快速入門:使用交談語言理解辨識意圖
參考文件 | 套件 (NuGet) | GitHub 上的其他範例
在本快速入門中,您將使用語音和語言服務來辨識從麥克風擷取之音訊資料的意圖。 具體而言,您將使用語音服務來辨識語音,並使用交談語言理解 (CLU) 模型來辨識意圖。
重要
交談語言理解 (CLU) 適用於語音 SDK 版本 1.25 或更新的 C# 和 C++。
必要條件
- Azure 訂用帳戶。 您可以免費建立一個訂用帳戶。
- 在 Azure 入口網站上建立語言資源。
- 取得語言資源金鑰和端點。 部署語言資源之後,選取 [前往資源] 以檢視和管理金鑰。
- 在 Azure 入口網站上建立語音資源。
- 取得語音資源金鑰和區域。 部署語音資源之後,選取 [移至資源] 以檢視和管理索引鍵。
設定環境
語音 SDK 可以 NuGet 套件的形式取得,並且實作 .NET Standard 2.0。 您會在本指南的後續部分中安裝語音 SDK,但請先參閱 SDK 安裝指南,了解其他需求。
設定環境變數
此範例需要名為 LANGUAGE_KEY、LANGUAGE_ENDPOINT、SPEECH_KEY 和 SPEECH_REGION 的環境變數。
您的應用程式必須經過驗證,才能存取 Azure AI 服務資源。 本文說明如何使用環境變數來儲存您的認證。 然後,您可以從程式碼存取環境變數,以驗證您的應用程式。 針對實際執行環境,使用更安全的方法來儲存和存取您的認證。
重要
我們建議使用適用於 Azure 資源的受控識別搭配 Microsoft Entra ID 驗證,以避免使用在雲端執行的應用程式儲存認證。
如果您使用 API 金鑰,請將其安全地儲存在別處,例如 Azure Key Vault。 請勿在程式碼中直接包含 API 金鑰,且切勿公開將其張貼。
如需 AI 服務安全性的詳細資訊,請參閱驗證對 Azure AI 服務的要求。
若要設定環境變數,請開啟主控台視窗,然後遵循作業系統和開發環境的指示進行。
- 若要設定
LANGUAGE_KEY環境變數,請以您其中一個資源索引碼取代your-language-key。 - 若要設定
LANGUAGE_ENDPOINT環境變數,請以您的其中一個資源區域取代your-language-endpoint。 - 若要設定
SPEECH_KEY環境變數,請以您其中一個資源索引碼取代your-speech-key。 - 若要設定
SPEECH_REGION環境變數,請以您的其中一個資源區域取代your-speech-region。
setx LANGUAGE_KEY your-language-key
setx LANGUAGE_ENDPOINT your-language-endpoint
setx SPEECH_KEY your-speech-key
setx SPEECH_REGION your-speech-region
注意
如果您只需在目前執行中的主控台上存取環境變數,您可以使用 set 來設定環境變數,而不是 setx。
新增環境變數之後,您可能需要重新啟動任何需要讀取環境變數的執行中程式,包括主控台視窗。 例如,如果您使用 Visual Studio 做為編輯器,請在執行範例前重新啟動 Visual Studio。
建立交談語言理解專案
一旦您建立了語言資源,請在 Language Studio 中建立交談語言理解專案。 專案是一個工作區域,用於根據您的資料建置自訂 ML 模型。 您的專案只能由您和具有要使用的語言資源存取權的其他人員存取。
請前往 Language Studio,並以您的 Azure 帳戶登入。
建立交談語言理解專案
針對本快速入門,您可以下載此範例家庭自動化專案並將其匯入。 此專案能夠預測使用者輸入的意圖命令,例如開燈或關燈。
在 Language Studio 的 [理解問題和交談語言] 區段下,選取 [交談語言理解]。
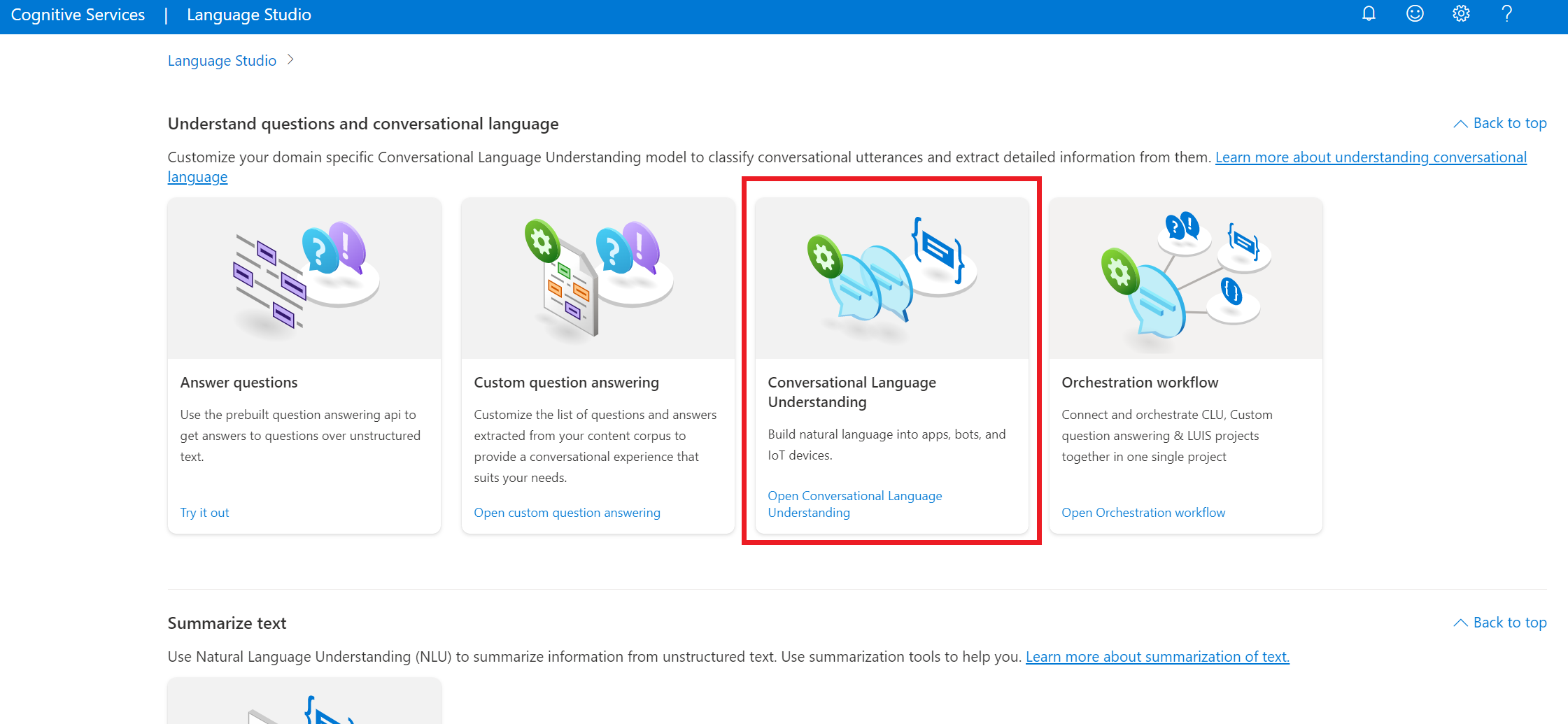
這會帶您前往 [交談語言理解專案] 頁面。 在 [建立新專案] 按鈕旁,選取 [匯入]。
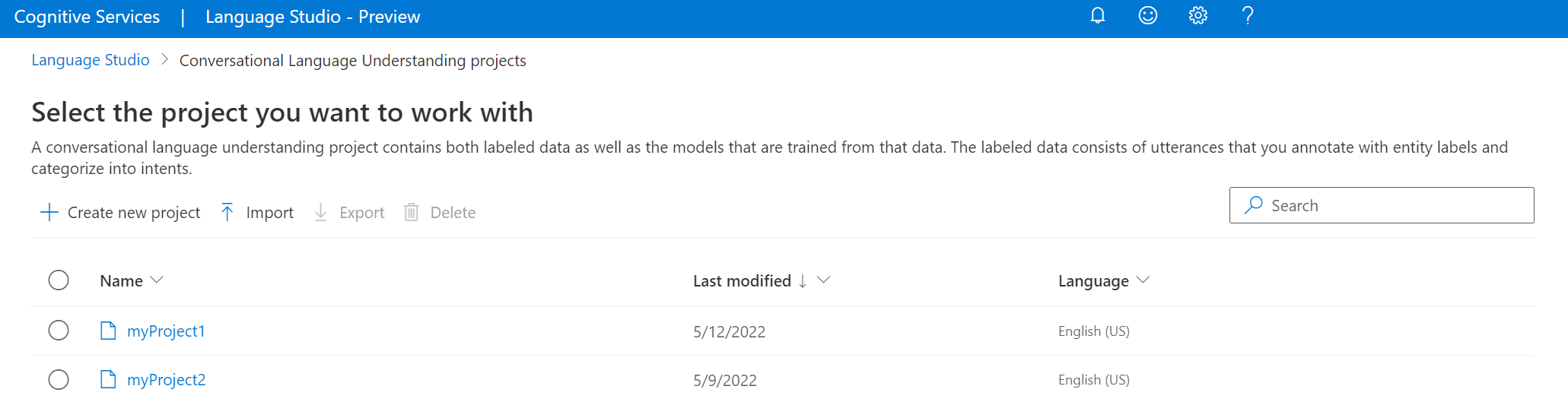
在出現的視窗中,上傳您想要匯入的 JSON 檔案。 確定您的檔案遵循支援的 JSON 格式。


一旦上傳完成,您就會登陸 [結構描述定義] 頁面。 針對本快速入門,已建置結構描述,且語句已加上意圖和實體的標籤。
定型您的模型
一般而言,在建立專案之後,您應該建置結構描述和標記語句。 針對本快速入門,我們已匯入備妥專案,其中具有已建置的結構描述和已標記的語句。
若要定型模型,則須啟動定型作業。 成功定型作業的輸出即是定型的模型。
若要從 Language Studio 內開始定型模型:
從左側功能表中選取 [定型模型]。
從頂端功能表中選取 [開始定型作業]。
選取 [定型新模型],然後在文字輸入框中輸入模型名稱。 否則,若要以在新資料上定型的模型取代現有的模型,請選取 [覆寫現有的模型],然後選取現有的模型。 覆寫定型的模型是無法復原的,但在您部署新模型之前,不會影響已部署的模型。
選取定型模式。 您可以選擇 [標準定型] 來加快定型速度,但僅適用於英文。 或者,您可以選擇支援其他語言和多語系專案的 [進階定型],但需要較長的定型時間。 深入瞭解模型定型。
選取資料分割方法。 您可以選擇 [從定型資料自動分割測試集],使用此方法時,系統會根據指定的百分比,將您的表達分割為定型集與測試集。 或者,您可以選擇 [使用手動分割定型和測試資料],但只有在表達已新增至測試集,且您標記表達時,才會啟用此選項。
選取 [定型] 按鈕。
![顯示 Language Studio 中 [訓練] 頁面的螢幕擷取畫面。](../language-service/conversational-language-understanding/media/train-model.png)
選取清單中的定型作業識別碼。 隨即顯示窗格,您可以在其中檢查此作業的定型進度、作業狀態及其他詳細資料。
注意
- 只有成功完成的定型作業才會產生模型。
- 根據表達的計數,定型可能需要幾分鐘到幾小時的時間。
- 您一次只能執行一個定型作業。 除非執行中的作業完成,否則無法在同一個專案內啟動其他定型作業。
- 用來定型模型的機器學習會定期更新。 若要在先前的設定版本上定型,請從 [開始定型作業] 頁面選取 [選取這裡以變更],然後選擇舊版。
![顯示 Language Studio 中 [訓練] 頁面的螢幕擷取畫面。](../language-service/conversational-language-understanding/media/train-model.png#lightbox)
部署模型
定型模型後,您通常可檢閱其評估詳細資料。 在本快速入門中,您只需部署模型,並讓其可供您在 Language Studio 中試用,或者您可以呼叫預測 API。
若要從 Language Studio 內部署您的模型:
從左側功能表中,選取 [部署模型]。
選取 [新增部署] 以啟動 [新增部署] 精靈。
選取 [建立新的部署] 以建立新的部署,並從下方的下拉式清單中指派定型的模型。 否則,您可以選取 [覆寫現有的部署名稱],以有效地取代現有部署所使用的模型。
注意
覆寫現有的部署不需要變更預測 API 呼叫,但您取得的結果將會以新指派的模型為基礎。
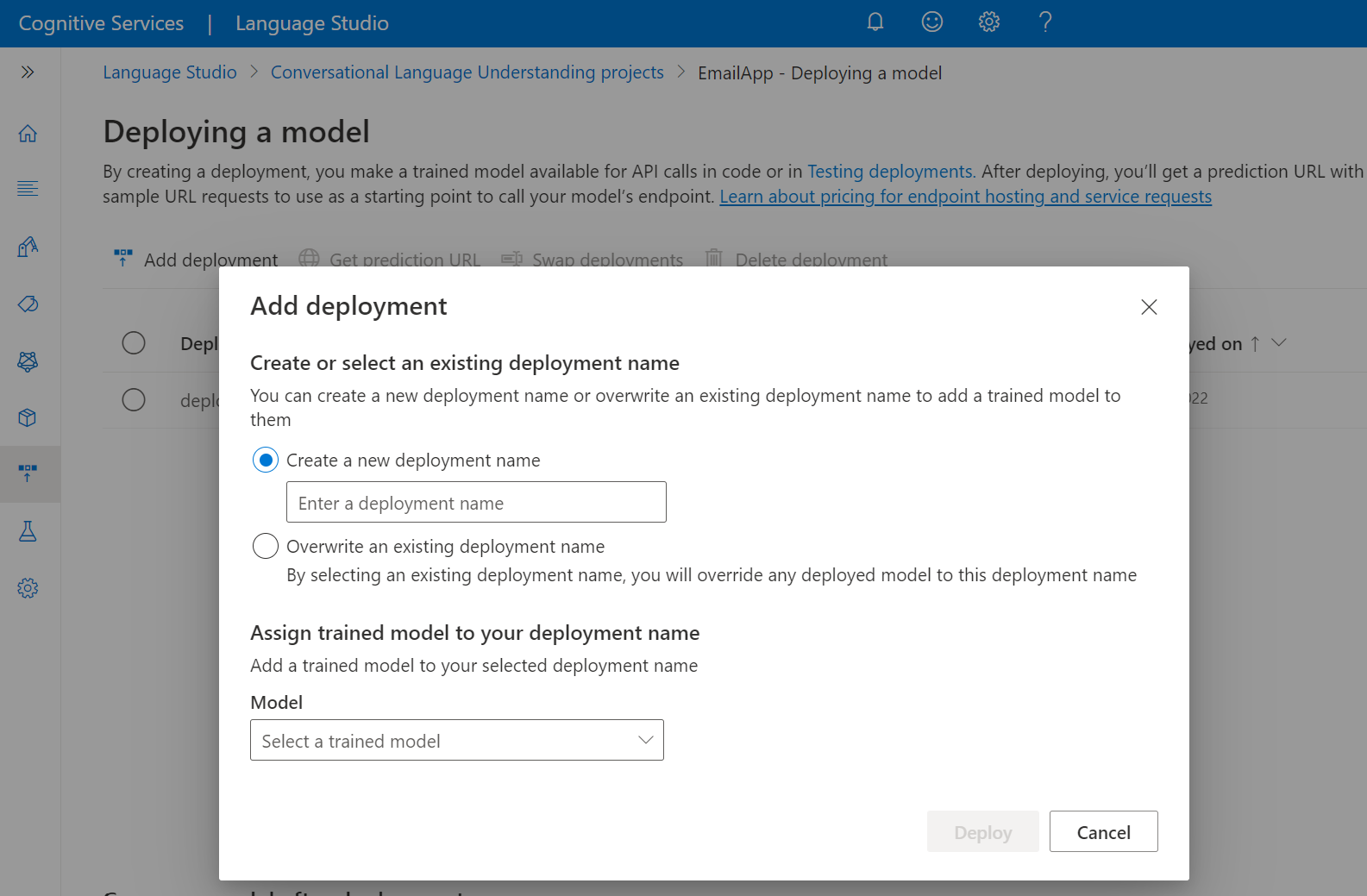
從 [模型] 下拉式清單中選取定型的模型。
選取 [部署] 以啟動部署作業。
部署成功之後,在其旁邊會出現到期日。 部署到期表示部署的模型無法再用於預測,通常發生於訓練組態到期的十二個月後。


您將在下一節中使用專案名稱和部署名稱。
從麥克風辨識意圖
遵循下列步驟來建立新的主控台應用程式並安裝語音 SDK。
在您想要新專案的位置開啟命令提示字元,並使用 .NET CLI 建立主控台應用程式。 建議您在專案目錄中建立
Program.cs檔案。dotnet new console使用 .NET CLI 在新專案中安裝語音 SDK。
dotnet add package Microsoft.CognitiveServices.Speech以下列程式碼取代
Program.cs的內容。using Microsoft.CognitiveServices.Speech; using Microsoft.CognitiveServices.Speech.Audio; using Microsoft.CognitiveServices.Speech.Intent; class Program { // This example requires environment variables named: // "LANGUAGE_KEY", "LANGUAGE_ENDPOINT", "SPEECH_KEY", and "SPEECH_REGION" static string languageKey = Environment.GetEnvironmentVariable("LANGUAGE_KEY"); static string languageEndpoint = Environment.GetEnvironmentVariable("LANGUAGE_ENDPOINT"); static string speechKey = Environment.GetEnvironmentVariable("SPEECH_KEY"); static string speechRegion = Environment.GetEnvironmentVariable("SPEECH_REGION"); // Your CLU project name and deployment name. static string cluProjectName = "YourProjectNameGoesHere"; static string cluDeploymentName = "YourDeploymentNameGoesHere"; async static Task Main(string[] args) { var speechConfig = SpeechConfig.FromSubscription(speechKey, speechRegion); speechConfig.SpeechRecognitionLanguage = "en-US"; using var audioConfig = AudioConfig.FromDefaultMicrophoneInput(); // Creates an intent recognizer in the specified language using microphone as audio input. using (var intentRecognizer = new IntentRecognizer(speechConfig, audioConfig)) { var cluModel = new ConversationalLanguageUnderstandingModel( languageKey, languageEndpoint, cluProjectName, cluDeploymentName); var collection = new LanguageUnderstandingModelCollection(); collection.Add(cluModel); intentRecognizer.ApplyLanguageModels(collection); Console.WriteLine("Speak into your microphone."); var recognitionResult = await intentRecognizer.RecognizeOnceAsync().ConfigureAwait(false); // Checks result. if (recognitionResult.Reason == ResultReason.RecognizedIntent) { Console.WriteLine($"RECOGNIZED: Text={recognitionResult.Text}"); Console.WriteLine($" Intent Id: {recognitionResult.IntentId}."); Console.WriteLine($" Language Understanding JSON: {recognitionResult.Properties.GetProperty(PropertyId.LanguageUnderstandingServiceResponse_JsonResult)}."); } else if (recognitionResult.Reason == ResultReason.RecognizedSpeech) { Console.WriteLine($"RECOGNIZED: Text={recognitionResult.Text}"); Console.WriteLine($" Intent not recognized."); } else if (recognitionResult.Reason == ResultReason.NoMatch) { Console.WriteLine($"NOMATCH: Speech could not be recognized."); } else if (recognitionResult.Reason == ResultReason.Canceled) { var cancellation = CancellationDetails.FromResult(recognitionResult); Console.WriteLine($"CANCELED: Reason={cancellation.Reason}"); if (cancellation.Reason == CancellationReason.Error) { Console.WriteLine($"CANCELED: ErrorCode={cancellation.ErrorCode}"); Console.WriteLine($"CANCELED: ErrorDetails={cancellation.ErrorDetails}"); Console.WriteLine($"CANCELED: Did you update the subscription info?"); } } } } }在
Program.cs中,將cluProjectName和cluDeploymentName變數設定為專案和部署的名稱。 如需如何建立 CLU 專案和部署的資訊,請參閱建立交談語言理解專案。若要變更語音辨識語言,請以另一種支援的語言取代
en-US。 例如,es-ES代表西班牙文 (西班牙)。 如果您未指定語言,則預設語言為en-US。 如需詳細了解如何識別所可能說出的多種語言之一,請參閱語言識別。
執行新的主控台應用程式,以從麥克風啟動語音辨識:
dotnet run
重要
確保您已如上所述設定 LANGUAGE_KEY、LANGUAGE_ENDPOINT、SPEECH_KEY 和 SPEECH_REGION 環境變數。 如果您未設定這些變數,則範例將會失敗,並顯示錯誤訊息。
出現提示時,請用麥克風說話。 您說話的內容應該會以文字的形式輸出:
Speak into your microphone.
RECOGNIZED: Text=Turn on the lights.
Intent Id: HomeAutomation.TurnOn.
Language Understanding JSON: {"kind":"ConversationResult","result":{"query":"turn on the lights","prediction":{"topIntent":"HomeAutomation.TurnOn","projectKind":"Conversation","intents":[{"category":"HomeAutomation.TurnOn","confidenceScore":0.97712576},{"category":"HomeAutomation.TurnOff","confidenceScore":0.8431633},{"category":"None","confidenceScore":0.782861}],"entities":[{"category":"HomeAutomation.DeviceType","text":"lights","offset":12,"length":6,"confidenceScore":1,"extraInformation":[{"extraInformationKind":"ListKey","key":"light"}]}]}}}.
注意
在語音 SDK 版本 1.26 中透過 LanguageUnderstandingServiceResponse_JsonResult 屬性為 CLU 新增了 JSON 回應的支援。
傳回的意圖是依可能性的高低排列。 以下是 JSON 輸出的格式版本,其 topIntent 是具有信賴度分數為 0.97712576 (97.71%) 的 HomeAutomation.TurnOn。 第二個最有可能的意圖可能是具有信賴分數為 0.8985081 (84.31%) 的 HomeAutomation.TurnOff。
{
"kind": "ConversationResult",
"result": {
"query": "turn on the lights",
"prediction": {
"topIntent": "HomeAutomation.TurnOn",
"projectKind": "Conversation",
"intents": [
{
"category": "HomeAutomation.TurnOn",
"confidenceScore": 0.97712576
},
{
"category": "HomeAutomation.TurnOff",
"confidenceScore": 0.8431633
},
{
"category": "None",
"confidenceScore": 0.782861
}
],
"entities": [
{
"category": "HomeAutomation.DeviceType",
"text": "lights",
"offset": 12,
"length": 6,
"confidenceScore": 1,
"extraInformation": [
{
"extraInformationKind": "ListKey",
"key": "light"
}
]
}
]
}
}
}
備註
您現在已完成快速入門,以下是一些其他考量:
- 此範例使用
RecognizeOnceAsync作業來轉換最長 30 秒的語句,或直到偵測到無聲為止。 如需較長音訊的連續辨識相關資訊 (包括多語系交談),請參閱如何辨識語音。 - 若要從音訊檔案辨識語音,請使用
FromWavFileInput,而不是FromDefaultMicrophoneInput:using var audioConfig = AudioConfig.FromWavFileInput("YourAudioFile.wav"); - 針對 MP4 之類的壓縮音訊檔案,請安裝 GStreamer 並使用
PullAudioInputStream或PushAudioInputStream。 如需詳細資訊,請參閱如何使用壓縮的輸入音訊。
清除資源
您可以使用 Azure 入口網站或 Azure 命令列介面 (CLI) 來移除您所建立的語言和語音資源。
參考文件 | 套件 (NuGet) | GitHub 上的其他範例
在本快速入門中,您將使用語音和語言服務來辨識從麥克風擷取之音訊資料的意圖。 具體而言,您將使用語音服務來辨識語音,並使用交談語言理解 (CLU) 模型來辨識意圖。
重要
交談語言理解 (CLU) 適用於語音 SDK 版本 1.25 或更新的 C# 和 C++。
必要條件
- Azure 訂用帳戶。 您可以免費建立一個訂用帳戶。
- 在 Azure 入口網站上建立語言資源。
- 取得語言資源金鑰和端點。 部署語言資源之後,選取 [前往資源] 以檢視和管理金鑰。
- 在 Azure 入口網站上建立語音資源。
- 取得語音資源金鑰和區域。 部署語音資源之後,選取 [移至資源] 以檢視和管理索引鍵。
設定環境
語音 SDK 可以 NuGet 套件的形式取得,並且實作 .NET Standard 2.0。 您會在本指南的後續部分中安裝語音 SDK,但請先參閱 SDK 安裝指南,了解其他需求。
設定環境變數
此範例需要名為 LANGUAGE_KEY、LANGUAGE_ENDPOINT、SPEECH_KEY 和 SPEECH_REGION 的環境變數。
您的應用程式必須經過驗證,才能存取 Azure AI 服務資源。 本文說明如何使用環境變數來儲存您的認證。 然後,您可以從程式碼存取環境變數,以驗證您的應用程式。 針對實際執行環境,使用更安全的方法來儲存和存取您的認證。
重要
我們建議使用適用於 Azure 資源的受控識別搭配 Microsoft Entra ID 驗證,以避免使用在雲端執行的應用程式儲存認證。
如果您使用 API 金鑰,請將其安全地儲存在別處,例如 Azure Key Vault。 請勿在程式碼中直接包含 API 金鑰,且切勿公開將其張貼。
如需 AI 服務安全性的詳細資訊,請參閱驗證對 Azure AI 服務的要求。
若要設定環境變數,請開啟主控台視窗,然後遵循作業系統和開發環境的指示進行。
- 若要設定
LANGUAGE_KEY環境變數,請以您其中一個資源索引碼取代your-language-key。 - 若要設定
LANGUAGE_ENDPOINT環境變數,請以您的其中一個資源區域取代your-language-endpoint。 - 若要設定
SPEECH_KEY環境變數,請以您其中一個資源索引碼取代your-speech-key。 - 若要設定
SPEECH_REGION環境變數,請以您的其中一個資源區域取代your-speech-region。
setx LANGUAGE_KEY your-language-key
setx LANGUAGE_ENDPOINT your-language-endpoint
setx SPEECH_KEY your-speech-key
setx SPEECH_REGION your-speech-region
注意
如果您只需在目前執行中的主控台上存取環境變數,您可以使用 set 來設定環境變數,而不是 setx。
新增環境變數之後,您可能需要重新啟動任何需要讀取環境變數的執行中程式,包括主控台視窗。 例如,如果您使用 Visual Studio 做為編輯器,請在執行範例前重新啟動 Visual Studio。
建立交談語言理解專案
一旦您建立了語言資源,請在 Language Studio 中建立交談語言理解專案。 專案是一個工作區域,用於根據您的資料建置自訂 ML 模型。 您的專案只能由您和具有要使用的語言資源存取權的其他人員存取。
請前往 Language Studio,並以您的 Azure 帳戶登入。
建立交談語言理解專案
針對本快速入門,您可以下載此範例家庭自動化專案並將其匯入。 此專案能夠預測使用者輸入的意圖命令,例如開燈或關燈。
在 Language Studio 的 [理解問題和交談語言] 區段下,選取 [交談語言理解]。
這會帶您前往 [交談語言理解專案] 頁面。 在 [建立新專案] 按鈕旁,選取 [匯入]。
在出現的視窗中,上傳您想要匯入的 JSON 檔案。 確定您的檔案遵循支援的 JSON 格式。
一旦上傳完成,您就會登陸 [結構描述定義] 頁面。 針對本快速入門,已建置結構描述,且語句已加上意圖和實體的標籤。
定型您的模型
一般而言,在建立專案之後,您應該建置結構描述和標記語句。 針對本快速入門,我們已匯入備妥專案,其中具有已建置的結構描述和已標記的語句。
若要定型模型,則須啟動定型作業。 成功定型作業的輸出即是定型的模型。
若要從 Language Studio 內開始定型模型:
從左側功能表中選取 [定型模型]。
從頂端功能表中選取 [開始定型作業]。
選取 [定型新模型],然後在文字輸入框中輸入模型名稱。 否則,若要以在新資料上定型的模型取代現有的模型,請選取 [覆寫現有的模型],然後選取現有的模型。 覆寫定型的模型是無法復原的,但在您部署新模型之前,不會影響已部署的模型。
選取定型模式。 您可以選擇 [標準定型] 來加快定型速度,但僅適用於英文。 或者,您可以選擇支援其他語言和多語系專案的 [進階定型],但需要較長的定型時間。 深入瞭解模型定型。
選取資料分割方法。 您可以選擇 [從定型資料自動分割測試集],使用此方法時,系統會根據指定的百分比,將您的表達分割為定型集與測試集。 或者,您可以選擇 [使用手動分割定型和測試資料],但只有在表達已新增至測試集,且您標記表達時,才會啟用此選項。
選取 [定型] 按鈕。
選取清單中的定型作業識別碼。 隨即顯示窗格,您可以在其中檢查此作業的定型進度、作業狀態及其他詳細資料。
注意
- 只有成功完成的定型作業才會產生模型。
- 根據表達的計數,定型可能需要幾分鐘到幾小時的時間。
- 您一次只能執行一個定型作業。 除非執行中的作業完成,否則無法在同一個專案內啟動其他定型作業。
- 用來定型模型的機器學習會定期更新。 若要在先前的設定版本上定型,請從 [開始定型作業] 頁面選取 [選取這裡以變更],然後選擇舊版。
部署模型
定型模型後,您通常可檢閱其評估詳細資料。 在本快速入門中,您只需部署模型,並讓其可供您在 Language Studio 中試用,或者您可以呼叫預測 API。
若要從 Language Studio 內部署您的模型:
從左側功能表中,選取 [部署模型]。
選取 [新增部署] 以啟動 [新增部署] 精靈。
選取 [建立新的部署] 以建立新的部署,並從下方的下拉式清單中指派定型的模型。 否則,您可以選取 [覆寫現有的部署名稱],以有效地取代現有部署所使用的模型。
注意
覆寫現有的部署不需要變更預測 API 呼叫,但您取得的結果將會以新指派的模型為基礎。
從 [模型] 下拉式清單中選取定型的模型。
選取 [部署] 以啟動部署作業。
部署成功之後,在其旁邊會出現到期日。 部署到期表示部署的模型無法再用於預測,通常發生於訓練組態到期的十二個月後。
您將在下一節中使用專案名稱和部署名稱。
從麥克風辨識意圖
遵循下列步驟來建立新的主控台應用程式並安裝語音 SDK。
在 Visual Studio Community 2022 中建立名為
SpeechRecognition的新 C++ 主控台專案。使用 NuGet 套件管理員在新專案中安裝語音 SDK。
Install-Package Microsoft.CognitiveServices.Speech以下列程式碼取代
SpeechRecognition.cpp的內容:#include <iostream> #include <stdlib.h> #include <speechapi_cxx.h> using namespace Microsoft::CognitiveServices::Speech; using namespace Microsoft::CognitiveServices::Speech::Audio; using namespace Microsoft::CognitiveServices::Speech::Intent; std::string GetEnvironmentVariable(const char* name); int main() { // This example requires environment variables named: // "LANGUAGE_KEY", "LANGUAGE_ENDPOINT", "SPEECH_KEY", and "SPEECH_REGION" auto languageKey = GetEnvironmentVariable("LANGUAGE_KEY"); auto languageEndpoint = GetEnvironmentVariable("LANGUAGE_ENDPOINT"); auto speechKey = GetEnvironmentVariable("SPEECH_KEY"); auto speechRegion = GetEnvironmentVariable("SPEECH_REGION"); auto cluProjectName = "YourProjectNameGoesHere"; auto cluDeploymentName = "YourDeploymentNameGoesHere"; if ((size(languageKey) == 0) || (size(languageEndpoint) == 0) || (size(speechKey) == 0) || (size(speechRegion) == 0)) { std::cout << "Please set LANGUAGE_KEY, LANGUAGE_ENDPOINT, SPEECH_KEY, and SPEECH_REGION environment variables." << std::endl; return -1; } auto speechConfig = SpeechConfig::FromSubscription(speechKey, speechRegion); speechConfig->SetSpeechRecognitionLanguage("en-US"); auto audioConfig = AudioConfig::FromDefaultMicrophoneInput(); auto intentRecognizer = IntentRecognizer::FromConfig(speechConfig, audioConfig); std::vector<std::shared_ptr<LanguageUnderstandingModel>> models; auto cluModel = ConversationalLanguageUnderstandingModel::FromResource( languageKey, languageEndpoint, cluProjectName, cluDeploymentName); models.push_back(cluModel); intentRecognizer->ApplyLanguageModels(models); std::cout << "Speak into your microphone.\n"; auto result = intentRecognizer->RecognizeOnceAsync().get(); if (result->Reason == ResultReason::RecognizedIntent) { std::cout << "RECOGNIZED: Text=" << result->Text << std::endl; std::cout << " Intent Id: " << result->IntentId << std::endl; std::cout << " Intent Service JSON: " << result->Properties.GetProperty(PropertyId::LanguageUnderstandingServiceResponse_JsonResult) << std::endl; } else if (result->Reason == ResultReason::RecognizedSpeech) { std::cout << "RECOGNIZED: Text=" << result->Text << " (intent could not be recognized)" << std::endl; } else if (result->Reason == ResultReason::NoMatch) { std::cout << "NOMATCH: Speech could not be recognized." << std::endl; } else if (result->Reason == ResultReason::Canceled) { auto cancellation = CancellationDetails::FromResult(result); std::cout << "CANCELED: Reason=" << (int)cancellation->Reason << std::endl; if (cancellation->Reason == CancellationReason::Error) { std::cout << "CANCELED: ErrorCode=" << (int)cancellation->ErrorCode << std::endl; std::cout << "CANCELED: ErrorDetails=" << cancellation->ErrorDetails << std::endl; std::cout << "CANCELED: Did you update the subscription info?" << std::endl; } } } std::string GetEnvironmentVariable(const char* name) { #if defined(_MSC_VER) size_t requiredSize = 0; (void)getenv_s(&requiredSize, nullptr, 0, name); if (requiredSize == 0) { return ""; } auto buffer = std::make_unique<char[]>(requiredSize); (void)getenv_s(&requiredSize, buffer.get(), requiredSize, name); return buffer.get(); #else auto value = getenv(name); return value ? value : ""; #endif }在
SpeechRecognition.cpp中,將cluProjectName和cluDeploymentName變數設定為專案和部署的名稱。 如需如何建立 CLU 專案和部署的資訊,請參閱建立交談語言理解專案。若要變更語音辨識語言,請以另一種支援的語言取代
en-US。 例如,es-ES代表西班牙文 (西班牙)。 如果您未指定語言,則預設語言為en-US。 如需詳細了解如何識別所可能說出的多種語言之一,請參閱語言識別。
組建並執行新的主控台應用程式,以從麥克風啟動語音辨識。
重要
確保您已如上所述設定 LANGUAGE_KEY、LANGUAGE_ENDPOINT、SPEECH_KEY 和 SPEECH_REGION 環境變數。 如果您未設定這些變數,則範例將會失敗,並顯示錯誤訊息。
出現提示時,請用麥克風說話。 您說話的內容應該會以文字的形式輸出:
Speak into your microphone.
RECOGNIZED: Text=Turn on the lights.
Intent Id: HomeAutomation.TurnOn.
Language Understanding JSON: {"kind":"ConversationResult","result":{"query":"turn on the lights","prediction":{"topIntent":"HomeAutomation.TurnOn","projectKind":"Conversation","intents":[{"category":"HomeAutomation.TurnOn","confidenceScore":0.97712576},{"category":"HomeAutomation.TurnOff","confidenceScore":0.8431633},{"category":"None","confidenceScore":0.782861}],"entities":[{"category":"HomeAutomation.DeviceType","text":"lights","offset":12,"length":6,"confidenceScore":1,"extraInformation":[{"extraInformationKind":"ListKey","key":"light"}]}]}}}.
注意
在語音 SDK 版本 1.26 中透過 LanguageUnderstandingServiceResponse_JsonResult 屬性為 CLU 新增了 JSON 回應的支援。
傳回的意圖是依可能性的高低排列。 以下是 JSON 輸出的格式版本,其 topIntent 是具有信賴度分數為 0.97712576 (97.71%) 的 HomeAutomation.TurnOn。 第二個最有可能的意圖可能是具有信賴分數為 0.8985081 (84.31%) 的 HomeAutomation.TurnOff。
{
"kind": "ConversationResult",
"result": {
"query": "turn on the lights",
"prediction": {
"topIntent": "HomeAutomation.TurnOn",
"projectKind": "Conversation",
"intents": [
{
"category": "HomeAutomation.TurnOn",
"confidenceScore": 0.97712576
},
{
"category": "HomeAutomation.TurnOff",
"confidenceScore": 0.8431633
},
{
"category": "None",
"confidenceScore": 0.782861
}
],
"entities": [
{
"category": "HomeAutomation.DeviceType",
"text": "lights",
"offset": 12,
"length": 6,
"confidenceScore": 1,
"extraInformation": [
{
"extraInformationKind": "ListKey",
"key": "light"
}
]
}
]
}
}
}
備註
您現在已完成快速入門,以下是一些其他考量:
- 此範例使用
RecognizeOnceAsync作業來轉換最長 30 秒的語句,或直到偵測到無聲為止。 如需較長音訊的連續辨識相關資訊 (包括多語系交談),請參閱如何辨識語音。 - 若要從音訊檔案辨識語音,請使用
FromWavFileInput,而不是FromDefaultMicrophoneInput:auto audioInput = AudioConfig::FromWavFileInput("YourAudioFile.wav"); - 針對 MP4 之類的壓縮音訊檔案,請安裝 GStreamer 並使用
PullAudioInputStream或PushAudioInputStream。 如需詳細資訊,請參閱如何使用壓縮的輸入音訊。
清除資源
您可以使用 Azure 入口網站或 Azure 命令列介面 (CLI) 來移除您所建立的語言和語音資源。
適用於 Java 的語音 SDK 不支援使用交談語言理解 (CLU) 進行意圖辨識。 請選取其他程式設計語言,或本文開頭的 Java 參考和樣本連結。