Diagnosing .NET Core ThreadPool Starvation with PerfView (Why my service is not saturating all cores or seems to stall).
This article is worth a read if you have
- A service written in .NET (and in particular .NET ASP.NET Core)
- Its ability to service incoming load has topped out
- But the machine's CPUs are not fully utilized (often only using a small fraction of the total available CPU
In extreme cases, the loss of throughput is so bad that the service does not seem to be making progress at all. More commonly, you just are getting the throughout you expect, or you can't handle 'bursts' of load. (thus works great in stead state at 20% CPU used, but when you get a burst, it does not use more CPU to service the burst).
What these general symptoms tell you is that you have a 'bottleneck' but it is not CPU. Basically there is some other resource that is needed to service a request, that each request has to wait for, and it is this waiting that is limiting throughput. Now the most common reason for this is that the requests require the resources on another machine (typically a database, but it could be a off-machine cache (redis), or any other 'out of process' resource). As we will see, these common issues are relatively straightforward because we can 'blame' the appropriate component. When we look at a breakdown of what why a request takes so long, we will clearly see that some part (e.g. waiting on a response from a database), takes a long time, so we know that that is the issue.
However there is an insidious case, which is that the 'scarce resource' are threads themselves. That is some operation (like a database query), completes, but when it does there is no thread that can run the next step in servicing the request, so it simply stalls, waiting for such a thread to become available. This time shows up as a 'longer' database query, but it also happens any time non-CPU activity happens (e.g. any I/O or delay), so it seems like very I/O operation randomly takes longer than it should. We call this problem ThreadPool starvation, and it is the focus of this article.
In theory threadpool starvation was always an potential problem, but as will be explained, before the advent of high scale, asynchronous services, the number of threads needed was more predictable, so the problem was rare. With more high scale async apps, however, the potential for this problem has grown, so I am writing this article to describe how to diagnose if this problem is affecting your service and what to do about it if it is. But before we can do that, some background is helpful
What is a ThreadPool?
Before we talk about a threadpool, we should back and describe what a Thread is. A Thread is the state needed to execute a sequential program. To a good approximation it is the 'call-stack' of partially executed methods, including all the local variables for each of those methods. The key point is that all code need s thread to 'run-in'. When a program starts it is given a thread, and multi-threaded programs create additional threads which each execute code concurrently with each other.
Threads make sense in a world where the amount of concurrency is modest, each thread is doing a complex operation. However some workloads have exactly the opposite characteristics: there are MANY concurrent things happening, and each of them are doing simple things. Since all execution needs a thread, for this workload, it makes sense to reuse the thread, having it execute many small (unrelated) work items. This is a threadpool. It has a very simple API. In .NET it is ThreadPool.QueueUserWorkItem that takes a delegate (method) to run. When you call QueueUserWorkItem, the threadpool promises to run the delegate you passed some time in the future. (Note .NET does not encourage direct use of thread pool. Task.Factory.StartNew(Action) also queues methods to the .NET threadpool but makes it much easier to deal with error conditions and waiting on the result).
What is a Asynchronous Programming?
In the past, services used a 'multi-threaded' model of execution, where the service would create a thread for each concurrent request being handled. Each such thread would do all the work for that particular request from beginning to end, then move on to the next. This works well for low to medium scale serviced, but because a thread is a relatively expensive item (generally you want less than 1000 of them, and preferably < 100), this multi-threaded model does not work well if you want your service to be able to handle 1000s or 10000s of requests concurrently.
To handle such scale, you need an Asynchronous style of programming and ASP.NET Core is built with this architecture. In this model, instead of having a 'thread per concurrent request', you instead register callbacks when you do long operations (typically I/O), and reuse the thread to do other processing while you are waiting. This architecture means that just a handful of threads (ideally about the number of physical processors), can handle a very large number (1000s or more) concurrent requests. You can also see what asynchronous programming needs a threadpool, because as I/Os complete, you need to run the next 'chunk' of code, so you need a thread. Asynchrounous code uses the threadpool to get this thread run this small chunk of code, and then return the thread to the pool so the thread can run some other (unrelated) chunk.
Why do High-scale Asynchronous Services have Problems with ThreadPool Starvation?
When your whole service uniformly uses the asynchronous style of programing, then your service scales VERY well. Threads NEVER block when running service code because if the operation takes a while, then the code should have called a version that takes a callback (or returns a System.Threading.Tasks.Task) and causes the rest of code to run when the I/O completes (C# has a magic 'await' statement that looks like it blocks, but in fact schedules a callback to run the next statement when the await statement completes). Thus threads never block except in the threadpool waiting for more work, so only a modest number of threads are needed (basically the number of CPUs on the machine).
Unfortunately, when your service is running at high scale, it does not take much to ruin your perf. For example imagine you had 1000 concurrent requests being processed by a 16 processor machine. Using async, the threadpool only needs 16 threads to service those 1000 requests. For the sake of simplicity, that the machine has 16 CPUs and the threadpool has only one thread per CPU (thus 16) Now lets imaging that someone places a a Sleep(200) at the start of the request processing. Ideally you would like to believe that that would only cause each request to be delayed by 200 msec and thus having a response time of 400 msec. However the threadpool only has 16 threads (which was enough when everything was async), which, all of a sudden, it is not enough. Only the first 16 threads run, and for 200 msec are just sleeping. Only after 200 msec are those 16 threads available again, so another 16 requests can go etc. Thus the first requests are delayed by 200 msec, the second set for 400msec, the third by 600 msec. The AVERAGE response time to does up to over 6 SECONDS for a load of 1000 simultaneous requests. Now you can see why in some cases throughput can go from fine to more than terrible with just a very small amount of blocking.
This example is contrived, but it illustrates the main point. if you add ANY blocking, the number of threads needed in the threadpool jumps DRAMATICALLY (from 16 to 1000). The .NET Threadpool DOES try to inject more threads, but does it at a modest rate (e.g 1 or 2 a second), so it makes little difference in the short term (you need many minutes to get up to 1000). Moreover, you have lost the benefit of being async (because now you need roughly a thread per request, which is what you were trying to avoid).
So you can see there is a 'cliff' with asynchronous code. You only get the benefits of asynchronous code if you 'almost never block'. If you DO block, and you are running at high scale, you are very likely to quickly exhaust the Threadpool's threads. The threadpool will try to compensate, but it will take a while, and frankly you lost the benefits of being async. The correct solution is to avoid blocking on the 'hot' paths in an high scale service.
What typically causes blocking?
The common causes of blocking include
- Calling any API that does I/O (thus may block) but is not Async (since it is not an Async API, it HAS to block if the I/O can't complete quickly)
- Calling Task.Wait() or Task.GetResult (which calls Task.Wait). Using these APIs are red flags. Ideally you are in an async method and you use 'await' instead.
So in a nutshell, this is why threadpool starvation is becoming more common. High scale async application are becoming more common, and it is very easy to introduce blocking into your service code, which forces you off the 'golden path' for async, requiring many threadpool threads, which cause starvation.
How do I know that the ThreadPool is starved for threads?
So how do you know this bad thing is happening? You start with the symptoms above, which is that your CPUs are not as saturated as you would want. From here I will show you a number of symptoms that you can check that give ever more definitive answer to the question. The details do change depending in the operating system. I will be showing the windows, case but I will also describe what to do on Linux.
As always, whenever you have a problem with a service, it is useful get a detailed performance trace. On windows this means downloading PerfView taking a PerfView Trace
- PerfView /threadTime collect
On Linux it currently means taking a trace with perfCollect however in release 2.2 of .NET Core you will be able to collect traces using a 'dotnet profile' command (details are TBD, I will update when that happens).
If you are using Application Insights, you can use the Application Insights profiler to capture a trace as well.
You only need 60 seconds of trace when the service is under load but not performing well.
Look for growing thread count.
A key symptom of threadpool starvation is the fact that the threadpool DOES detect that it is starved (there is work but no threads), and is trying to fix it by injecting more threads, but does it (by design) at a slow rate (about 1-2 times a second). Thus In PerfView's 'events view' (on windows), you will see the OS kernel events for new threads showing up at that rate. Notice that it adds about 2 threads a second.
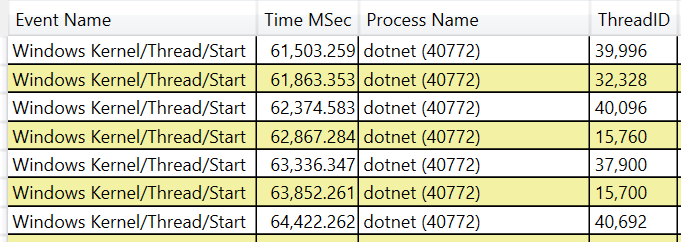
Linux traces don't include OS events in the 'events' view but there are .NET Runtime events that will tell you every time a thread is created. You should look at the following events
- Microsoft-Windows-DotNETRuntime/IOThreadCreation/Start - windows only (it has a special queue for threads blocked on certain I/O) for new I/O workers
- Microsoft-Windows-DotNETRuntime/ThreadPoolWorkerThread/Start - logged on both Linux and Windows for new workers
- Microsoft-Windows-DotNETRuntime/ThreadPoolWorkerThreadAdjustment/Adjustment - indicates normal worker adjustment (will show increasing count
Here is an example of what you might see on Linux.
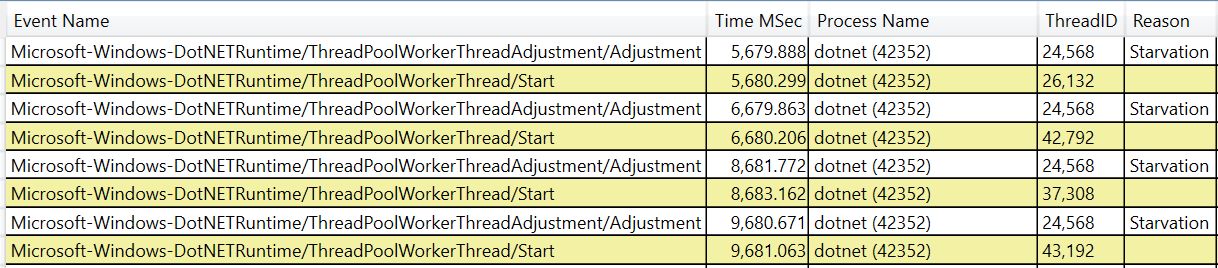
This will continue indefinitely if the load is high enough (and thus the need for more threads is high enough). It may also show up in OS performance metrics that count threads in a given process. (so you can do it without PerfView at all if necessary).
Finding the blocking API
If you have established that you do have a threadpool starvation problem, as mentioned the likely issue is that you called a blocking API that is consuming a thread for too long. On windows, PerfView can show you where you are blocking with the 'Thread Time (with StartStop Activities) view". This view should show you all the service requests in the 'Activities' node, and if you look at these, you should see a pattern of 'BLOCKED_TIME" being consumed. The API that causes that blocking is the issue.
Unfortunately this view is not available on Linux today using 'perfCollect'. However the application insights profiler should work and show you equivalent information. In version 2.2 of the runtime the 'dotnet profile' should also work (TBD) for ad-hoc collection.
Be Proactive.
Not that you don't need to wait for your service to melt down to find 'bad blocking' in your code. There is nothing stopping you from running the PerfView /Collect on your development box on just about ANY load, and simply look for blocking. That should be fixed. You don't need to actually induce a high-scale environment and see the threadpool starvation, you know that that will happen if you have large scale (1000s of concurrent requests), and you block for any length of time (even 10msec is too much, if it is happening on every request). Thus you can be proactive and solve the problem before it is even a problem.
Work-around: Force more threads in the ThreadPool
As mentioned already, the real solution to thread-pool starvation is to remove the blocking that consuming threads. However you may not be able to modify the code to do this easily, and need SOMETHING that will help in the very short term. The ThreadPool.SetMinThreads can set the minimum number of threads for the ThreadPool (on windows there is a pool for I/O threads and a pool for all other work, and you have to see from your trace which kind of thread is being created constantly to know which to set). The normal worker thread minimum can also be set using the environment variable COMPlus_ForceMinWorkerThreads, but there is not environment variable for the I/O threadpool (but that only exists on Windows). Generally this is a bad solution because you may need MANY threads (e.g. 1000 or more), and that is inefficient. It should only be used as a stop-gap measure.
Summary:
So now you know the basics of .NET ThreadPool Starvation.
- It is something to look for when you service is not performing well and CPU is not saturated.
- The main symptom is a constantly increasing number of threads (as the threadpool tries to fix the starvation)
- You can determine things more definitively by looking at .NET runtime events that show the threadpool adding threads.
- You can then use the normal 'thread time' view to find out what is blocking during a request.
- You can be proactive and look for blocked time BEFORE at-scale deployment, and head off these kinds of scalability issues.
- Removing the blocking is best, but if not possible increasing the size of the ThreadPool will at least make the service function in the short term.
There you have it. Sadly this is become more common than we would like. We are likely to add better diagnostic capabilities to make this easier to find, but this blog entry helps in the mean time.
Va