1, if the feature is listed in the above table.
- Anonymous
- Anonymous
November 21, 2016
Hi,The following description is in the In-Memory Column Store at https://msdn.microsoft.com/en-us/library/cc645993.aspx.=========The max degrees of parallelism is limited. The degrees of process parallelism (DOP) for an index build is limited to 2 DOP for the Standard Edition and 1 DOP for the Web and Express Editions.=========I tried to confirm by index creation and search.CREATE / ALTER NCCIndex : DOP = 1SELECT NCCIndex : DOP = 2When creating / rebuilding an index, DOP = 1 is restricted, and if parallel processing can be performed using an index by search etc., is DOP = 2 restricted? - Anonymous
November 21, 2016
Does this have the fix for https://support.microsoft.com/en-nz/kb/3185365 also wrapped into this ?- Anonymous
November 21, 2016
The issue is fixed in ODBC 13.1 which is a separate download which you can find here https://www.microsoft.com/en-us/download/details.aspx?id=53339- Anonymous
November 21, 2016
Thank you Parikshit. If it is not included in SP1, does that mean we have to keep re-deploying the ODBC 13.1 fix every time we apply a service pack ? Even subsequent service packs. Or is the ODBC never a part of the SQL install package and we dont have to worry about it once we deploy ODBC13.1 ?We are running SQL 2012/2014/2016 clustered instances(One each), all on the same server. Installing SQL 2016 broke ODBC and we cannot start SQL Agent on the 2016 instance.- Anonymous
November 21, 2016
The comment has been removed- Anonymous
November 21, 2016
Parikshit - Thanks very much. That was helpful. I had already installed SP1, which would not let me deploy the ODBC13.1 package. I had to uninstall the ODBC 13.1 drivers from Programs and features, and install using the package. I am able to start SQL Agent now. Curious thing though - if you download the file "13.1.811.168\x86\msodbcsql.msi" from https://www.microsoft.com/en-us/download/details.aspx?id=53339, it will not install. I used the file named "13.1.811.168\amd64\msodbcsql.msi" and it works. I guess this is the correct 64 bit version, but what does AMD stand for in "amd64"?- Anonymous
November 21, 2016
amd64 is a processor architecture but that is the right version for x64 bit servers.
- Anonymous
- Anonymous
November 26, 2016
A bit of history about AMD64: At the end of the 1990s, there were two major processor architectures proposed by Intel: Pentiums and Itaniums. Pentiums were 32 bits and Itaniums were 64 bits. The instruction sets of those chips were also called "IA-32" and "IA-64" (IA=Intel Architecture). IA-32 was compatible with pentiums and also older processors: 8086, 286, 386, 486. So Microsoft named the 32 bit architecture x86. And they kept the name IA64 for the 64 bit architecture. Big problem: the Itanium could not run any 32 bit program. It was a pure 64 bit architecture. (It could run 32 bit programs in a software emulator, but the emulator was so slow that it was considered unusable for anything complex).In 2003, AMD created a new architecture that could load a 64 bits OS AND would run 32 bits processes inside. This architecture was called AMD64 or x64. It was a hybrid architecture, not a pure 64 bit architecture. This was so popular that even Intel created a new generation of processors that were compatible with this architecture. The last version of Windows that supported Itanium was Windows Server 2008 R2. IA-64 is now considered a legacy technology. Windows still comes in a few architectures: AMD64 (or X64) is the mainstream version, X86 (or IA32) is the small memory version (small form factors, Atom-based tablets), ARM is the version for Phone, Windows Mobile, and Windows Internet of Things (IoT).
- Anonymous
- Anonymous
- Anonymous
- Anonymous
- Anonymous
November 21, 2016
Does this remove the 10GB database limit in Express Edition?- Anonymous
November 21, 2016
Nope that doesn't change.- Anonymous
November 21, 2016
It really needs to :( At least up it to something more realistic these days. Consider an ISV who deploys with SQL Express to small business (and I mean small) once they hit that limit, which is quite easy to do in 2016, it's a 3,000 upgrade to Standard? You killed the Workgroup SKU which made this at least feasible, but this is too big of a leap. - Anonymous
November 22, 2016
Even with compression on?- Anonymous
November 22, 2016
Yes..you can turn on compression but limits doesn't change.- Anonymous
November 22, 2016
It's still not clear if the 10GB limit is after compression or before. In the former case, the database can be slightly larger. For exemple a 15GB not compressed database can become a 10GB compressed database.- Anonymous
November 22, 2016
10GB is the hard limit for the database size with or without compression. So if you have tables compressed and total size of the database size is 10GB, you wont be able to uncompress them else it will result in errors. If you have uncompressed tables which is reaching 10GB limit, In this case you can choose to compress few tables to create some additional room for new data but once you hit the 10GB limit, the database cannot be expanded. Hope that clarifies.
- Anonymous
- Anonymous
- Anonymous
- Anonymous
- Anonymous
- Anonymous
November 21, 2016
Is there any chance we'll see Indexed Views work without needing Query Hints in lower SKUs? This is still something of a pain point for targeting different versions since you either have to force it (potentially undermining the Enterprise SKU's optimizer) or accept that Indexed Views will go unused on lower SKUs (making them unnecessary overhead).- Anonymous
November 28, 2016
Hello Andy, you should not expect performance/scale enhancements (such as automatic use of indexed views), as the purpose in SP1 feature adds is to standardize programming language surface area.- Anonymous
November 30, 2016
Yes, I thought that was the case but am still hoping it might be reconsidered as it breaks the "ode can be used everywhere" principle. If you create indexed views, but don't include the NOEXPAND hint, then you take a not insignificant penalty (both in terms of speed and storage) when running on non-Enterprise systems because you're creating indexes the system can never use. Given that customers running on lower SKUs typically have less resources (either because of cost reasons or because lower SKUs have physical size/CPU limits) that tends to be an unacceptable trade off.However, if you add the NOEXPAND hints, then SQL Server will use the indexes on all SKUs (which is mostly good) but it feels like you're entirely undermining SQL Server Enterprise's entire automatic usage mechanism, since you're now forcing Enterprise SKUs to use the index regardless. Your code "runs everywhere" but at the cost of effectively disabling the feature.Currently it seems the only way to avoid this is to have separate query code (or conditionally create the indexes) depending on whether your application is connected to an Enterprise SKU, but that's precisely what this is supposed to avoid, isn't it?
- Anonymous
- Anonymous
- Anonymous
November 21, 2016
Hey, so does this mean anything for SQL Azure users? Will we get Columnstore support in standard servers instead of only premium now?- Anonymous
November 21, 2016
Hi Graham, these improvements are only for on-prem release of SQL Server. There are no changes in SQL Azure.- Anonymous
November 22, 2016
Azure Stack, too? No change, or we get to share in the joy?
- Anonymous
- Anonymous
- Anonymous
November 22, 2016
SQL 2016 was not supported on Windows 7 but I see it there in SP1 supported platforms. Has that changed?https://www.microsoft.com/en-us/download/details.aspx?id=54276- Anonymous
November 22, 2016
That's not changed. It is was a documentation issue which is fixed now.
- Anonymous
- Anonymous
November 23, 2016
The comment has been removed - Anonymous
November 23, 2016
Is there any E.T.A. on an iso for SQL 2016 INCLUDING SP1? MSDN appears bereft and the 2016 download doesn't yet appear to include the SP1 bits, unless en_sql_server_2016_service_pack_1_x64_dvd_9542248.iso contains not just the SP1 bits. The "details" link for this file merely shows subscription levels, not what the file actually contains, or its size (if 551MB, then SP1, if > 2GB, then everything, it seems)Thanks for the clarification.- Anonymous
November 23, 2016
Yes we are working on it. With holidays around the corner things are bit slow on our end but you should see it by 1st week of December.
- Anonymous
- Anonymous
November 23, 2016
Excelent!!!!! - Anonymous
November 24, 2016
I can't find any LocalDb with this newest service pack to download. The current SQL Express Link is still without the Service Pack: https://www.microsoft.com/en-us/download/details.aspx?id=52679Will this be updated as well?- Anonymous
November 24, 2016
You can find it here https://www.microsoft.com/en-us/download/details.aspx?id=54284
- Anonymous
- Anonymous
November 24, 2016
Fantastic.Now, how do I apply this service pack to the SQL 2016 localdb that was installed by Visual Studio 2015 on my Windows 7 Enterprise machines?Andrew - Anonymous
November 28, 2016
The comment has been removed- Anonymous
November 28, 2016
Hello Paul, please file connect items with your scenario details. Thanks!
- Anonymous
- Anonymous
March 07, 2017
I'm using 2008 R2 Dev edition for table partitioning.so 2016 Sp1 std edition supports partitioning.Can I restore my database in 2008 R2 dev edition to 2016 SP1 std?- Anonymous
March 14, 2017
Yes, you should be able to restore your database to 2016 SP1 std edition.
- Anonymous
- Anonymous
March 15, 2017
I am wondering if you could provide the direct download URLs for the core engine and LocalDB of SQL Server 2016 SP1 Express. We have a need to create our own bootstrap that installs the core engine or LocalDB of SQL Server Express depending on the edition of our product prior to our product installation. We need to download the payload from web during the installation and install SQL Server Express silently. The Basic Installer does not suite for our needs.Thanks.- Anonymous
March 26, 2017
Using the SSEI you can choose to download the media only. Does that work for your intent?- Anonymous
March 27, 2017
The comment has been removed- Anonymous
March 27, 2017
Yes, it is supported. Refer following KB for more details https://support.microsoft.com/en-us/help/3192738/sql-server-2016-installer-updatesUsage: SQLServer2016-SSEI-Expr.exe [/ConfigurationFile=C:\Configuration.ini] [/IAcceptSqlServerLicenseTerms] [/MediaPath=C:\SqlServer2016Setup] [/ENU]- Anonymous
March 29, 2017
Thank you for the information. That is very helpful!!
- Anonymous
- Anonymous
- Anonymous
- Anonymous
- Anonymous
April 23, 2017
This is great! I used to completely ignore news about enterprise-only features. It’s exciting that the programmability experience will now be the same for all editions. - Anonymous
May 24, 2017
Great stuff thanks for sharing! The SQL Server 2016 Service Pack 1 is beginning to clear up. As I found another helpful post for the same see http://www.sqlmvp.org/sql-server-2016-service-pack-1-features/