Record deletes on referenced tables and deadlocks
While troubleshooting some intermittent deadlocking in one of my databases I was surprised to learn that both commands were deleting single rows from different tables and both lookups were on indexed values. The commands were table scanning and deadlocking on a seemingly unrelated resource in another table.
After digging in I discovered a chain of triggers and foreign key references with cascade deletes leading back to the deadlocked table, but it still didn't answer why they were deadlocking in the first place and needed a bit more investigation.
Here's what was happening using an example table pair:
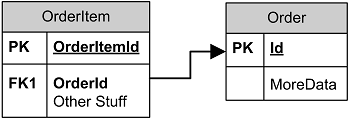
Possible Actions on the Order Table
- Insert a record: No problem, just a normal singleton insert
- Update a record: No problem if we are not modifying the value for Id. If we are, then I'd question the underlying database design
- Deleting a record: Here's the problem. Deleting an Order means that SQL needs to check for matching values in OrderItem.OrderID and delete them (cascade delete), or raise an error if it does.
If there's no index on OrderId, then SQL must do a table scan on OrderItem every time we delete a row from Order which takes time and can do deadlock-happy activity like taking range X-X locks . The simple solution to this is creating a nonclustered index on OrderId:
CREATE NONCLUSTERED INDEX NCI_OrderITem_OrderID
ON OrderItem(OrderId)
This solves it but raises the question of how many other referencing columns have the same problem. I created a query to look for columns that reference other tables and wasn't the first column in an index. I didn't want the overhead of maintaining a indexes that would never be used, so I restricted it to reference only tables with delete activity. This is what I came up with:
Finding Missing Foreign Key Indexes
--Run this from the database you are interested in
--Each delete shown in the output represents a table scan on the referencing table
WITH ic AS (SELECT sic.object_id, sic.column_id
FROM sys.index_columns sic
WHERE key_ordinal=1
)
SELECT object_name(fkc.parent_object_id) 'Referencing_table',
sc.name 'Referencing_Column',
object_name(fkc.referenced_object_id) 'Referenced_Table',
object_name(fkc.constraint_object_id) 'FK_Constraint_Name',
ios.leaf_delete_count,ios.nonleaf_delete_count
from sys.foreign_key_columns fkc
JOIN sys.dm_db_index_operational_stats (db_id(), NULL, NULL, NULL) ios ON (fkc.referenced_object_id = ios.object_id)
LEFT JOIN ic ON (fkc.parent_object_id = ic.object_id AND fkc.parent_column_id = ic.column_id)
JOIN sys.columns sc ON (fkc.parent_object_id = sc.object_id AND fkc.parent_column_id = sc.column_id)
where 1=1
AND ic.object_id IS NULL
AND ios.index_id in (0,1)
AND (ios.leaf_delete_count > 0 OR ios.nonleaf_delete_count > 0)
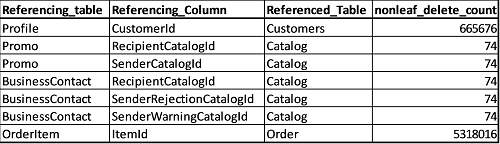
What the query returns
We get a result set similar to the following (*two columns omitted):
Conclusion
Over 5 million deletes from order and with each causing a table scan on OrderItem, and 665000 deletes from customers each causing a table scan on Profile regardless of whether the delete even cascaded.
The 74 deletes from Catalog cause the same problem, but here we get into the question of whether the overhead of maintaining an additional 5 indexes would be worth the benefit. For Profile and OrderItem it was a no-brainer to add nonclustered indexes to the CustomerId and ItemId columns.