Document Intelligence 讀取模型
重要
- 文件智慧服務公開預覽版本可讓您搶先存取正在積極開發的功能。
- 根據使用者意見反應,功能、方法和流程在正式發行 (GA) 前可能有所變更。
- 文件智慧服務用戶端程式庫的公開預覽版本預設為 REST API 版本 2024-02-29-preview。
- 公開預覽版本 2024-02-29-preview 目前僅適用於下列 Azure 區域:
- 美國東部
- 美國西部 2
- 西歐
此內容適用於:![]() v3.1 (GA) | 最新版本:
v3.1 (GA) | 最新版本:![]() v4.0 (預覽版) | 舊版:
v4.0 (預覽版) | 舊版:![]() v3.0
v3.0
此內容適用於:![]() v3.0 (GA) | 最新版本:
v3.0 (GA) | 最新版本:![]() v4.0 (預覽版)
v4.0 (預覽版) ![]() v3.1
v3.1
注意
如需從標籤、街道符號和海報等外部影像擷取文字,請使用 Azure AI 影像分析 v4.0 讀取功能,此功能已使用效能增強同步 API 針對一般非文件影像進行最佳化,讓您更輕鬆地在使用者體驗案例中內嵌 OCR。
Document Intelligence 的讀取光學字元辨識 (OCR) 模型會以高於 Azure AI 視覺讀取的解析度執行,並擷取 PDF 文件和掃描影像中的列印和手寫文字。 其同樣也包含擷取 Microsoft Word、Excel、PowerPoint 及 HTML 文件中文字的支援。 它會偵測段落、文字行、字組、位置和語言。 讀取模型是其他 Document Intelligence 預建模型的基礎 OCR 引擎,例如版面配置、一般文件、發票、收據、身分識別 (ID) 文件、醫療保險卡、W2 (聯邦報稅表) 以及自訂模型。
什麼是文件的 OCR?
文件的光學字元辨識 (OCR) 已針對多種檔案格式及全域語言中的大型文字密集文件進行最佳化。 它包含更高解析度的文件影像掃描等功能,可以更妥善地處理較小且密集的文字、段落偵測,以及可填寫的表單管理。 OCR 功能也包括單一字元方塊等進階案例,還能精確擷取發票、收據及其他預先建置案例中常見的索引鍵欄位。
開發選項
文件智慧服務 v4.0 (2024-02-29-preview、2023-10-31-preview) 支援下列工具、應用程式和程式庫:
| 功能 | 資源 | Model ID |
|---|---|---|
| 讀取 OCR 模型 | • 文件智慧服務工作室 • REST API • C# SDK • Python SDK • JAVA SDK • JavaScript SDK |
prebuilt-read |
文件智慧服務 v3.1 支援下列工具、應用程式和程式庫:
| 功能 | 資源 | Model ID |
|---|---|---|
| 讀取 OCR 模型 | • 文件智慧服務工作室 • REST API • C# SDK • Python SDK • JAVA SDK • JavaScript SDK |
prebuilt-read |
文件智慧服務 v3.0 支援下列工具、應用程式和程式庫:
| 功能 | 資源 | Model ID |
|---|---|---|
| 讀取 OCR 模型 | • 文件智慧服務工作室 • REST API • C# SDK • Python SDK • Java SDK • JavaScript SDK |
prebuilt-read |
輸入需求
若要得到最佳結果,請為每個文件提供一張清晰的照片或高畫質的掃描檔案。
支援的檔案格式:
模型 PDF 影像:
JPEG/JPG、PNG、BMP、TIFF、HEIFMicrosoft Office:
Word (DOCX)、Excel (XLSX)、PowerPoint (PPTX)、HTML參閱 ✔ ✔ ✔ 版面配置 ✔ ✔ ✔ (2024-02-29-preview、2023-10-31-preview) 一般文件 ✔ ✔ 預建 ✔ ✔ 自訂擷取 ✔ ✔ 自訂分類 ✔ ✔ ✔ (2024-02-29-preview) 若使用 PDF 和 TIFF,最多可處理 2000 頁 (若使用免費層訂閱,則只會處理前兩頁)。
對於付費 (S0) 層,分析文件的檔案大小為 500 MB,對於免費 (F0) 層,則為 4 MB。
影像維度必須介於 50 x 50 像素和 10,000 x 10,000 像素之間。
如果您的 PDF 有密碼鎖定,則必須先移除鎖定才能提交。
針對 1024 x 768 像素影像的擷取文字高度下限為 12 像素。 此尺寸在 150 點/英吋 (DPI) 時大約相當於
8點文字。針對自訂模型定型,自訂範本模型的定型資料頁數上限為 500,而自訂神經網路模型的上限則為 50,000。
針對自訂擷取模型定型,範本模型的定型資料大小總計為 50 MB,而神經模型的大小總計則為 1G-MB。
針對自訂分類模型定型,定型資料的大小總計為
1GB(上限為 10,000 頁)。
開始使用讀取模型
請嘗試使用 Document Intelligence Studio 來擷取表單和文件中的文字。 您需要以下資產:
一個 Azure 訂用帳戶 - 您可以建立一個免費訂用帳戶。
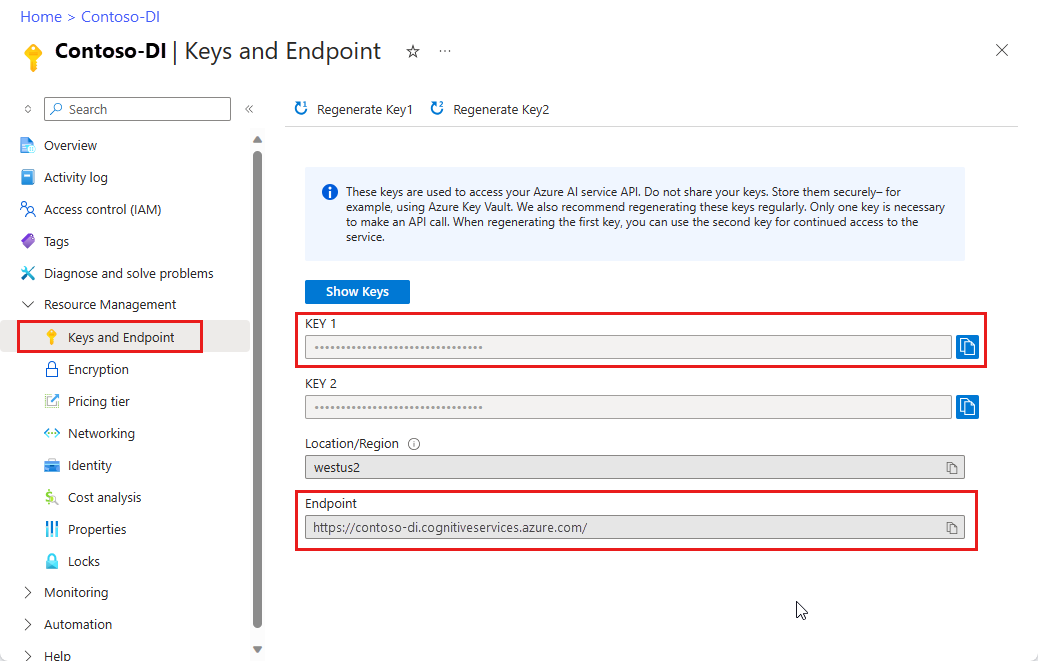
Azure 入口網站中的 Document Intelligence 執行個體。 您可以使用免費定價層 (
F0) 來試用服務。 部署資源後,選取 [前往資源] 以取得金鑰和端點。
注意
Document Intelligence Studio 目前不支援 Microsoft Word、Excel、PowerPoint 和 HTML 檔案格式。
使用 Document Intelligence Studio (英文) 處理的文件範例
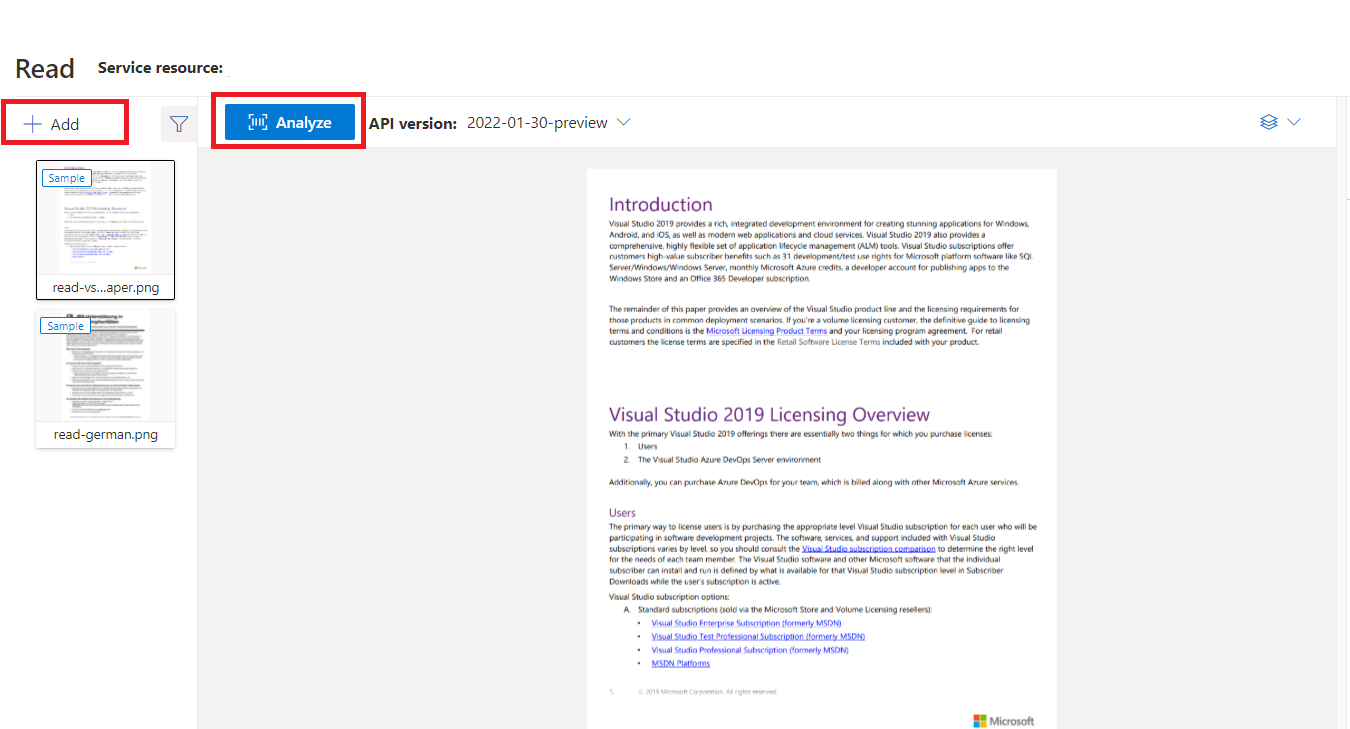
在文件智慧服務工作室首頁上,選取 [讀取]。
您可以分析範例文件,或上傳您自己的檔案。
選取 [執行分析] 按鈕,如有必要,設定 [分析選項]:
![文件智慧服務工作室中 [執行分析] 和 [分析選項] 按鈕的螢幕擷取畫面。](media/studio/run-analysis-analyze-options.png?view=doc-intel-4.0.0)
支援的語言和地區設定
如需支援語言的完整清單,請參閱我們的語言支援 - 文件分析模型頁面。
資料擷取
注意
v3.1 和更新版本中支援 Microsoft Word 和 HTML 檔案。 相較於 PDF 和影像,不支援下列功能:
- 每個頁面物件沒有角度、寬度/高度和單位。
- 針對偵測到的每個物件,沒有週框多邊形或週框區域。
- 不支援頁面範圍 (
pages) 作為參數。 - 沒有
lines物件。
頁面
頁面集合是文件內的頁面清單。 每個頁面都會在文件內循序表示,並包含方向角度,指出頁面是否旋轉,以及寬度和高度 (以像素表示維度)。 會計算模型輸出中的頁面單位,如下所示:
| 檔案格式 | 計算的頁面單位 | 總頁數 |
|---|---|---|
| 影像 (JPEG/JPG、PNG、BMP、HEIF) | 每個影像 = 1 個頁面單位 | 影像總計 |
| PDF 每頁 = 1 個頁面單位 | PDF 總頁數 | |
| TIFF | TIFF = 1 個頁面單位中的每個映像 | TIFF 中的影像總數 |
| Word (DOCX) | 最多 3,000 個字元 = 1 個頁面單位,不支援內嵌或連結的影像 | 總頁數 (每頁最多 3,000 個字元) |
| Excel (XLSX) | 每個工作表 = 1 個頁面單位,不支援內嵌或連結的影像 | 工作表總計 |
| PowerPoint (PPTX) | 每張投影片 = 1 個頁面單位,不支援內嵌或連結的影像 | 投影片總計 |
| HTML | 最多 3,000 個字元 = 1 個頁面單位,不支援內嵌或連結的影像 | 總頁數 (每頁最多 3,000 個字元) |
"pages": [
{
"pageNumber": 1,
"angle": 0,
"width": 915,
"height": 1190,
"unit": "pixel",
"words": [],
"lines": [],
"spans": []
}
]
# Analyze pages.
for page in result.pages:
print(f"----Analyzing document from page #{page.page_number}----")
print(
f"Page has width: {page.width} and height: {page.height}, measured with unit: {page.unit}"
)
# Analyze pages.
for page in result.pages:
print(f"----Analyzing document from page #{page.page_number}----")
print(f"Page has width: {page.width} and height: {page.height}, measured with unit: {page.unit}")
選取頁面進行文字擷取
若為大型的多頁 PDF 文件,請使用 pages 查詢參數來表示文字擷取的特定頁碼或頁面範圍。
段落
文件智慧服務中的讀取 OCR 模型會擷取 paragraphs 集合中所有已識別的文字區塊,以做為 analyzeResults 底下的最上層物件。 此集合中的每個項目都代表一個文字區塊,並包含作為 content 的擷取文字和週框 polygon 座標。 span 資訊會指向包含文件全文檢索的最上層 content 屬性的文字片段。
"paragraphs": [
{
"spans": [],
"boundingRegions": [],
"content": "While healthcare is still in the early stages of its Al journey, we are seeing pharmaceutical and other life sciences organizations making major investments in Al and related technologies.\" TOM LAWRY | National Director for Al, Health and Life Sciences | Microsoft"
}
]
文字、行和字組
讀取 OCR 模型會將列印和手寫樣式的文字擷取為 lines 和 words。 模型會輸出所擷取字組的週框 polygon 座標和 confidence。 若也偵測到指向相關文字的範圍,styles 集合便會包含任何手寫樣式的文字行。 此功能適用於支援的手寫語言。
針對 Microsoft Word、Excel、PowerPoint 和 HTML,文件智慧服務讀取模型 v3.1 和更新版本會依原狀擷取所有內嵌文字。 文字會擷取為字組和段落。 不支援內嵌的影像。
"words": [
{
"content": "While",
"polygon": [],
"confidence": 0.997,
"span": {}
},
],
"lines": [
{
"content": "While healthcare is still in the early stages of its Al journey, we",
"polygon": [],
"spans": [],
}
]
# Analyze lines.
for line_idx, line in enumerate(page.lines):
words = line.get_words()
print(
f"...Line # {line_idx} has {len(words)} words and text '{line.content}' within bounding polygon '{format_polygon(line.polygon)}'"
)
# Analyze words.
for word in words:
print(
f"......Word '{word.content}' has a confidence of {word.confidence}"
)
# Analyze lines.
if page.lines:
for line_idx, line in enumerate(page.lines):
words = get_words(page, line)
print(
f"...Line # {line_idx} has {len(words)} words and text '{line.content}' within bounding polygon '{line.polygon}'"
)
# Analyze words.
for word in words:
print(f"......Word '{word.content}' has a confidence of {word.confidence}")
手寫樣式的文字行
回應會包含辨別每個文字行是否為手寫樣式的分類,以及信賴度分數。 如需詳細資訊,請參閱手寫語言支援。 下列範例顯示 JSON 程式碼片段範例。
"styles": [
{
"confidence": 0.95,
"spans": [
{
"offset": 509,
"length": 24
}
"isHandwritten": true
]
}
如果您已啟用字型/樣式附加元件功能,也會取得字型/樣式結果作為 styles 物件的一部分。
下一步
完成 Document Intelligence 快速入門:
探索 REST API:
在 GitHub 上尋找更多範例:
在 GitHub 上尋找更多範例:
意見反應
即將登場:在 2024 年,我們將逐步淘汰 GitHub 問題作為內容的意見反應機制,並將它取代為新的意見反應系統。 如需詳細資訊,請參閱:https://aka.ms/ContentUserFeedback。
提交並檢視相關的意見反應