教學課程:在 Azure Notebook 中使用個人化工具
重要
從 2023 年 9 月 20 日起,您將無法建立新的個人化工具資源。 個人化工具服務將於 2026 年 10 月 1 日淘汰。
此教學課程會在 Azure Notebook 中執行個人化工具迴圈,以示範個人化工具迴圈的端對端生命週期。
迴圈會建議客戶應訂購的咖啡類型。 使用者及其喜好設定會儲存在使用者資料集中。 咖啡的相關資訊會儲存在咖啡資料集內。
使用者和咖啡
這個模擬使用者與網站互動的筆記本會選取隨機使用者、一天當中的某個時間,以及資料集內的天氣類型。 使用者資訊的摘要如下:
| 客戶 - 內容功能 | 當日時間 | 天氣類型 |
|---|---|---|
| Alice Bob Cathy Dave |
上午 下午 晚上 |
晴朗 下雨 下雪 |
為了協助個人化工具隨著時間學習,「系統」也會了解每個人所選咖啡的相關詳細資料。
| 咖啡 - 動作功能 | 溫度類型 | 來源地 | 烘培類型 | 有機 |
|---|---|---|---|---|
| 卡布奇諾 | 經常性 | 肯亞 | 深色 | 有機 |
| 冷萃 | 沒有興趣 | 巴西 | 淺色 | 有機 |
| 冰摩卡 | 沒有興趣 | 衣索比亞 | 淺色 | 非有機 |
| Latte (拿鐵) | 經常性 | 巴西 | 深色 | 非有機 |
個人化工具迴圈的目的,是盡可能找出使用者與咖啡的最大相符程度。
此教學課程的程式碼可在個人化工具範例 GitHub 存放庫中取得。
模擬的運作方式
運作中系統剛開始時,個人化工具所提供的建議成功率只有 20% 到 30%。 成功與否的表示方法是個人化工具獎勵 API 所傳回來分數為 1 的獎勵。 在呼叫某些排名和獎勵後,系統就會改善。
在初始要求之後,請執行離線評估。 這可讓個人化工具檢閱資料,並建議較佳的學習原則。 套用新的學習原則,並使用前一個要求計數的 20% 重新執行筆記本。 迴圈使用新的學習原則時會執行得更好。
排名和獎勵呼叫
針對個人化工具服務的數千次呼叫,Azure Notebook 會將排名要求傳送至 REST API:
- 排名/要求事件的唯一識別碼
- 內容特性 - 使用者、天氣和當日時間的隨機選擇 - 模擬網站或行動裝置上的使用者
- 具有特性的動作 - 所有咖啡資料 - 個人化工具會據此提出建議
系統會接收要求,然後針對相同的當日時間和天氣,將該預測與使用者的已知選擇進行比較。 如果已知的選擇與預測的選擇相同,則會將獎勵 1 重新傳送回個人化工具。 否則,傳回的獎勵為 0。
注意
這是模擬,因此獎勵的演算法很簡單。 在真實世界的情節中,演算法應該使用商務邏輯,可能會在客戶體驗的各種層面上使用「加權」,以決定獎勵分數。
必要條件
- Azure Notebook 帳戶。
- Azure AI 個人化工具資源。
- 如果您已經使用個人化工具資源,請務必在 Azure 入口網站中針對資源清除資料。
- 將此範例的所有檔案上傳到 Azure Notebook 專案。
檔案說明:
- Personalizer.ipynb 是此教學課程的 Jupyter 筆記本。
- 使用者資料集會儲存在 JSON 物件中。
- 咖啡資料集會儲存在 JSON 物件中。
- 範例要求 JSON 是排名 API 的 POST 要求的預期格式。
設定個人化工具資源
在 Azure 入口網站中,將您的個人化工具資源的 [更新模型頻率] 設為 15 秒,且 [奬勵等待時間] 為 10 分鐘。 您可在設定頁面上找到這些值。
| 設定 | 值 |
|---|---|
| 更新模型頻率 | 15 秒 |
| 奬勵等待時間 | 10 分鐘 |
這些值具有非常短的持續時間,以便在此教學課程中顯示變更。 在未驗證這些值是否使用個人化工具迴圈達到您的目標的情況下,不應在生產環境情節中使用它們。
設定 Azure Notebook
- 將核心變更為
Python 3.6。 - 開啟
Personalizer.ipynb檔案。
執行 Notebook 資料格
執行每個可執行檔資料格,並等候它傳回。 當資料格旁邊的括弧顯示一個數字,而不是 * 時,您就知道它已完成。 下列各節說明每個資料格以程式設計方式執行的動作,以及預期輸出的內容。
包含 Python 模組
包含所需的 Python 模組。 資料格沒有輸出。
import json
import matplotlib.pyplot as plt
import random
import requests
import time
import uuid
設定個人化工具資源金鑰和名稱
在 Azure 入口網站中,於個人化工具資源的 [快速入門] 頁面上尋找您的金鑰和端點。 將 <your-resource-name> 的值變更為您的個人化工具資源名稱。 將 <your-resource-key> 的值變更為您的個人化工具金鑰。
# Replace 'personalization_base_url' and 'resource_key' with your valid endpoint values.
personalization_base_url = "https://<your-resource-name>.cognitiveservices.azure.com/"
resource_key = "<your-resource-key>"
列印目前的日期和時間
使用此函式可記下反覆函式 (反覆運算) 的開始和結束時間。
這些資料格沒有輸出。 函式會在呼叫時輸出目前的日期和時間。
# Print out current datetime
def currentDateTime():
currentDT = datetime.datetime.now()
print (str(currentDT))
取得最後一個模型更新時間
當呼叫 get_last_updated 函式時,函式會列印出更新模型的上次修改日期和時間。
這些資料格沒有輸出。 函式會在呼叫時輸出最後一個模型定型日期。
函式會使用 GET REST API 來取得模型屬性 \(英文\)。
# ititialize variable for model's last modified date
modelLastModified = ""
def get_last_updated(currentModifiedDate):
print('-----checking model')
# get model properties
response = requests.get(personalization_model_properties_url, headers = headers, params = None)
print(response)
print(response.json())
# get lastModifiedTime
lastModifiedTime = json.dumps(response.json()["lastModifiedTime"])
if (currentModifiedDate != lastModifiedTime):
currentModifiedDate = lastModifiedTime
print(f'-----model updated: {lastModifiedTime}')
取得原則和服務設定
使用這兩個 REST 呼叫來驗證服務的狀態。
這些資料格沒有輸出。 函式會在呼叫時輸出服務值。
def get_service_settings():
print('-----checking service settings')
# get learning policy
response = requests.get(personalization_model_policy_url, headers = headers, params = None)
print(response)
print(response.json())
# get service settings
response = requests.get(personalization_service_configuration_url, headers = headers, params = None)
print(response)
print(response.json())
建構 URL 並讀取 JSON 資料檔案
此資料格會
- 建置 REST 呼叫中所使用的 URL
- 使用您的個人化工具資源金鑰設定安全性標頭
- 設定排名事件識別碼的隨機種子
- 讀取 JSON 資料檔案
- 呼叫
get_last_updated方法 - 學習原則已從範例輸出中移除 - 呼叫
get_service_settings方法
資料格具有 get_last_updated 和 get_service_settings 函式之呼叫的輸出。
# build URLs
personalization_rank_url = personalization_base_url + "personalizer/v1.0/rank"
personalization_reward_url = personalization_base_url + "personalizer/v1.0/events/" #add "{eventId}/reward"
personalization_model_properties_url = personalization_base_url + "personalizer/v1.0/model/properties"
personalization_model_policy_url = personalization_base_url + "personalizer/v1.0/configurations/policy"
personalization_service_configuration_url = personalization_base_url + "personalizer/v1.0/configurations/service"
headers = {'Ocp-Apim-Subscription-Key' : resource_key, 'Content-Type': 'application/json'}
# context
users = "users.json"
# action features
coffee = "coffee.json"
# empty JSON for Rank request
requestpath = "example-rankrequest.json"
# initialize random
random.seed(time.time())
userpref = None
rankactionsjsonobj = None
actionfeaturesobj = None
with open(users) as handle:
userpref = json.loads(handle.read())
with open(coffee) as handle:
actionfeaturesobj = json.loads(handle.read())
with open(requestpath) as handle:
rankactionsjsonobj = json.loads(handle.read())
get_last_updated(modelLastModified)
get_service_settings()
print(f'User count {len(userpref)}')
print(f'Coffee count {len(actionfeaturesobj)}')
確認輸出的 rewardWaitTime 設定為 10 分鐘,且 modelExportFrequency 設定為 15 秒。
-----checking model
<Response [200]>
{'creationTime': '0001-01-01T00:00:00+00:00', 'lastModifiedTime': '0001-01-01T00:00:00+00:00'}
-----model updated: "0001-01-01T00:00:00+00:00"
-----checking service settings
<Response [200]>
{...learning policy...}
<Response [200]>
{'rewardWaitTime': '00:10:00', 'defaultReward': 0.0, 'rewardAggregation': 'earliest', 'explorationPercentage': 0.2, 'modelExportFrequency': '00:00:15', 'logRetentionDays': -1}
User count 4
Coffee count 4
針對第一個 REST 呼叫進行疑難排解
先前的資料格是呼叫個人化工具的第一個資料格。 請確定輸出中的 REST 狀態碼為 <Response [200]>。 如果您收到錯誤 (例如 404),但您確定您的資源金鑰和名稱正確無誤,請重新載入筆記本。
請確定咖啡和使用者的計數都是 4。 如果您收到錯誤,請確認您已上傳全部 3 個 JSON 檔案。
在 Azure 入口網站中設定計量圖表
稍後在此教學課程中,會在具有 [更新] 文字方塊的瀏覽器中顯示 10,000 次要求的長時間執行中處理序。 當長時間執行中處理序結束時,可能更容易在圖表中或以總和形式查看。 若要檢視此資訊,請使用資源所提供的計量。 現在您已完成對服務的要求,您可以建立圖表,然後在長時間執行中處理序進行時,定期重新整理圖表。
在 Azure 入口網站中,選取個人化工具資源。
在資源導覽中,選取 [監視] 底下的 [計量]。
在圖表中,選取 [新增計量]。
資源和計量命名空間已設定。 您只需要選取 [成功呼叫] 的計量,以及 [總和] 的匯總。
將時間篩選器變更為過去 4 小時。
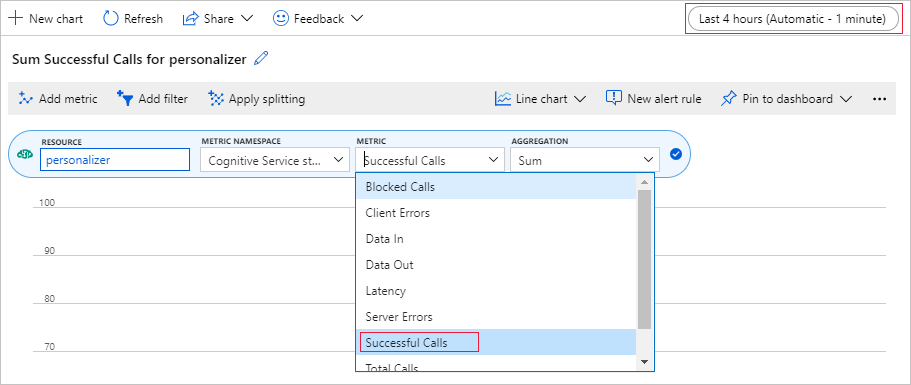
您應該會在圖表中看到三個成功的呼叫。
產生唯一事件識別碼
此函式會為每個排名呼叫產生唯一的識別碼。 識別碼是用來識別排名和獎勵呼叫資訊。 這個值可能來自商務處理序,例如 Web 視圖識別碼或交易識別碼。
資料格沒有輸出。 函式會在呼叫時輸出唯一識別碼。
def add_event_id(rankjsonobj):
eventid = uuid.uuid4().hex
rankjsonobj["eventId"] = eventid
return eventid
取得隨機使用者、天氣和當日時間
此函式會選取唯一的使用者、天氣和當日時間,然後將這些項目新增至要傳送至排名要求的 JSON 物件。
資料格沒有輸出。 呼叫函式時,它會傳回隨機使用者的名稱、隨機天氣和隨機當日時間。
4 個使用者及其喜好設定的清單 - ㄠ為了簡潔起見,只會顯示一些喜好設定:
{
"Alice": {
"Sunny": {
"Morning": "Cold brew",
"Afternoon": "Iced mocha",
"Evening": "Cold brew"
}...
},
"Bob": {
"Sunny": {
"Morning": "Cappucino",
"Afternoon": "Iced mocha",
"Evening": "Cold brew"
}...
},
"Cathy": {
"Sunny": {
"Morning": "Latte",
"Afternoon": "Cold brew",
"Evening": "Cappucino"
}...
},
"Dave": {
"Sunny": {
"Morning": "Iced mocha",
"Afternoon": "Iced mocha",
"Evening": "Iced mocha"
}...
}
}
def add_random_user_and_contextfeatures(namesoption, weatheropt, timeofdayopt, rankjsonobj):
name = namesoption[random.randint(0,3)]
weather = weatheropt[random.randint(0,2)]
timeofday = timeofdayopt[random.randint(0,2)]
rankjsonobj['contextFeatures'] = [{'timeofday': timeofday, 'weather': weather, 'name': name}]
return [name, weather, timeofday]
新增所有咖啡資料
此函式會將整個咖啡清單新增至要傳送至排名要求的 JSON 物件。
資料格沒有輸出。 函式會在呼叫時變更 rankjsonobj。
單一咖啡功能的範例如下:
{
"id": "Cappucino",
"features": [
{
"type": "hot",
"origin": "kenya",
"organic": "yes",
"roast": "dark"
}
}
def add_action_features(rankjsonobj):
rankjsonobj["actions"] = actionfeaturesobj
將預測與已知的使用者喜好設定進行比較
針對每個反覆項目,在呼叫排名 API 之後都會呼叫此函式。
此函式會根據天氣和當日時間,將使用者的咖啡喜好設定,與個人化工具針對那些過濾器提供給使用者的建議進行比較。 如果建議符合,則會傳回 1 的分數,否則分數為 0。 資料格沒有輸出。 函式會在呼叫時輸出分數。
def get_reward_from_simulated_data(name, weather, timeofday, prediction):
if(userpref[name][weather][timeofday] == str(prediction)):
return 1
return 0
透過排名和獎勵呼叫進行迴圈
下一個資料格是 Notebook 的主要工作,它會取得隨機使用者、取得咖啡清單,同時將兩者傳送到排名 API。 將預測與使用者的已知喜好設定進行比較,然後將獎勵傳回給個人化工具服務。
迴圈會執行 num_requests 次。 個人化工具需要數千次排名和獎勵呼叫來建立模型。
以下是傳送給排名 API 的 JSON 範例。 為了簡潔起見,咖啡清單並不完整。 您可以在 coffee.json 中查看適用於咖啡的完整 JSON。
傳送給排名 API 的 JSON:
{
'contextFeatures':[
{
'timeofday':'Evening',
'weather':'Snowy',
'name':'Alice'
}
],
'actions':[
{
'id':'Cappucino',
'features':[
{
'type':'hot',
'origin':'kenya',
'organic':'yes',
'roast':'dark'
}
]
}
...rest of coffee list
],
'excludedActions':[
],
'eventId':'b5c4ef3e8c434f358382b04be8963f62',
'deferActivation':False
}
來自排名 API 的 JSON 回應:
{
'ranking': [
{'id': 'Latte', 'probability': 0.85 },
{'id': 'Iced mocha', 'probability': 0.05 },
{'id': 'Cappucino', 'probability': 0.05 },
{'id': 'Cold brew', 'probability': 0.05 }
],
'eventId': '5001bcfe3bb542a1a238e6d18d57f2d2',
'rewardActionId': 'Latte'
}
最後,每個迴圈都會顯示隨機選取的使用者、天氣、當日時間,以及決定的獎勵。 獎勵 1 表示個人化工具資源為指定的使用者、天氣和當日時間選取了正確的咖啡類型。
1 Alice Rainy Morning Latte 1
該函式會使用:
def iterations(n, modelCheck, jsonFormat):
i = 1
# default reward value - assumes failed prediction
reward = 0
# Print out dateTime
currentDateTime()
# collect results to aggregate in graph
total = 0
rewards = []
count = []
# default list of user, weather, time of day
namesopt = ['Alice', 'Bob', 'Cathy', 'Dave']
weatheropt = ['Sunny', 'Rainy', 'Snowy']
timeofdayopt = ['Morning', 'Afternoon', 'Evening']
while(i <= n):
# create unique id to associate with an event
eventid = add_event_id(jsonFormat)
# generate a random sample
[name, weather, timeofday] = add_random_user_and_contextfeatures(namesopt, weatheropt, timeofdayopt, jsonFormat)
# add action features to rank
add_action_features(jsonFormat)
# show JSON to send to Rank
print('To: ', jsonFormat)
# choose an action - get prediction from Personalizer
response = requests.post(personalization_rank_url, headers = headers, params = None, json = jsonFormat)
# show Rank prediction
print ('From: ',response.json())
# compare personalization service recommendation with the simulated data to generate a reward value
prediction = json.dumps(response.json()["rewardActionId"]).replace('"','')
reward = get_reward_from_simulated_data(name, weather, timeofday, prediction)
# show result for iteration
print(f' {i} {currentDateTime()} {name} {weather} {timeofday} {prediction} {reward}')
# send the reward to the service
response = requests.post(personalization_reward_url + eventid + "/reward", headers = headers, params= None, json = { "value" : reward })
# for every N rank requests, compute total correct total
total = total + reward
# every N iteration, get last updated model date and time
if(i % modelCheck == 0):
print("**** 10% of loop found")
get_last_updated(modelLastModified)
# aggregate so chart is easier to read
if(i % 10 == 0):
rewards.append( total)
count.append(i)
total = 0
i = i + 1
# Print out dateTime
currentDateTime()
return [count, rewards]
執行 10,000 次反覆運算
執行個人化工具迴圈進行 10,000 次反覆運算。 這是長時間執行的事件。 請勿關閉執行筆記本的瀏覽器。 定期重新整理 Azure 入口網站中的計量圖表,以查看服務的總呼叫。 當您有大約 20,000 次呼叫 (每個迴圈反覆運算的排名和獎勵呼叫) 時,即完成反覆運算。
# max iterations
num_requests = 200
# check last mod date N% of time - currently 10%
lastModCheck = int(num_requests * .10)
jsonTemplate = rankactionsjsonobj
# main iterations
[count, rewards] = iterations(num_requests, lastModCheck, jsonTemplate)
建立結果圖表以查看改善
從 count 和 rewards 建立圖表。
def createChart(x, y):
plt.plot(x, y)
plt.xlabel("Batch of rank events")
plt.ylabel("Correct recommendations per batch")
plt.show()
執行圖表進行 10,000 次排名要求
執行 createChart 函式。
createChart(count,rewards)
讀取圖表
此圖表會顯示目前預設學習原則的模型是否成功。
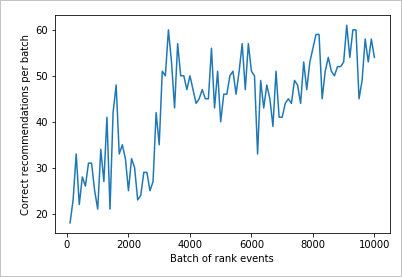
測試結束時的理想目標是,迴圈會平均成功率 (接近 100%) 減去探索。 探索的預設值為 20%。
100-20=80
在 Azure 入口網站中,於個人化工具資源的 [設定] 頁面上可以找到此探索值。
若要找出更好的學習原則,請根據您的排名 API 資料,在入口網站中針對您的個人化工具迴圈執行離線評估。
執行離線評估
在 Azure 入口網站中,開啟個人化工具資源的 [評估] 頁面。
選取 [建立評估]。
輸入評估名稱所需的資料,以及迴圈評估的日期範圍。 日期範圍應僅包含您要專注進行評估的天數。
![在 Azure 入口網站中,開啟個人化工具資源的 [評估] 頁面。選取 [建立評估]。輸入評估名稱和日期範圍。](media/tutorial-azure-notebook/create-offline-evaluation.png)
執行此離線評估的目的,是要判斷此迴圈中使用的功能和動作是否有更好的學習原則。 若要找出更好的學習原則,請確定已開啟 [最佳化探索]。
選取 [確定] 來開始評估。
此 [評估] 頁面會列出新的評估和其目前的狀態。 視您擁有的資料量而定,此評估可能需要一些時間。 您可以在幾分鐘後回到此頁面,以查看結果。
當評估完成時,請選取評估,然後選取 [比較不同的學習原則]。 這顯示了可用的學習原則,以及它們如何處理資料。
選取表格中最高級的學習原則,然後選取 [套用]。 這會將最佳學習原則套用至您的模型並重新定型。
將更新模型頻率變更為 5 分鐘
- 在 Azure 入口網站中,仍在個人化工具資源上,選取 [設定] 頁面。
- 將 [模型更新頻率] 和 [奬勵等待時間] 變更為 5 分鐘,然後選取 [儲存]。
#Verify new learning policy and times
get_service_settings()
確認輸出的 rewardWaitTime 和 modelExportFrequency 都設定為 5 分鐘。
-----checking model
<Response [200]>
{'creationTime': '0001-01-01T00:00:00+00:00', 'lastModifiedTime': '0001-01-01T00:00:00+00:00'}
-----model updated: "0001-01-01T00:00:00+00:00"
-----checking service settings
<Response [200]>
{...learning policy...}
<Response [200]>
{'rewardWaitTime': '00:05:00', 'defaultReward': 0.0, 'rewardAggregation': 'earliest', 'explorationPercentage': 0.2, 'modelExportFrequency': '00:05:00', 'logRetentionDays': -1}
User count 4
Coffee count 4
驗證新的學習原則
返回 Azure Notebooks 檔案,並繼續執行相同的迴圈,但僅進行 2,000 次反覆運算。 定期重新整理 Azure 入口網站中的計量圖表,以查看服務的總呼叫。 當您有大約 4,000 次呼叫 (每個迴圈反覆運算的排名和獎勵呼叫) 時,即完成反覆運算。
# max iterations
num_requests = 2000
# check last mod date N% of time - currently 10%
lastModCheck2 = int(num_requests * .10)
jsonTemplate2 = rankactionsjsonobj
# main iterations
[count2, rewards2] = iterations(num_requests, lastModCheck2, jsonTemplate)
執行圖表進行 2,000 次排名要求
執行 createChart 函式。
createChart(count2,rewards2)
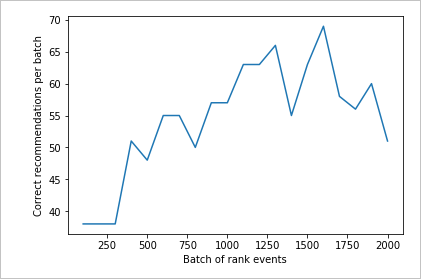
檢閱第二個圖表
第二張圖表應顯示與使用者喜好一致之排名預測的明顯增加。
清除資源
如果您不想要繼續進行教學課程系列,請清除下列資源:
- 刪除您的 Azure Notebook 專案。
- 刪除您的個人化工具資源。
下一步
此範例中使用的 Jupyter 筆記本和資料檔案可在適用於個人化工具的 GitHub 存放庫中取得。